
关于Personal Agent:搓出次留70%的个人助手之后的一些反思
关于Personal Agent:搓出次留70%的个人助手之后的一些反思这半年我自己做了一款次留70%,月留存30%的个人助手产品,也把市场上所有和沾边的产品都上手用过一遍。想来写写这几个月对这个领域的一手的产品观察。第一部分是做产品的过程,第二部分是一手的观察和判断,按需取用~
来自主题: AI资讯
8692 点击 2026-06-01 10:31
 搜索
搜索
这半年我自己做了一款次留70%,月留存30%的个人助手产品,也把市场上所有和沾边的产品都上手用过一遍。想来写写这几个月对这个领域的一手的产品观察。第一部分是做产品的过程,第二部分是一手的观察和判断,按需取用~
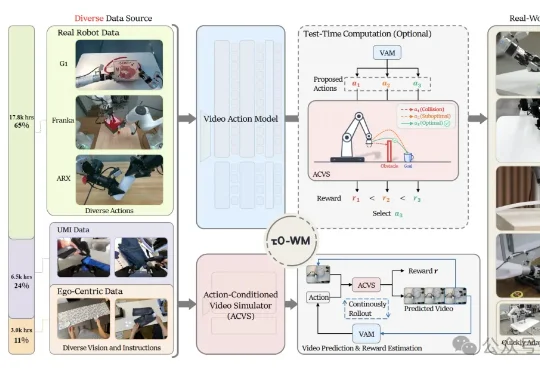
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

反转了反转了,过去我们给AI跑分,今天Claude开始反手给人类打分!它会通过11个指标来分析你和它的历史对话,判断你使用AI的水平高低。在AI眼里,你是高手还是萌新?

2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。

你此刻喝的干净水、用的电、看的病,1170亿人里绝大多数做梦都够不着。而算清这串概率的Opus 4.8,前天刚把GPT-5.5踢下全球第一的王座。
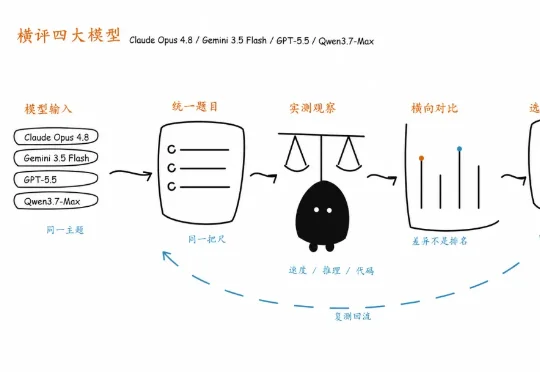
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。
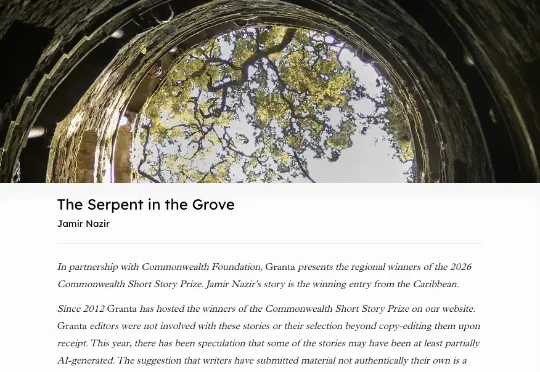
「精确而丰富地唤起感官」,「旋律般的声音」,这是顶级文学杂志 Granta 今年评选的年度作品获得到的称赞——直到它翻车之前。这篇叫《The Serpent in the Grove》的小说,是 2026 年英联邦短篇小说奖加勒比地区的获奖作品,从 7806 篇投稿中被选出。作者 Jamir Nazir,这是一个带有奇幻色彩的创作,写了一个关于朗姆酒、农夫与魔法树丛的故事。
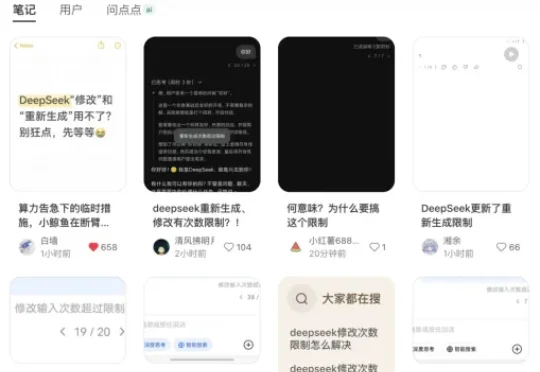
5月29日下午,不少网友发现,DeepSeek重新生成、修改有次数限制了。连续修改或重新生成几次后,页面会提示达到上限。有网友反馈,在普通对话中,重新生成3到6次后就会达到上限;而在专家模式下,可能只有3次机会。修改输入次数上限一般是6次。

继 Step 3.5 Flash 后,阶跃星辰最近又推出新一代高效率 Flash 开源模型 ——Step 3.7 Flash。该模型最大特点就是多(模)、快(速)、好(用)、省(钱)。总参数 196B,采用稀疏 MoE 架构,推理激活参数仅 11B,配备 1.88B ViT 视觉编码器,推理速度最高 400 TPS,支持 256K 上下文。

Anthropic最强通用模型Claude Opus 4.8正式发布,新模型基准测试全面超越Gemini 3.1 Pro、Opus 4.7,仅一项逊色于GPT-5.5,但其标准模式价格不变,快速模式价格仅为Opus 4.7的1/3。与此同时,Anthropic还官宣一笔650亿美元(约合人民币4406.94亿元)H轮巨额融资,投后估值冲上9650亿美元(约合人民币6.54万亿元)