
星源智发布全球首个具身交互世界模型ω-EVA
星源智发布全球首个具身交互世界模型ω-EVA刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。
来自主题: AI资讯
8812 点击 2026-06-17 20:39
 搜索
搜索
刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。
GlobalGPT 是一款很典型的 AI 套壳产品,一份订阅访问市面上几乎所有主流 AI 模型,目前全球累计用户超过 300 万,ARR 做到 1000 万美金。创始人李焕之,律师出身,2022 年开始连续创业,经历了 LegalDAO(Web3 法律社区)、LegalNow(AI 法律产品)的两次pivot后,在 2024 年初团队现金流只剩 1 个月时做出了 GlobalGPT。
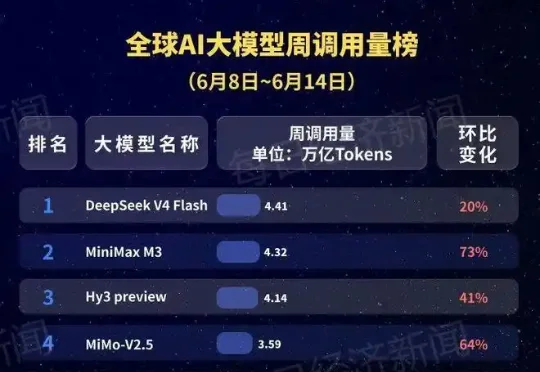
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
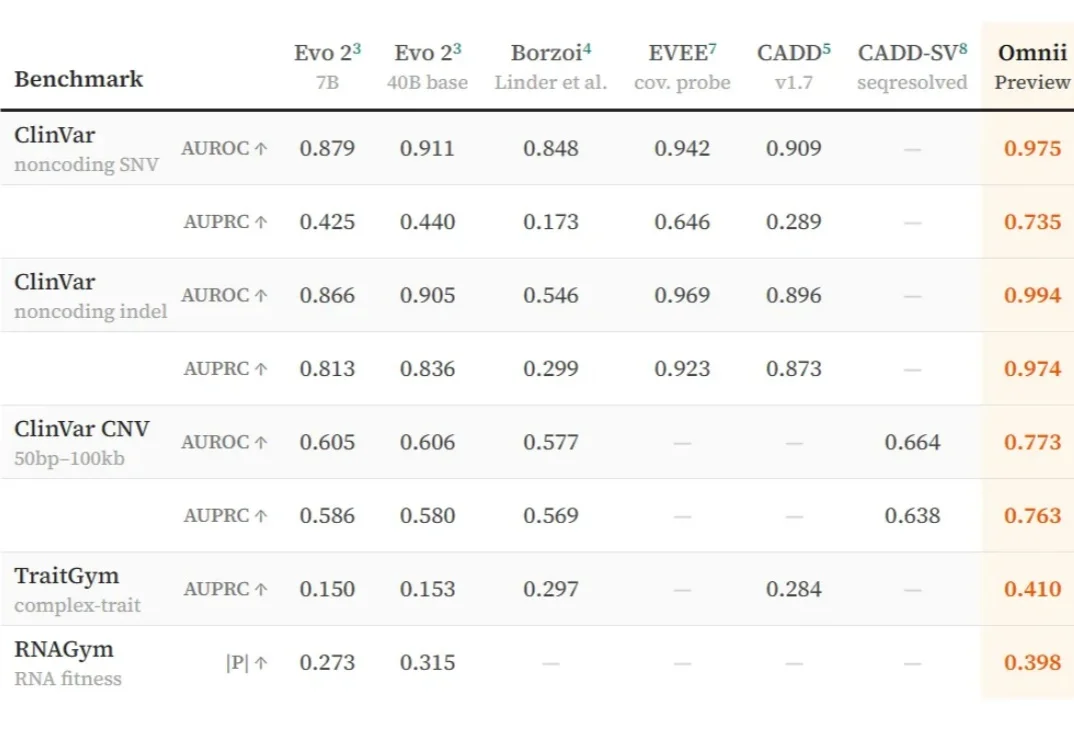
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!
前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」

AI 智件获悉,第三方数据基础设施公司「刻行时空」(下称“刻行”)已于今年1月完成新一轮融资,投资方包括穹彻智能、乐聚智能、线性资本。 刻行成立于2022年,是一家面向具身智能的第三方数据基础设施公司,聚焦时空多模态数据的生产、治理、评估与合规交付。
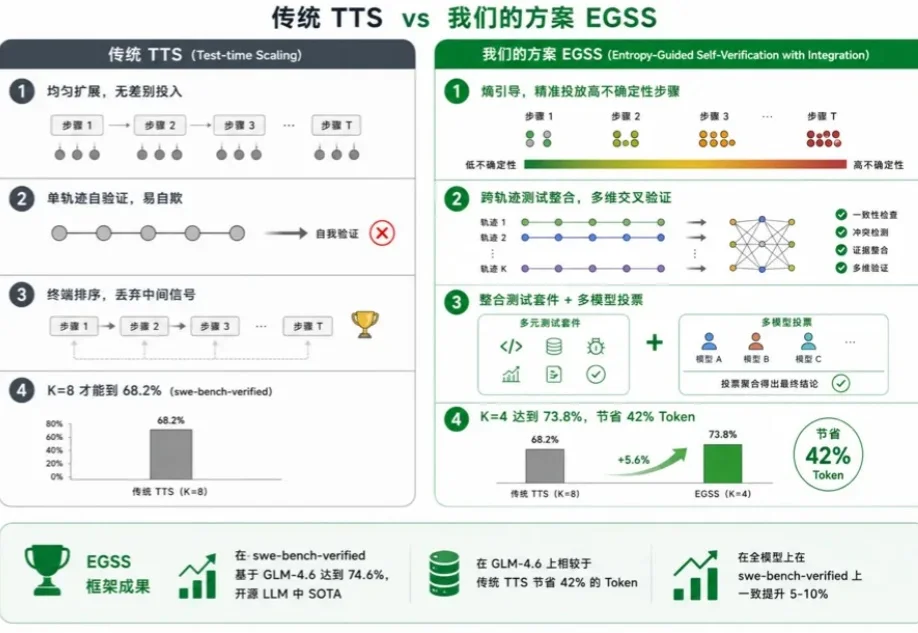
更聪明的计算远比更多的计算更有效。
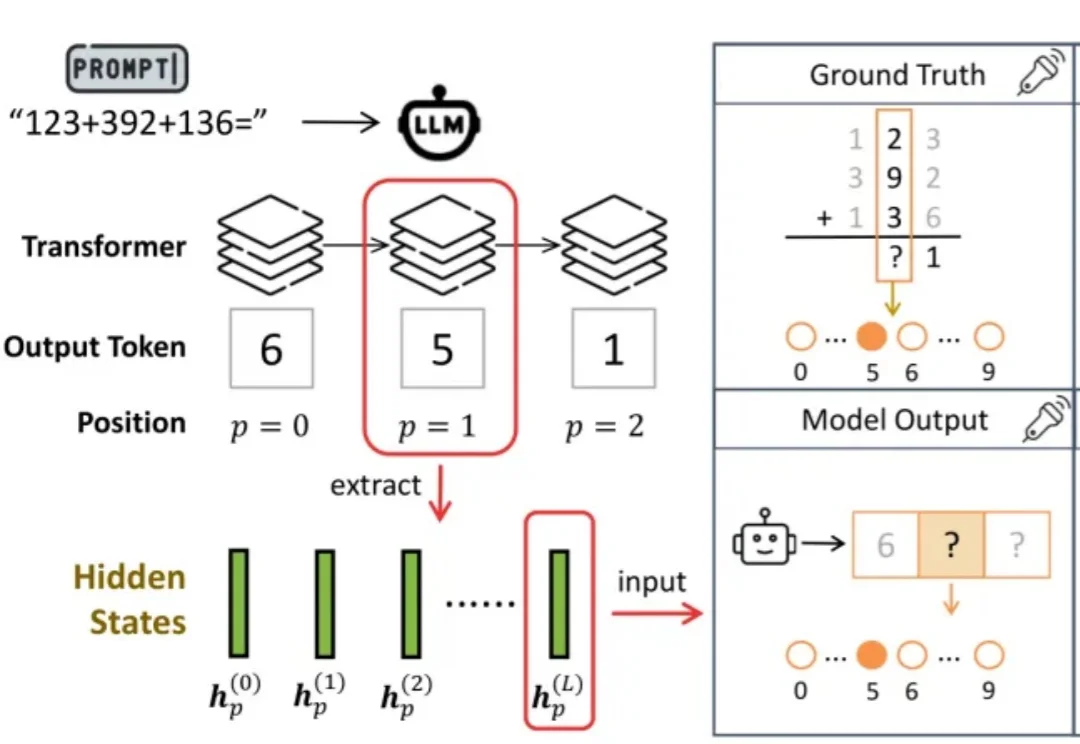
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。