小时候追的超兽武装,被 AI 一点点带到了现实里
小时候追的超兽武装,被 AI 一点点带到了现实里前两天我刷到一个工具的时候,第一反应其实不是拿真人照片试,也不是拿潮玩图试。
来自主题: AI产品测评
10770 点击 2026-04-14 14:58
 搜索
搜索
前两天我刷到一个工具的时候,第一反应其实不是拿真人照片试,也不是拿潮玩图试。

当你和 3D 数字人对话时,有没有遇到过这种诡异时刻:它的嘴在动,但表情依旧僵硬;手在挥舞,但和说话内容完全脱节;更糟的是,那种外表像真人但动作不自然的违和感,让人瞬间陷入 “恐怖谷”。
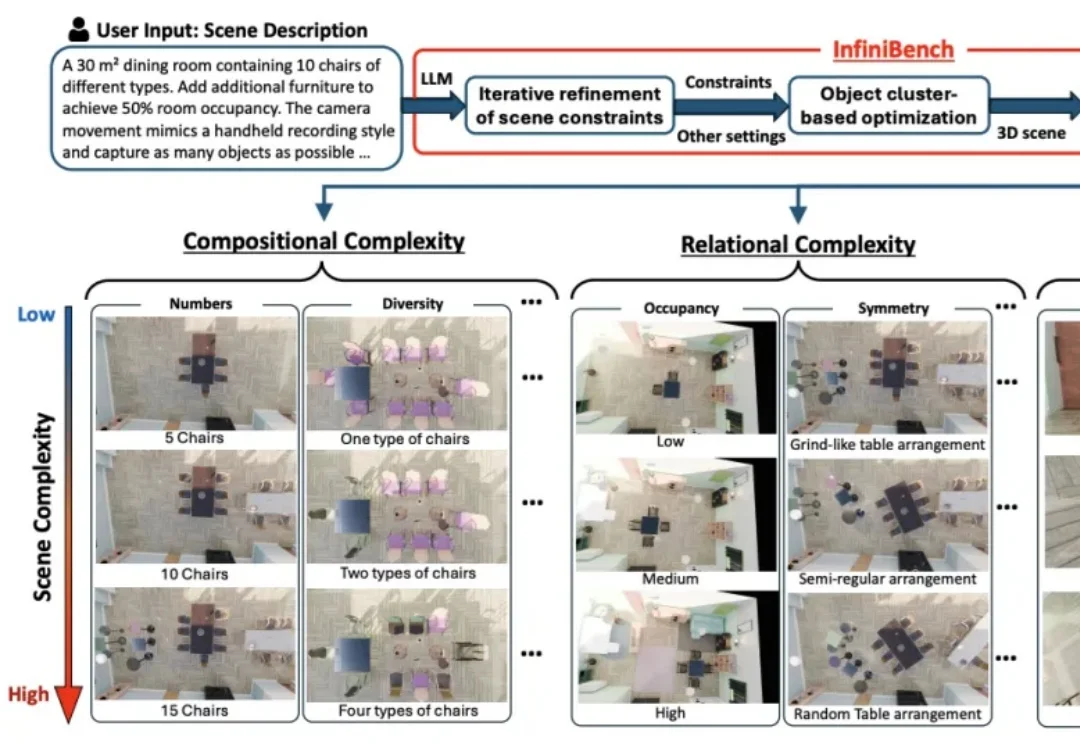
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。

我真的慕了。当我还在吭哧吭哧跟AI磨合写稿时,已经有人凭借AI生成的短片,美美到账100万了。一个是学3D动画的广告人,另一个是01年的生物学硕博连读生。以《牌子》这部7分多钟的视频为例,制作周期23天,在B站上线一周,收获1000多万次播放,80多万点赞,30多万投币。

今天,智谱正式发布 GLM-5V-Turbo。 看名字就知道,这次智谱新模型,视觉能力大大加强了!话不多说,这次小编直接开测,边测边为大家说一下对 GLM-5V-Turbo 的使用感受。
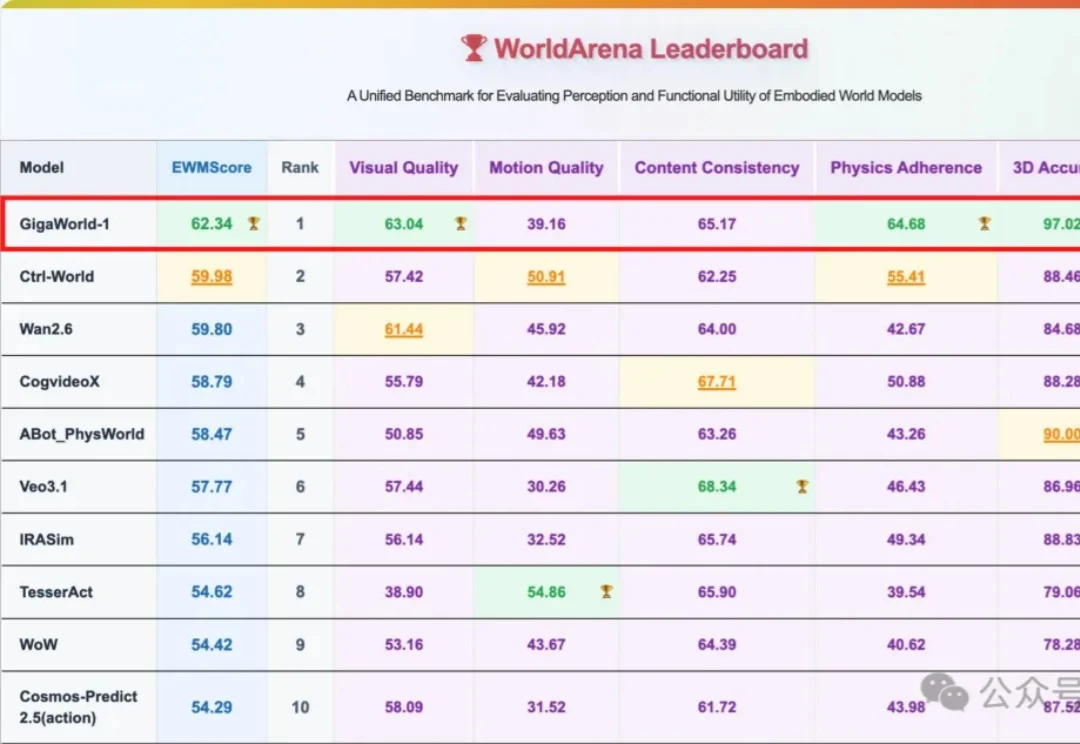
还得是咱国产世界模型牛!
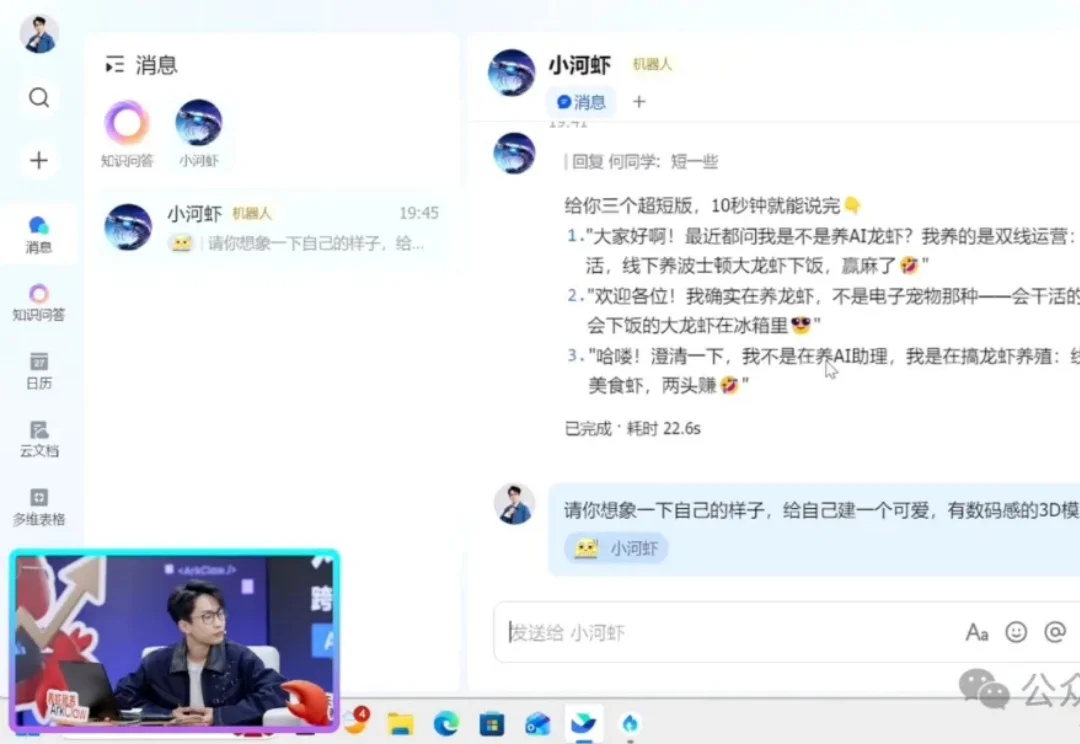
要论整活儿,还得是何同学。
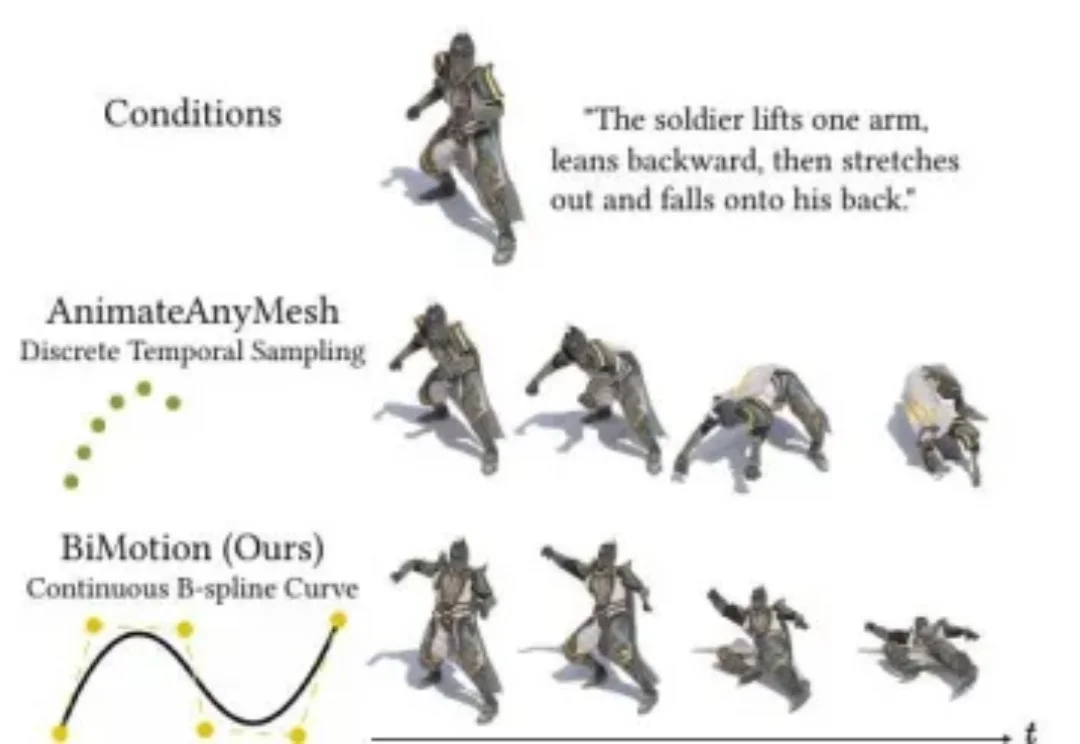
当你希望 AI 将 "士兵举起手臂,向后倾身,然后身体向前扑倒" 这段文字转化为一段 3D 角色动画,现有大多数方法给出的答案是:一段摇摇晃晃、语义残缺的短片段。这并非模型能力不足,问题的根源在于将运动表达为逐帧离散序列这一根本性的设计决策。
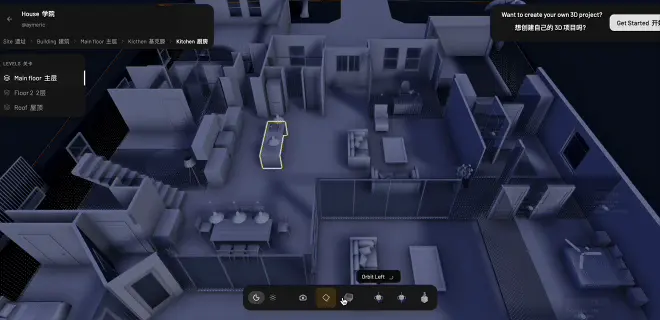
在GitHub上上线没几天就冲到5.4k stars的3D建筑编辑器开源项目——Pascal Editor。设计软件咱见的不少,但跑在浏览器里的还是有点新鲜,我帮大家浅浅总结了一下Pascal Editor的一些核心亮点:
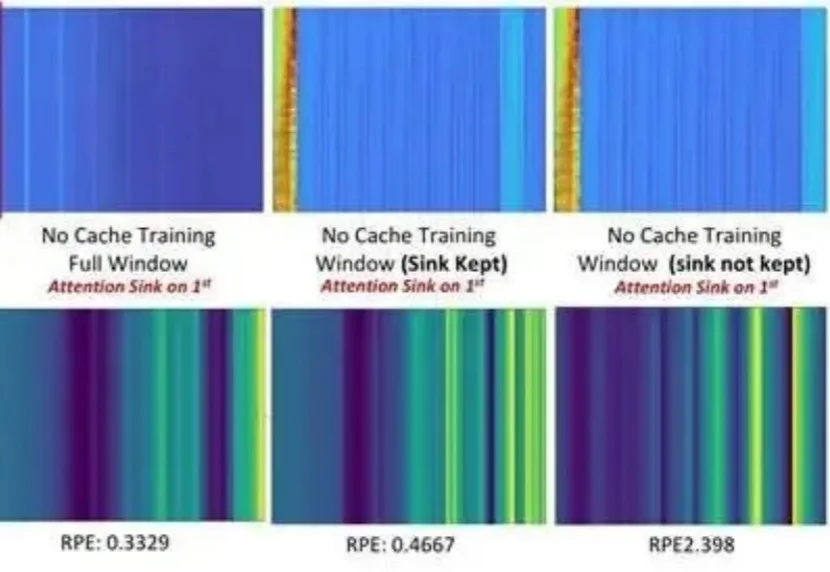
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?