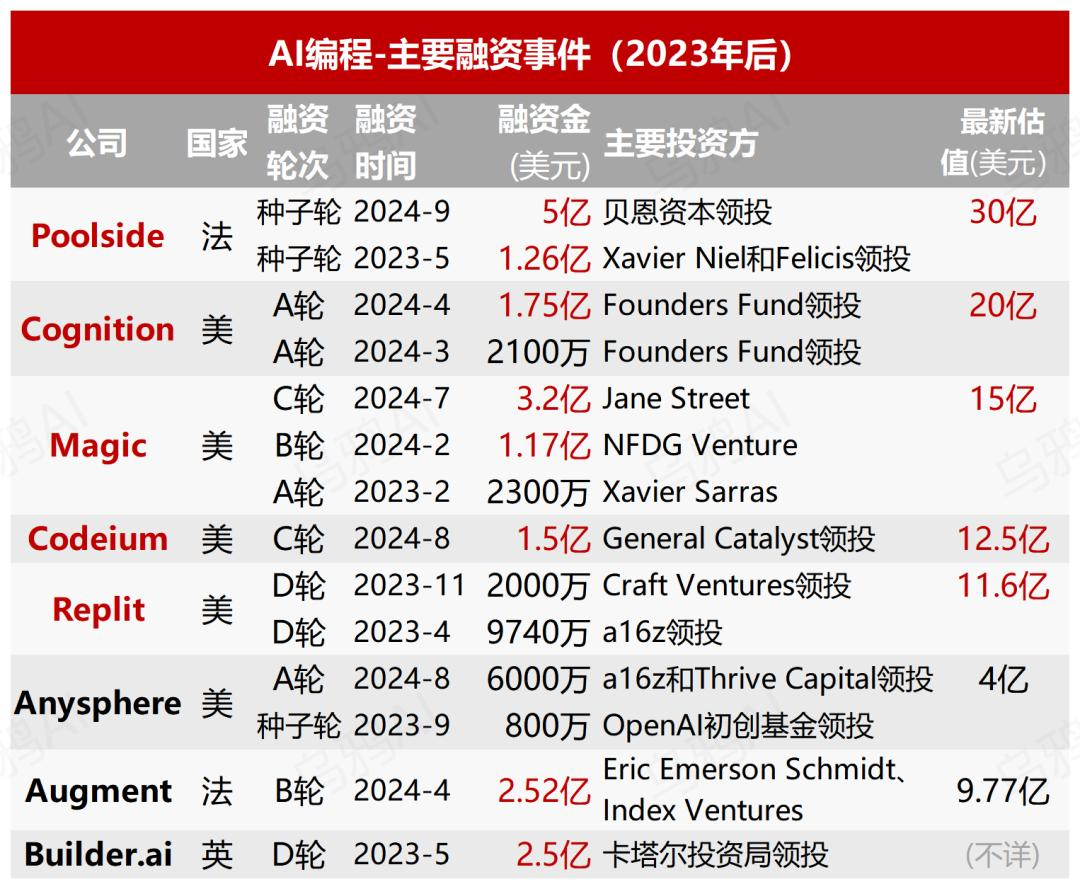
8家公司融资22亿美元,AI编程成Agent最确定赛道
8家公司融资22亿美元,AI编程成Agent最确定赛道杀手级应用终于出现了。
来自主题: AI资讯
5436 点击 2024-09-23 10:13
 搜索
搜索
杀手级应用终于出现了。

有经销商称已无法下单英伟达H20芯片,有终端厂商称部分国内经销商不再接H20订单。H20或将遭停售的传闻早已在业内传开,其命运走向受关注。业内多方反馈称,H20年内到货已超出全年预期。

如果AI能够更好地完成一切,最有可能出现的问题是我们如何找到生命的意义,这或许是更大的挑战。 在掌声与欢呼声中,马斯克登场了。
o1诞生,对于OpenAI团队来说,是最具革命性的时刻。在22分钟完整版采访视频中,他们分享了自己对新模型的思考,以及背后的开发故事。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。

2021年,帕特·基辛格 (Pat Gelsinger) 刚成为英特尔史上第八位CEO。他上任后为公司提出的第一个目标是,英特尔要在所竞争的每一个业务领域都成为引领者。

刚刚结束的第48届ICPC全球总决赛上,北大获得第一,清华获得第三,北交大获得第七,浙大获得第十。夺冠的三位北大信科学子,都来自图灵班,并且高中来自杭二中,师从同一位教练。

被Zoom创始人袁征誉为“SaaS行业的超级碗”的一年一度盛会——SaaStr Annual 2024,于9月11日至12日在旧金山盛大举行。

9月20日的深圳科创学院,地瓜机器人在开发者日上发布了全新的产品:面向机器人市场的旭日5智能计算芯片、最新的RDK智能机器人开发者套件系列产品、以及相关的机器人开发工具和基础设施。

相比第一代, 延迟降低40%,成本还降低30%。