
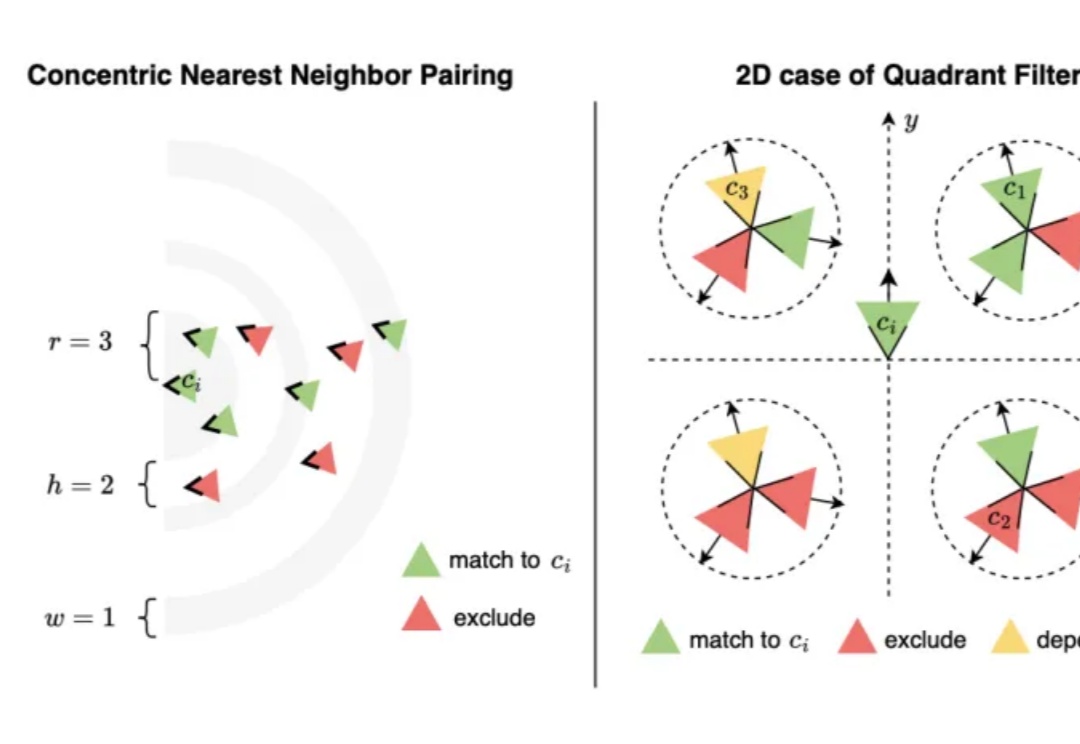
CVPR 2025高分论文:从照片重建3D矢量,告别模糊渲染,重建边缘更清晰
CVPR 2025高分论文:从照片重建3D矢量,告别模糊渲染,重建边缘更清晰三维高斯泼溅(3D Gaussian Splatting, 3DGS)技术基于高斯分布的概率模型叠加来表征场景,但其重建结果在几何和纹理边界处往往存在模糊问题。
来自主题: AI技术研报
11185 点击 2025-03-29 13:40
 搜索
搜索
三维高斯泼溅(3D Gaussian Splatting, 3DGS)技术基于高斯分布的概率模型叠加来表征场景,但其重建结果在几何和纹理边界处往往存在模糊问题。

「仅需一次前向推理,即可预测相机参数、深度图、点云与 3D 轨迹 ——VGGT 如何重新定义 3D 视觉?」

3 月 28 日,专注于构建通用 3D 大模型的 VAST 一口气开源了两个 3D 生成项目 ——TripoSG 和 TripoSF。前者是一款基础 3D 生成模型,在图像到 3D 生成任务上远超所有闭源模型;后者则是 VAST 新一代三维基础模型 TripoSF 能在所有闭源模型中同样取得 SOTA 的基础组件,用于高分辨率的三维重建和生成任务。

在Stable Diffusion当中,只需加入一个LoRA就能根据图像创建3D模型了?
从手机随手拍、汽车行车记录仪到无人机航拍,如何从海量无序二维图像快速生成高精度三维场景?

它名为 Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界首个此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。

3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
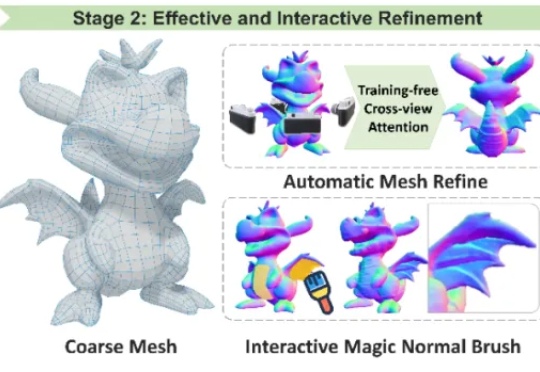
香港科技大学谭平教授团队在 CVPR 2025 发表两项三维生成技术框架,核心代码全部开源,助力三维生成技术的开放与进步。其中 Craftman3D 获得三个评委一致满分,并被全球多家知名企业如全球最大的多人在线游戏创作平台 Roblox, 腾讯混元 Hunyuan3D-2,XR 实验室的 XR-3DGen 和海外初创公司 CSM 的 3D 创作平台等重量级项目的引用与认可。

在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。