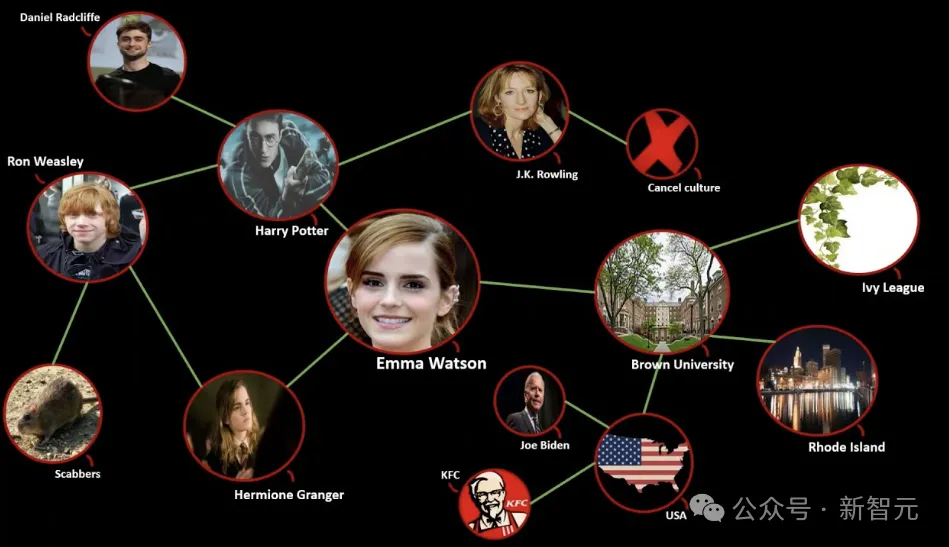
KG+LM超越传统架构!海德堡提出全新图语言模型GLM | ACL 2024
KG+LM超越传统架构!海德堡提出全新图语言模型GLM | ACL 2024近日,来自海德堡大学的研究人员推出了图语言模型 (GLM),将语言模型的语言能力和知识图谱的结构化知识,统一到了同一种模型之中。
来自主题: AI技术研报
9772 点击 2024-09-20 20:01
 搜索
搜索
近日,来自海德堡大学的研究人员推出了图语言模型 (GLM),将语言模型的语言能力和知识图谱的结构化知识,统一到了同一种模型之中。

随OpenAI爆火的CoT,已经引发了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT可以让Transformer推理无极限。但随即他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确路径吗?

据TechCrunch报道,Fal.ai 是一个专注于开发者的人工智能生成音频、视频和图像的平台,今天透露它从包括a16z、Black Forest Labs联合创始人罗宾·隆巴赫和 Perplexity 首席执行官阿拉文德·斯里尼瓦斯在内的投资者那里筹集了 2300 万美元的资金。

科技企业家Elad Gil强调,将AI作为产品核心需要时间,初期产品往往只是基础功能,而真正的价值在于深入理解AI技术并将其融入产品体验的核心。

在这个科技不断进步的时代,我们终将迎来“与机器人共存”的未来。你认为,未来会是人机和平共处,还是《终结者》式未来?

实话说,我一直没想明白阿里为什么会在大模型这个赛道,成为中国版的Meta。

在 2024 云栖大会上,阶跃星辰创始人姜大昕、月之暗面Kimi创始人杨植麟、生数科技首席科学家朱军与极客公园创始人张鹏一起,探讨了各自眼中 AI 技术发展的现状,推演未来 18 个月,大模型行业会发生什么。 在这场圆桌里,他们重点聊了:

APP内“智能体”数量大增,如通义已经超过14000个、讯飞星火超过11000个、豆包超过5000个
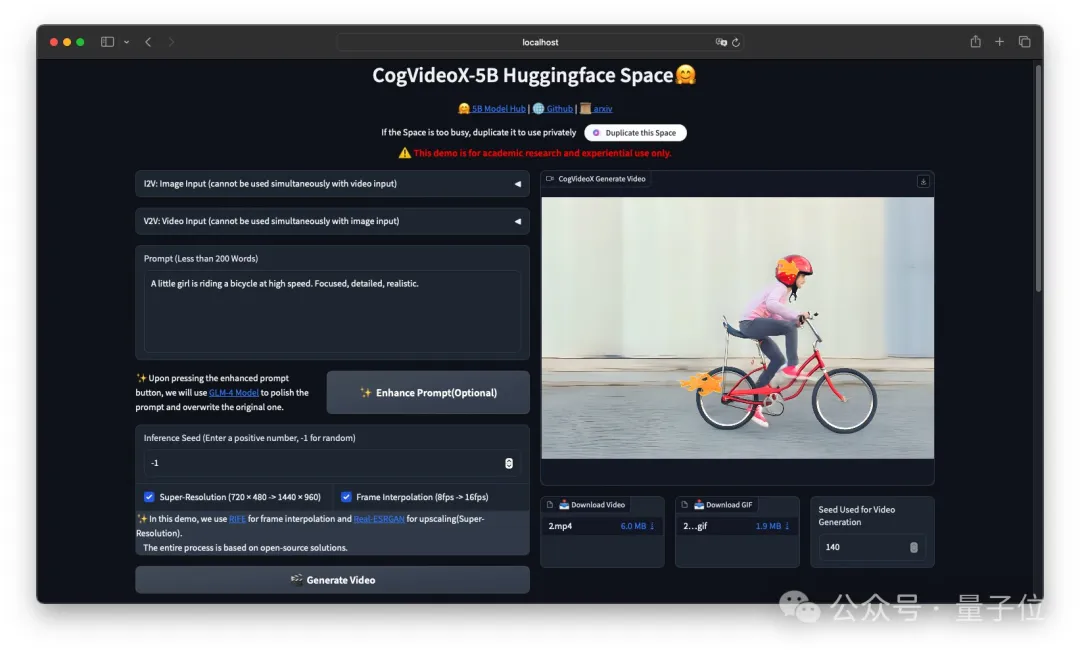
刚刚,智谱把清影背后的图生视频模型CogVideoX-5B-I2V给开源了!(在线可玩) 一起开源的还有它的标注模型cogvlm2-llama3-caption。
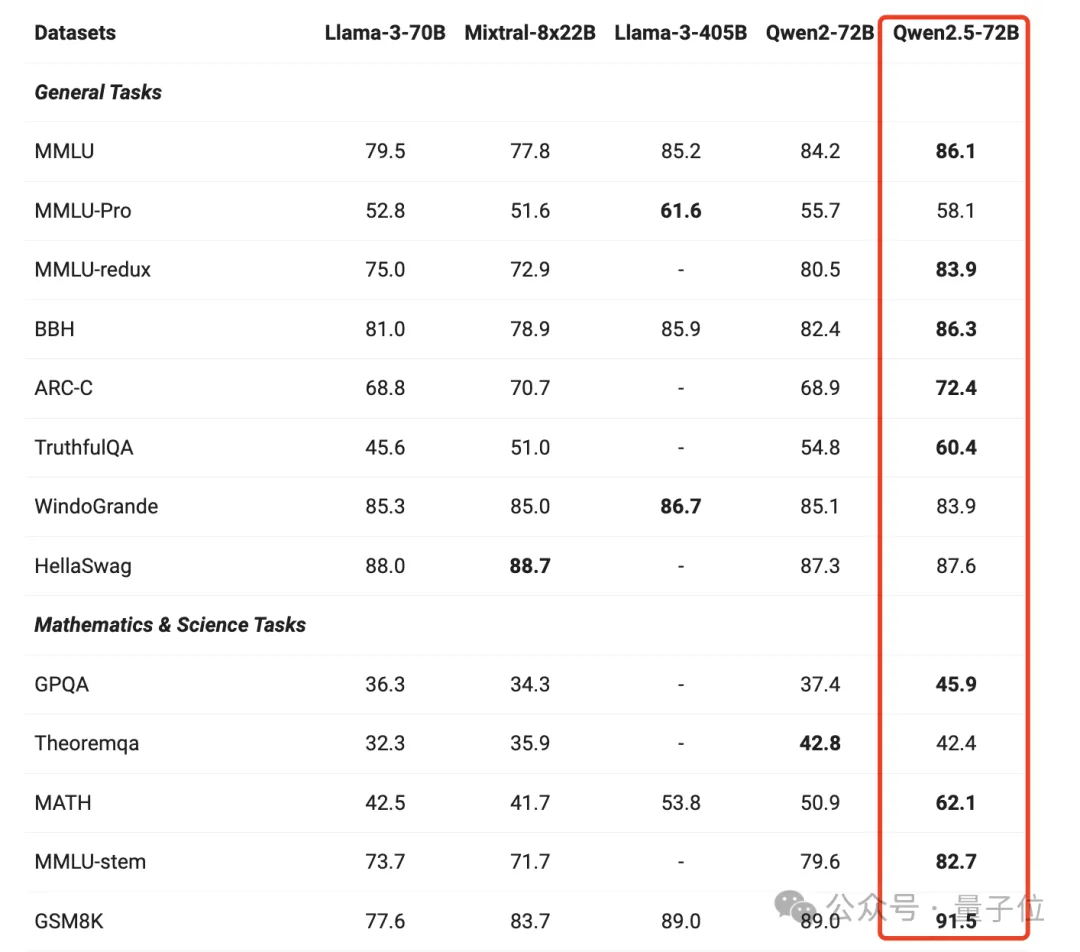
击败LIama3!Qwen2.5登上全球开源王座。 而后者仅以五分之一的参数规模,就在多任务中超越LIama3 405B。