
Agent学会自己「长」Skill了!从失败里长出经验,比人类写的更好用|ICML 2026
Agent学会自己「长」Skill了!从失败里长出经验,比人类写的更好用|ICML 2026过去一年,Agent学会了两件事:会用工具、会调用Skill。
来自主题: AI技术研报
9246 点击 2026-05-19 10:00
 搜索
搜索
过去一年,Agent学会了两件事:会用工具、会调用Skill。

扩散模型杀进了文本生成的地盘,而巨头们为了抢它,已经打起来了。

20美元Token费,2小时运行,AI智能体没问任何人,自主翻遍互联网,选中麦肯锡,把它的「数字大脑」Lilli彻底攻破。4650万条战略聊天记录、72万份核心文件、95条系统提示词……全部明文读写权限到手。AI震惊地说出了「WOW!」

2026 年 5 月,深度机智(DeepCybo)迎来成立一周年。

Mechanize 发布了一项硬核测试:给前沿 AI coding agents 24 小时,用 Rust 从零写一个完整的 Game Boy Advance 模拟器,再和顶级开源模拟器 Mesen2 逐帧对比打分。
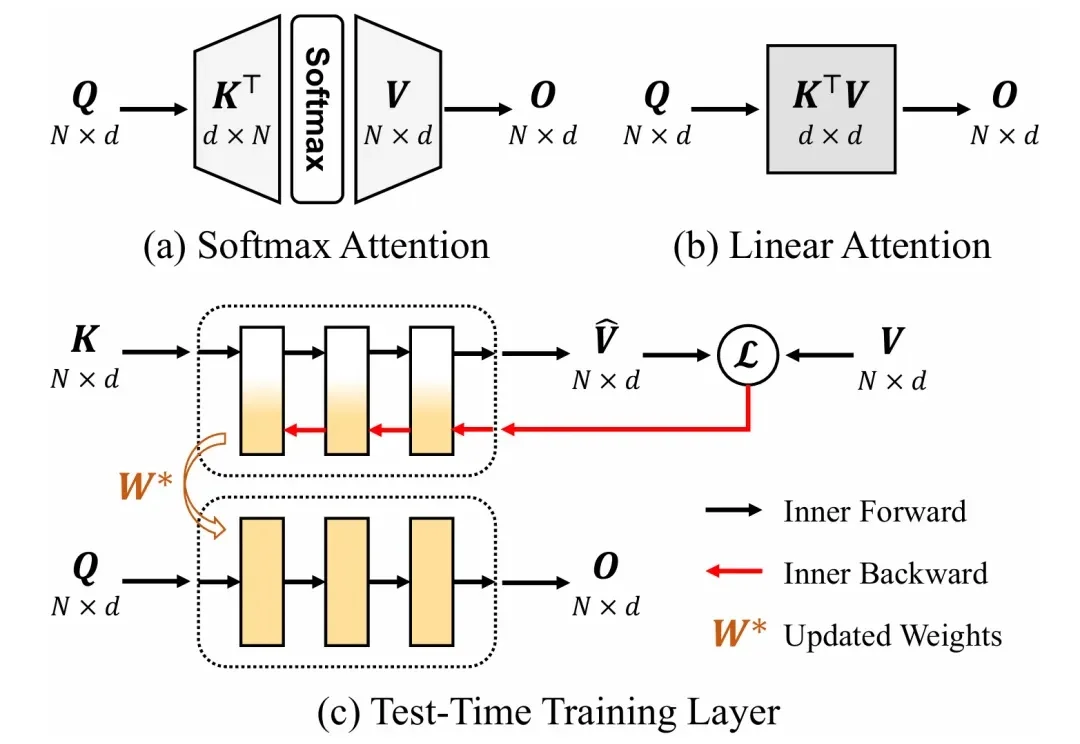
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
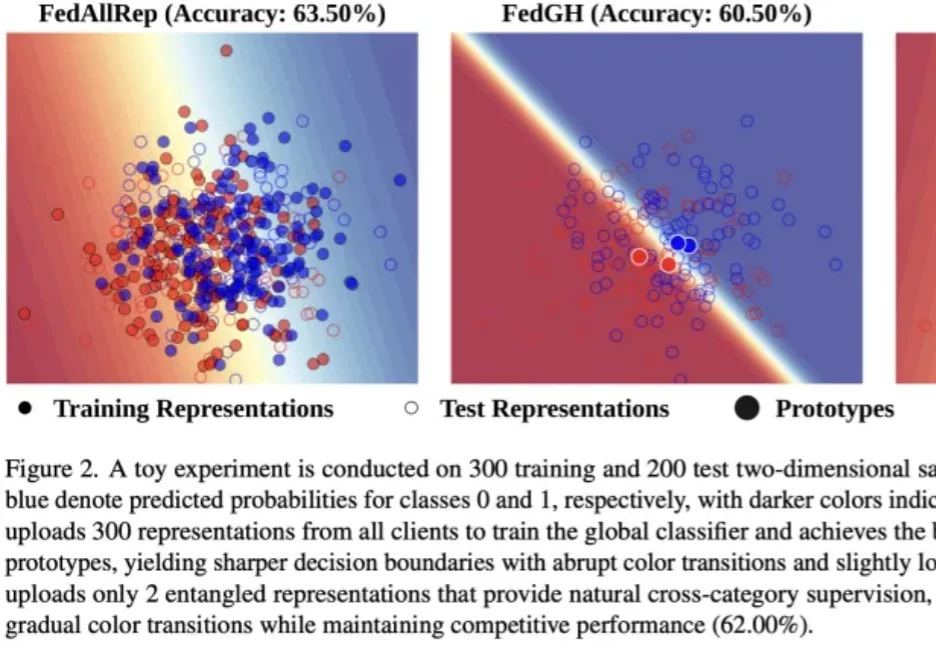
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
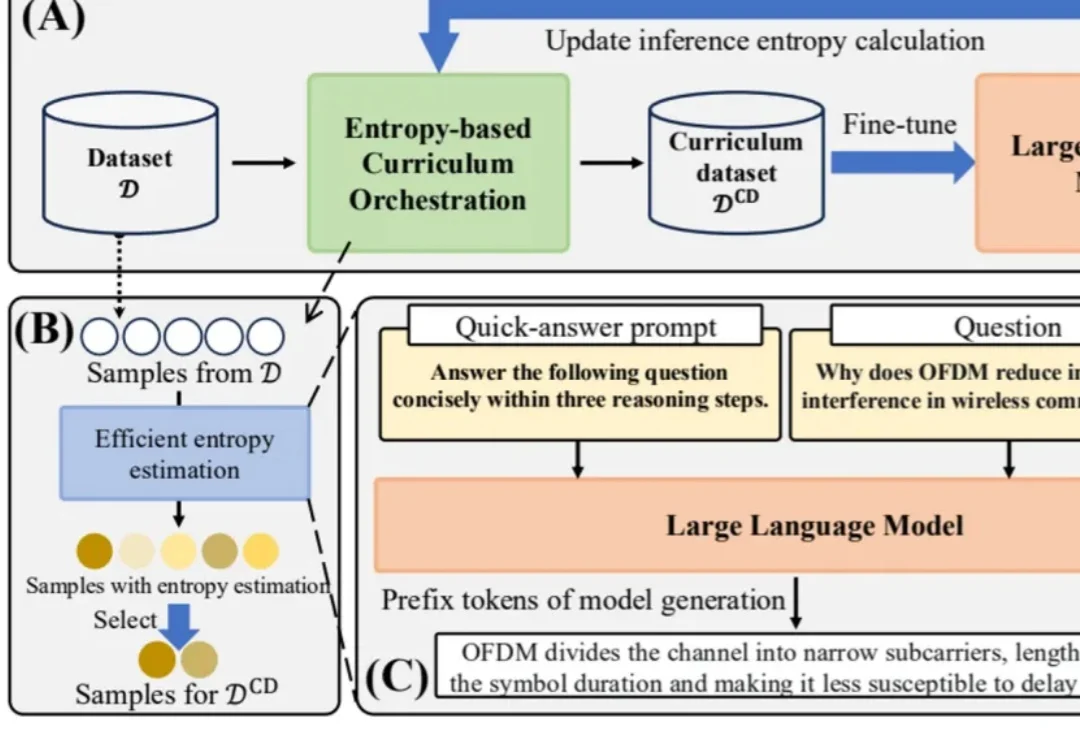
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
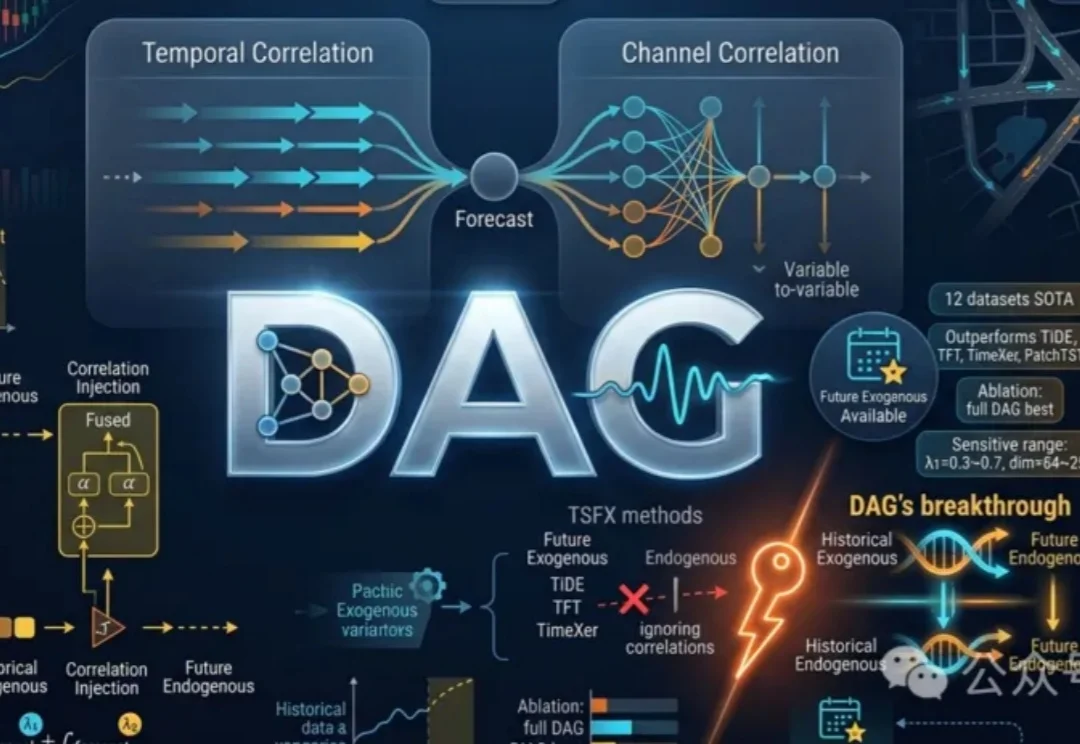
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
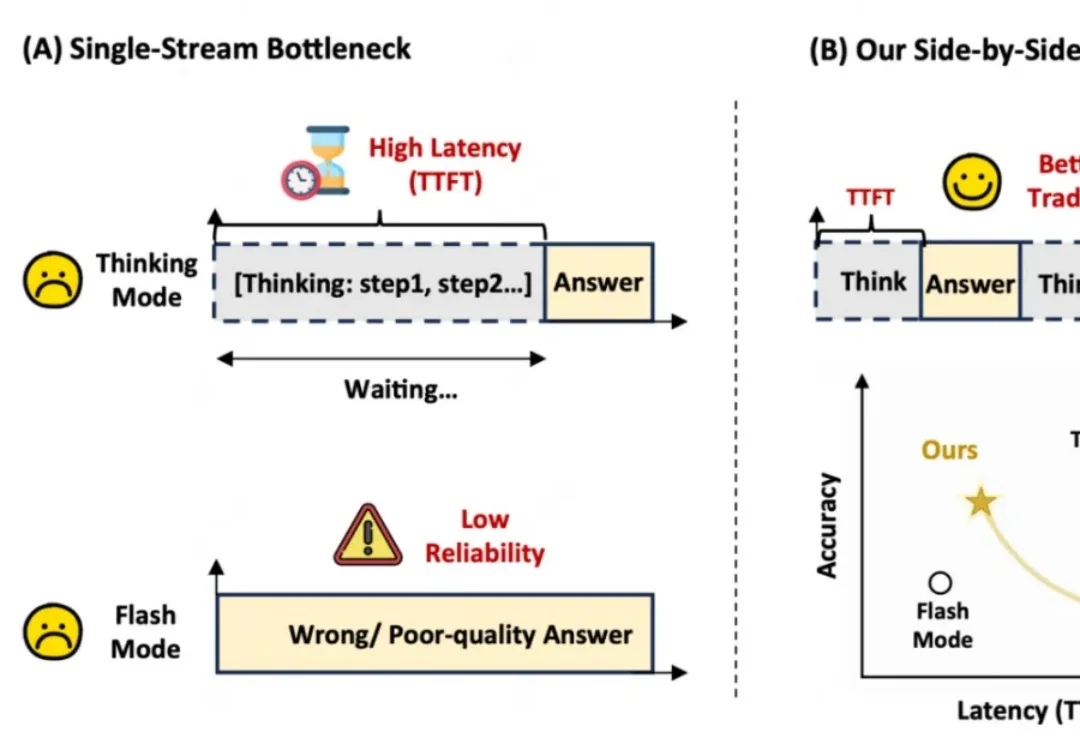
用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。