
CMU朱俊彦等上新LEGOGPT,一句话就能搭乐高,网友:复杂零件行不行?
CMU朱俊彦等上新LEGOGPT,一句话就能搭乐高,网友:复杂零件行不行?AI 不允许有人不会搭乐高。
来自主题: AI技术研报
10354 点击 2025-05-12 16:14
 搜索
搜索
AI 不允许有人不会搭乐高。

如何将一句简单的文字描述变成物理稳定的乐高模型?LegoGPT通过物理感知技术,确保98.8%的设计稳如磐石。

Sora、可灵等视频生成模型令人惊艳的性能表现使得创作者仅依靠文本输入就能够创作出高质量的视频内容。然而,我们常见的电影片段通常是由导演在一个场景中精心布置多个目标的运动、摄像机拍摄角度后再剪辑而成的。例如,在拍摄赛车追逐的场景时,镜头通常跟随赛车运动,并通过扣人心弦的超车时刻来展示赛事的白热化。
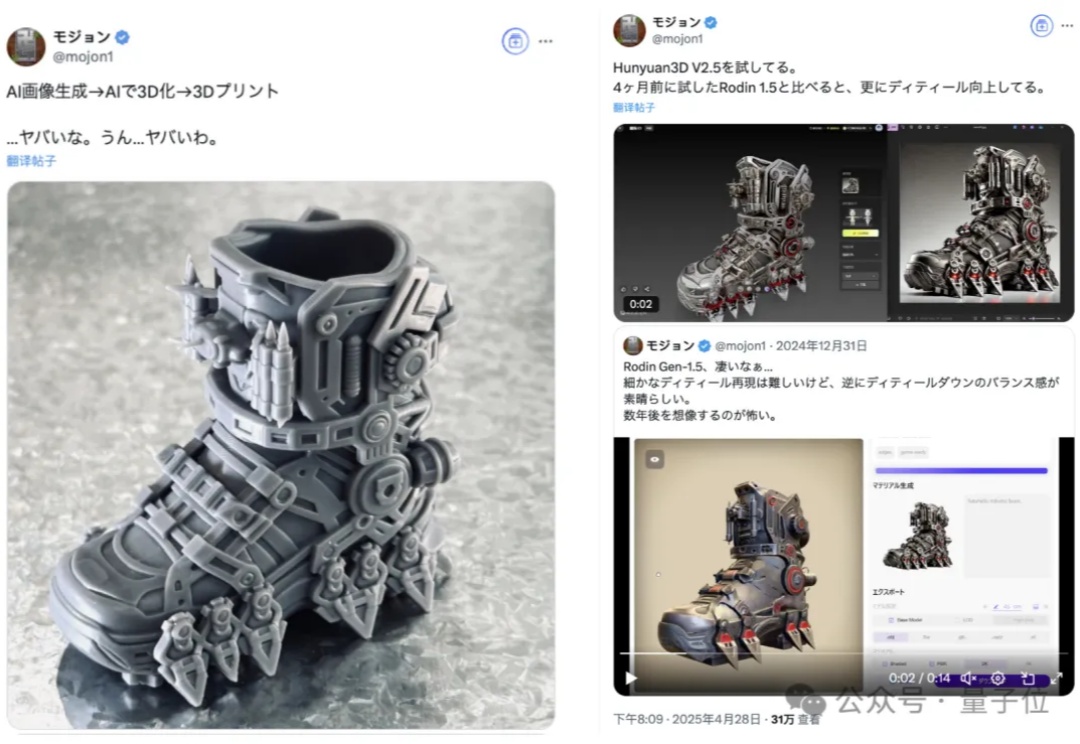
鹅厂最新的3D生成模型,狠狠地圈了一波粉,甚至有人拿它来创作小游戏动画了。
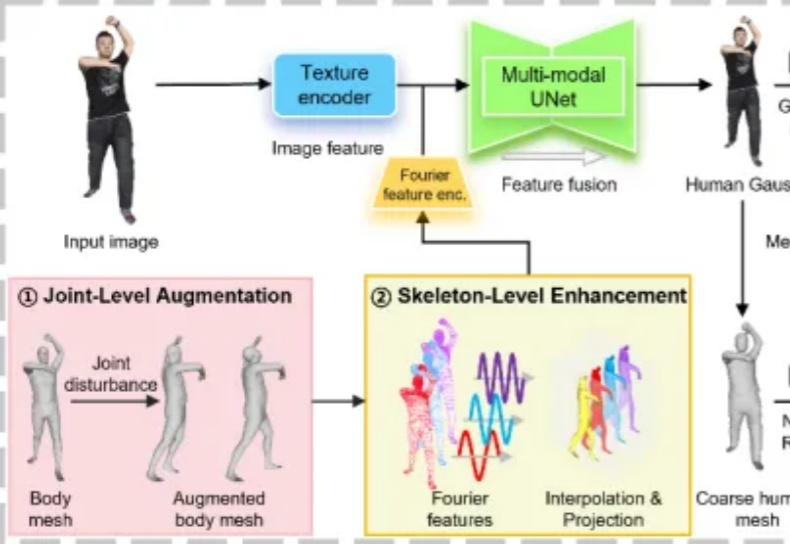
从人体单图变身高保真3D模型,不知道伤害了多少程序猿头发的行业难题,竟然被港科广团队一招破解了!

近期,美国FDA正式宣布计划逐步取消在单抗疗法等药物研发中对动物实验的强制性要求。

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。
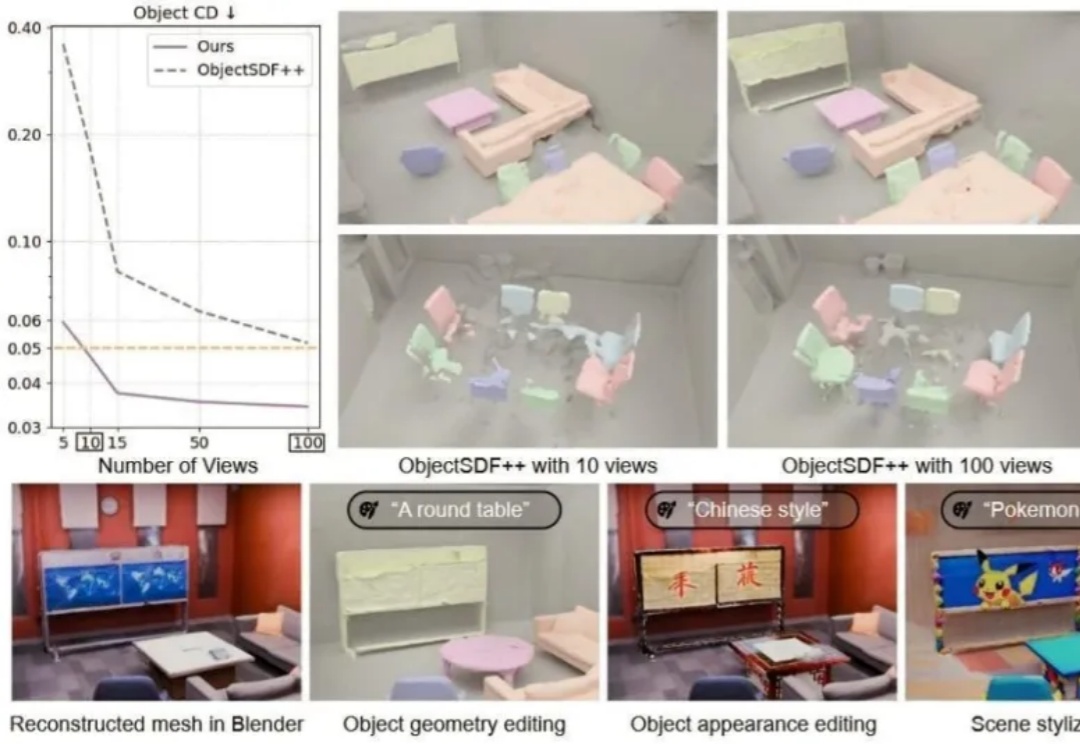
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?

用户仅仅通过输入文字,就能生成一个3D世界。

随着3D Gaussian Splatting(3DGS)成为新一代高效三维建模技术,它的自适应特性却悄然埋下了安全隐患。