
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
来自主题: AI资讯
9406 点击 2026-05-29 10:11
 搜索
搜索
GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。

7×24,AI也吃不消。
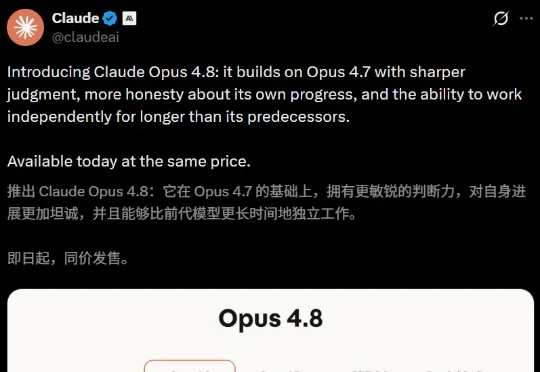
Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!

5 月 22 日,《一人之下》第 763 话更新,国漫圈这回吵得有点凶。
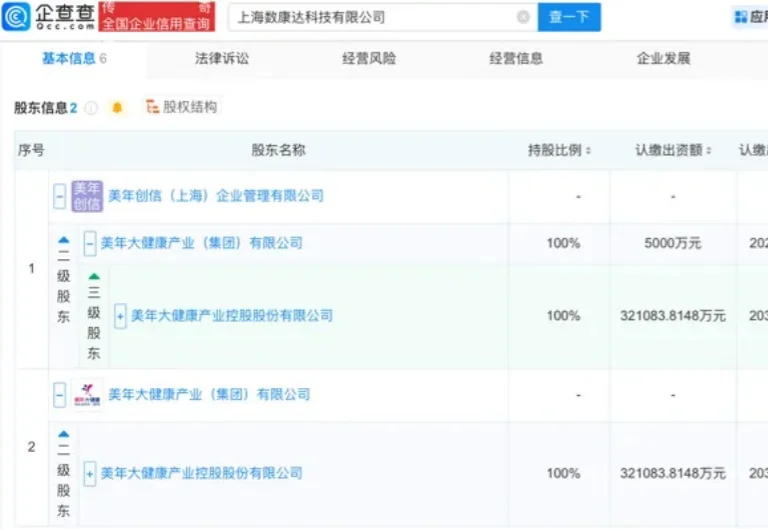
近日,企查查股权穿透显示,体检龙头美年健康(002044.SZ)间接全资持股了一家全新的AI企业上海数康达科技有限公司。
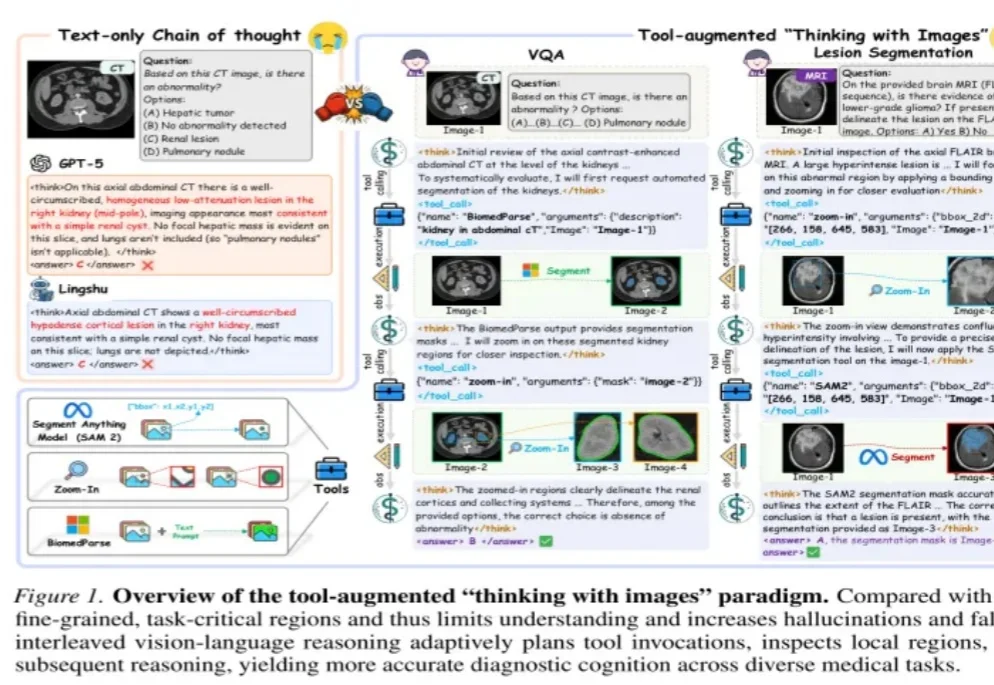
医学AI会写解释,但不代表它真的“看到”了关键证据。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

当一家年赚 500 亿美元的公司,决定把几乎同等规模的钱砸向 AI 基建,这件事本身就值得重新审视中国科技巨头的战略决心。

念念不忘,必有回响。这两天,如果你更新了Get笔记的最新版,应该已经发现,Get笔记改名了,新名字叫:得到大脑。