# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
走在风口浪尖,拥抱最新的技术。

“世界模型”并不是新概念。但在2026 年,具身智能的“泛化瓶颈”,直接把“世界模型”推向了风口。
大洋彼岸,李飞飞的 World Labs 估值突破 50 亿美元,杨立昆的 AMI Labs 获超 10 亿美元种子轮融资,迅速推高了“世界模型”赛道的热度。资本加速涌来。世界模型及相关赛道国内已有超 33 家企业完成融资,累计吸金超 260 亿人民币。
与此同时,巨头们也在提速。阿里的 Qwen-RobotWorld、腾讯的 HY-World、字节的 Seed3D 迅速更迭;华为虽不常公开提及"世界模型",却已将盘古大模型定位为具身与自动驾驶的"训练底座"。
大家心照不宣:谁能让 AI 真正理解物理世界的运行规律,谁就能率先占领AGI时代的入口。
今天,我们把目光投向更基础的科研场域——寻找技术发轫的原点。在实验室里,谁在定义世界模型最底层的架构创新?谁在为这个赛道提供真正的原发性创新?
最近,我们和 FaceMind 创始人 Adam 陆弘远聊了聊。他是一名 95 后博士,热衷于寻找世界模型架构层的根本性突破。读博第 6 个月,他就拿到了 EACL Best Paper Award,他还以自己的名字定义了一个理论——Adams Law。
FaceMind 刚刚 closed 一笔数千万人民币的融资,老股东 360 集团持续投资。这次对话中,我们重点聊了:这一波世界模型的热潮中,Adam 看到的机会是什么?他的最新论文《Looped World Models》带来了哪些技术创新?这个仅有20人的 Neolab 团队,想要如何挤进来、活下去并且持续定义未来?
下面,是十字路口与 FaceMind 创始人 Adam 陆弘远的完整对话实录。
首先用几个快问快答,让大家快速认识你。
🚥 十字路口
年龄?
🧑🏻💻 Adam 陆弘远
95后
🚥 十字路口
毕业院校?
🧑🏻💻 Adam 陆弘远
帝国理工学院 本科(计算机科学专业-Computing)
爱丁堡大学 硕士(人工智能方向-Informatics)
香港中文大学 博士(世界模型方向-System Engineering and Engineering Managment)
🚥 十字路口
MBTI 和星座?
🧑🏻💻 Adam 陆弘远
ESTJ & 天蝎座
🚥 十字路口
一句话介绍现在的公司和产品?
🧑🏻💻 Adam 陆弘远
FaceMind Research Asia,我们是通用世界模型的 Neolab。
🚥 十字路口
融资情况?
🧑🏻💻 Adam 陆弘远
正在进行数千万美金资金需求的融资,估值数亿美元。
🚥 十字路口
团队规模?
🧑🏻💻 Adam 陆弘远
约20人
🚥 十字路口
创业前在做什么?
🧑🏻💻 Adam 陆弘远
世界模型/空间智能/Pre-training 方向的 researcher。2022-2023 年,在微软做预训练;再之前在阿里做推荐、在亚马逊做算法工程。

🚥 十字路口
你自称“宅男”,从一个热爱二次元的宅男博士,到决定创办一家 AI 公司,这个转变是怎么发生的?明明可以在学术界拿着体面的教职,为什么选择创业?
🧑🏻💻 Adam 陆弘远
为了做更有意义的事,去寻找斜率更高的“人生强化学习指标”。
当我写了几篇文章的时候,我才发现,有很多是学界通常不会写在纸面上的东西。比如,没有人会告诉你,PersonaChat 的数据集是 faked 的,而不是实际落地的数据集;也没有人会告诉你 AUC 上升了,CTR 也不一定会上升。优化他们往往是间接的。
我觉得去工业界有可能是一个更直接的手段。而且,创业能带来最高的斜率,因为身为一个 fresh PhD 能做的事情有限,资本是最好的助力。
还有一个小故事。我刚刚想创业的时候,有人找我去当 CTO,还给了我不少股份,后来我拒绝了,是因为我爸爸和我说“你还很差,他比你优秀,你应该好好学学别人”。我觉得他说的不对,我应该是 CEO 一把手。
其实,我后来发现我们都想错了:一个人应该在他合适的位置,无论是去做 CEO 或者 CTO。
CEO 股份更多但是他也承担了更多的责任和义务。但我更合适当 CEO。
🚥 十字路口
过往什么事情,让你觉得自己更适合当 CEO?
🧑🏻💻 Adam 陆弘远
应该说我更适合当一家高科技公司的 founder。
在科研阶段,我确实感觉到自己有优秀的科研直觉。我记得第一篇论文,Reviewer 当时的评价是“can change the community”,算是一个佐证吧。
我觉得 CEO 是一个比较复杂的职能,更高的股权比例带来的是更多的实缴责任和法律责任。
一般来讲,创业公司 CEO,是最不太可能、最难会离开那家公司的角色。我觉得,高科技公司 CEO 一般是“小天才”和年轻学者,也有一些更年长的资深学者,至少应该是博士学位起步。
🚥 十字路口
为什么取名叫 FaceMind(脸谱心智)?
🧑🏻💻 Adam 陆弘远
Face 是 Facebook 的 Face,Mind 是 DeepMind 的 Mind。
🚥 十字路口
2023 年,你读博第 6 个月就拿到了 EACL Best Paper Award。当时 ChatGPT 热度很高,你的关注点有什么不同?你的研究方向和路线是如何演进的?
🧑🏻💻 Adam 陆弘远
我当时 ACL 的第一篇一作是“AI 幻觉”相关的。
简单说,就是使用一些控制令牌来操控模型,可以显著减轻模型的幻觉问题。这个方法在世界模型上也是有效的。后来有人承接着我们的文章做了类似的研究,结果还被华尔街日报报道了。
第二篇 NAACL(Oral),我做的是 Looped Architecture。
那时候的 Looped 还比较简单,只有两层,两个 Transformer 的参数是共享的,最后再接一个 RL 用的判别式网络进行梯度回传。
这是大家第一次用生成式模型来提炼聊天双方的个人个性化信息,然后去生成对应的下游回复。

当时 Looped 架构大家用得比现在少。我是行业内少数最初用这种 shared block 的 loop 架构的研究员。
那时候我就发现,这种模型优化起来的难度比一般的模型要高。
EACL 的 Best Paper Awards,我做的是解码、增强学习和课程学习。这篇文章是我读 PhD 的第 4-6 个月写出来的,奖项算是万里挑一的,花的时间也很短,作者只有我和我老师两个人。
在这个职业阶段能独立提出想法拿到这个奖项,确实是比较少见、令人惊讶的。但我当时是比较冷静的。

在微软,我主要做的是大模型预训练——多语言模型预训练,是在 2022-2023 年。
后来 2023 年开始,我还做了 World Modelling 和空间智能,当时还没有什么人研究 VLM,我们发了 COLM(Conference on Language Modeling),是一个在加拿大蒙特利尔举办的聚焦于语言模型研究的学术会议。
这些技术栈和我们现在的大模型创业方向有关。可以说,还没有 VLM 的时候,我就在想怎么做世界模型了。
后来,我们想了一个技术方案:用符号化的方法去表达一些信息输入给更大的模型——比如 LLM,让他们能更好地处理空间信息。当天合作者试了一下,隔天就说搞通了。
这篇文章是我第一次作为通讯作者(Corresponding Author)的位置发表论文,这个角色通常都是博导。

很不巧,这些都和对于大模型来说最火的 Coding 关系不太大。我当时甚至放弃了去 MSRA(Microsoft Research Asia,微软亚洲研究院)做 Coding 的机会,选择去做预训练。因为我觉得 MSRA 预训练方向的未来更有意思。
现在来看,可能是天意。我们当时没有刻意追求热点,而是在专注做自己的方向——looped model、空间智能、representation learning。
时机到的时候,自然机会就来了。
🚥 十字路口
今年 4 月,你以自己的名字定义了一个理论——Adams Law,提到:决定模型是否聪明的,不只是“你问了啥”,还包括“你是怎么说的”。这个理论,你是如何率先发现的?
🧑🏻💻 Adam 陆弘远
我是在洗澡的时候想到的。
因为我之前多年就在做 CV(计算机视觉)的研究,处理过 data imbalance(数据不平衡)的问题。但在 LLM 领域,这个问题还没有受到业内太多关注。
这篇文章被 ACL 2026 Main Conference 收录了。文章的核心观点是,要关注模型训练阶段的低频数据。
它可以被用在所有的 LLM、Agent 上,在 AI 安全上也可以应用,因为生僻词更容易破解模型、攻击模型。类似的想法在我们的世界模型上也有应用。

🚥 十字路口
你们团队今年 6 月上传了一篇题为《Looped World Models》的论文,这篇论文关键的技术亮点是什么?
🧑🏻💻 Adam 陆弘远
这篇文章的技术核心在于,它能够通过 loop 这种架构来降低 World Modelling 当中尤其重要的 Compounding Error 的问题。
我觉得 World Model 天然适合 Looped Architecture,原因不是“循环结构最近很火”,而是世界建模这件事本身,在计算形态上就很像“反复迭代修正一个状态估计”。这和普通一次前向就出答案的任务不太一样。
Looped World Models 论文抓住的正是这个结构同构关系:
环境状态从当前走到下一步,本来就可以被理解成某种重复施加“共享转移规律”的过程,而 Looped Transformer 恰好擅长把同一个更新算子反复作用在 Latent State 上。
更具体地说,World Model 的核心不是“识别这一帧是什么”,而是“推演下一步会变成什么”。
这种推演往往不是一步就能想清楚的。简单场景下,也许一次更新就够;但复杂场景下,比如碰撞、接触、多物体交互、遮挡恢复、长链条因果传播,模型其实需要在内部多推几轮,逐步细化 Latent State,才能把状态转移估得更准。
LoopWM 的关键直觉就在这里:不是所有 Transition 都值得同样深度的计算,而 Looped Architecture 可以把“思考深度”变成一个可调节维度,让复杂步骤多迭代几轮,简单步骤少迭代几轮,这比固定深度模型更符合物理世界和交互环境的非均匀复杂度。

第二个原因是,World Model 特别需要参数效率。
因为 World Model 不是只调用一次,它往往要在 Rollout 里被连续调用很多步,甚至上百、上千步。对于这种“会被反复执行”的模块,参数量和每步计算代价会被成倍放大。
所以,如果一个架构能用共享参数反复 Refinement,而不是每加深一次就再堆一层全新参数,那它在 World Model 里就特别划算。
我们在 LoopWM 论文中明确强调,Looped Architecture 的参数复用在 World Simulation 里价值很高。因为 Rollout 本身就是一个重复调用 Dynamics Model 的过程;一个更省参数、还能按需加深计算的模型,会在整段 Rollout 上持续省成本。
第三个原因是,World Model 长期受困于 Compounding Error,而 Loop 的价值恰好在于“先把单步状态更新想得更充分一点”。
很多 World Model 的问题不是不会预测下一步,而是下一步稍微错一点,后面就一路漂。LoopWM 的思路并不是直接神奇地消灭误差,而是通过在 Latent Space 里做多轮 Refinement,让每一步状态转移在输出前先被内部打磨。
换句话说,它希望把“粗糙的一步预测”变成“经过几轮内部修正后的一步预测”。这和很多数值迭代、状态估计、Belief Update 的直觉很像:单次更新不够稳,就多做几轮内循环,把解往更好的 Fixed Point 推近。
第四个原因是,World Model 比语言模型更容易为“共享转移规律”提供语义基础。
语言里虽然也能 Loop,但不同 Token、不同位置、不同语义跨度之间,共享同一个 Refinement Operator 有时更像一种工程假设;而在World Model里,“环境演化由相对稳定的动力学规律支配”这件事本身就更自然。
论文里讲得很直接,环境动力学可以被看作某种重复施加近似平稳转移规律的过程,因此用一个共享的 Latent Update Operator 反复作用在状态上,在结构上是说得通的。
还有一个很现实的点:Loop 不是只带来“更深”,还带来“更稳地控制深度”。
World Model 如果只是盲目做深,很容易又贵又不稳;LoopWM 不是简单拉高深度,而是把深度做成可迭代、可停止、可按难度分配的。
我在论文里还专门加入了稳定性参数化,去保证 Recurrent Latent Update 不至于发散,这对 World Model 特别重要,因为它真的要多步 Rollout,状态一旦炸掉就全盘皆输。
以前 RSSM 架构只能到 50 多步 Rollout 就不行了,但现在我们可以几百步。简单来讲,就是仿真机器人的长程任务能做得更好了。
🚥 十字路口
LoopWM 的几大特点是什么?
🧑🏻💻 Adam 陆弘远
第一,Compounding Error 耐受性。
传统世界模型多步 Rollout 时,每步预测误差 ε 会被系统 Jacobian 指数放大——DreamerV3 只敢想象 15 步,50 步后彻底崩溃;视频扩散模型串联几段就出现物理不一致。
LoopWM 通过 Spectral Constraint 将模型 Jacobian 谱半径严格约束在 ρ < 1,使每次 loop 迭代成为压缩映射,误差随迭代指数衰减而非放大。在多步 Rollout 中,步与步之间的误差传播同样受谱半径约束,累积误差从“指数爆炸”降级为“有界累积”。这为 100-200 步的长时程规划提供了数学层面的稳定性保证,是现有世界模型架构所不具备的。
第二,LoopWM 的 Test-Time Scaling Law 更优。
现有的推理时,计算扩展方案代价各异:RoboMonkey 需要额外 VLM 验证器,VLA-Reasoner 的 MCTS 搜索代价指数膨胀 O(b^d),SITCOM 需要多条完整 Rollout。 LoopWM 的 Adaptive Loop Depth 是成本最低的 Test-Time Scaling 机制,每多一次 Loop 只是同一组 Transformer 参数的一次额外前向传播,代价严格 O(n),无额外参数、无 KV Cache 膨胀。
更关键的是,Loop 次数通过收敛检测自适应控制:简单场景 3 次收敛,复杂场景自动增加到 15-20 次,计算被智能分配到真正需要的地方。Prediction Quality 与 Loop Count 之间呈幂律关系,构成了一条专属于循环架构的 Inference Scaling Law for World Models。
第三,参数效率高。
当前世界模型普遍在 Billion 级参数(Cosmos 7-14B,π0 基于 3B PaliGemma),只能在云端推理。LoopWM 用同一组参数迭代 N 次获得等效 N 层计算深度,以循环换宽度。Parcae 已经验证了这一原理:770M 参数 Looped Model 匹配 1.3B 标准 Transformer 的性能。
🚥 十字路口
你提出了一个结论——“1B 参数打败 100B 参数的 Claude Opus”。可以补充讲讲吗?
🧑🏻💻 Adam 陆弘远
是的,我们的 in-house 实验上已经取得了 promising 的结果。
我们支持 LeCun 的 latent state 范式更多一些。我们目前做理解偏多,不做视频生成。
🚥 十字路口
你在论文中强调的“跨层参数共享(循环)”,这在 AI 发展史上并不新鲜,RNN 和 ALBERT 早就这么做了,RNN 最终被 Transformer 取代,因为并行性差、难以大规模扩展。你怎么看待这个问题?
🧑🏻💻 Adam 陆弘远
RNN 和 Looped 架构不太一样。
RNN 架构在 Dreamer 上最早是叫 RSSM 架构。可以通过加宽模型来解决并行效率的问题,未来也可以设计专门的 Infra,就像 Auto Regressive 模型那样。
Looped 架构有他自己的优点,未来我相信都会被解决的,我们自己公司也会有 Infra 团队。
我甚至觉得,这可能是一个独立做 Infra 公司或 Infra 世界模型的商业机会。
因为 Looped Model 是一个可以被放到其他领域上的架构,可以被其他模型或任务所参考。视频生成模型本身 Compounding Error 就是一个大问题,需要更长的 Rollout 步骤。
🚥 十字路口
还有一个问题,LoopWM 虽然节省了参数,但推理时间呢?在真实商业落地中,综合参数存储和计算时间成本,到底是省钱还是费钱?
🧑🏻💻 Adam 陆弘远
我们的 computational efficiency 是按 FLOPs 算的。推理时间也一样省——我们节省到 1/100 的计算量,这是按节省的时间来衡量的。
而且,deferred decoding 和 early exit 也可以进一步节省计算量。
我觉得,相比于省钱,目前最大的目标还是要节省时间更多一些。节省时间的核心意义是降低延时。
🚥 十字路口
你觉得 LoopWM 目前的缺憾是什么?未来你想如何补足它?
🧑🏻💻 Adam 陆弘远
LoopWM 确实有架构上的非主流,特别是在并行计算方面。这点其实和 autoregressive model 有点像。从模型架构层面、宽度超参层面、Infra 层面,未来我相信能有更好的解决。
说实话,目前我们在真机环境做的不多,还是仿真更多,未来会有更多。
针对 LoopWM,目前我们也在规划开发 LoopWAM 版本,也就是带有 action 的 shared parameter training 版本,它能推理 action。
🚥 十字路口
你在论文中提到“延迟解码”,可以展开讲讲吗?
🧑🏻💻 Adam 陆弘远
Deferred Decoding 的做法——LoopWM-DD(Deferred Decoding变体)将 Rollout 分成两层嵌套循环:内层循环(Inner Loop)和外层循环(Outer Loop) 。
说人话就是:可以在 Latent Space 里反复迭代,在更长的 Rollout 步数下保持稳定。对于机器人领域来说,我们相信未来任务一定会越来越长程,但目前的算法还是偏单步——大家现在让机器人叠衣服,而不是让机器人打扫一整个房间。
🚥 十字路口
如果完全舍弃中间解码,只在终点做预测,模型会不会在长时程中“闭着眼睛瞎走”?一旦落地到物理场景,会导致瞬时大范围的失控吗?
🧑🏻💻 Adam 陆弘远
那是推理的时候。其实训练的时候不会一直只有 deferred decoding 的训练信号,这甚至还是一个做 data augmentation 的好时机。
而且,要看你的目的到底是 world model 还是 action inference。如果你只想要当下的 action inference,那可以预测之后的多步 world 来 rollout 一下。
当然,如果是用我们正在研发的 LoopWAM(Looped World Action Model),那又不一样了。
🚥 十字路口
英伟达的高级研究员发邮件评价你们的 work 是“highly valuable contribution”,你怎么看待这个评价?
🧑🏻💻 Adam 陆弘远
是的。我觉得他说的是比较客观的。
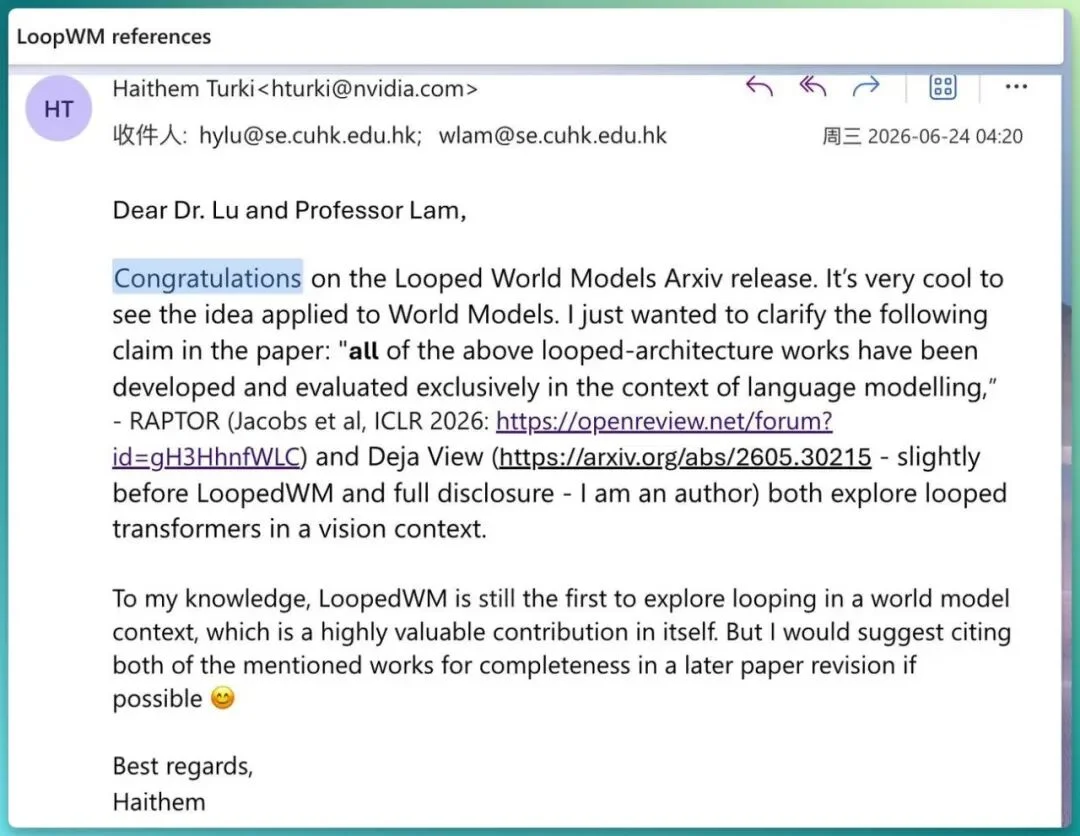
其实 loop architecture 从 2023 年开始我就在研究。
虽然不能算是一个全新的课题,但把它放在 world modelling 任务上,确实是第一次。
因为 world modelling 这个任务本身和 language modelling 有很大不同,特别是在数据量和数据的难易度区分上。
我认为这篇文章可能会对 world modelling 社区有着更长远、更重大的意义。未来会有更多人往 Loop 这套架构上偏移,因为它对长程任务有独特的优势,能让机器人端到端地执行长程任务。
我希望有一天,大家回过头来看我们的研究,LoopWM 能成为一个非常重要的里程碑。
🚥 十字路口
你提到自己现在的创业方向是做“世界模型”。FaceMind 要做的“世界模型”具体指的是什么?它覆盖的范围和场景包括哪些?
🧑🏻💻 Adam 陆弘远
我们公布了一个新架构叫 Looped World Model。
这篇文章提交到 Hugging Face 之后很快登顶了 Daily Paper。

我们的模型就是我们的产品。这个模型主要服务的是 GUI Agent 以及仿真机器人环境的世界模型。
我们不做机器人本体,在机器人本体上目前只做了 limited experience;仿真环境目前做的最多的是 ManiSkill 的灵巧操作。等以后公司更大大了也会涉及。
🚥 十字路口
这个模型现在的进度是怎样的?
🧑🏻💻 Adam 陆弘远
接下来我们在做的一个方向是,把这个模型拓展到 Looped World Action Model 上,以及搭建一些创新的数据 pipeline。
另外,我们也在补齐公司算法人才和算力方面的缺口。
今年,我们预期会发布一个 10B 量级的 World Action Model。
🚥 十字路口
你们之前的产品是“叠叠社”。从“叠叠社”到“通用世界模型的 Neolab”,跨度很大。这次转型,是一个怎样的契机和触发点?你是如何考虑的?
🧑🏻💻 Adam 陆弘远
叠叠社想“拯救宅男宅女”是很美好的想法,因为我们团队本身就是宅男。
但我们除了这个标签,还有一个身份是 researcher。
起初创业的时候其实做得很辛苦,因为我们没有产品经验,也没有运营经验,而且,这不单单是具体产品的问题。
毕业后,我逐渐意识到,技术导向可能更适合我。
有句话说得好,你可以花一分力气做到十分效果的事,那就是你的天分。显然世界模型更适合我们的 founding team,因为我们是顶尖的研究员。
🚥 十字路口
聊聊现在 FaceMind 团队的情况?
🧑🏻💻 Adam 陆弘远
我们 founding team 是我和 Vic(韦怡然)两个人,我主要负责算法,他主要负责工程。
我之前在香港中文大学念的 PhD,publication list 非常漂亮,也有 Best Paper Award,还有几个 ACL 竞赛的金牌。而且我 2022 年就在做 Looped Architecture 了,2023 年开始做空间智能。
Vic 是剑桥大学的 PhD,主要做 representation learning,也就是 LeCun 的隐空间世界模型那个流派。Vic 工程能力很强,比我强得多。

FaceMind CEO Adam Lu(左)& FaceMind CTO Victor Wei(右)
我们工作一直很肝,经常半夜三点还在讨论工作。我经常凌晨 3 点打电话给 Vic 开会,讨论技术问题。
我们团队现在大概二十多人,平均年龄可能只有 20 出头。大家动力很足,自驱力很强,而且都很有天分。很多人加入并不是为了更好的薪资,更多的是方向和目标一致,大家都相信公司未来能长得很大。
🚥 十字路口
FaceMind 的融资情况和后续资金规划是怎样的?
🧑🏻💻 Adam 陆弘远
目前我们在筹备最新一轮融资,估值在数亿美金。
商业化对于这个赛道其实还不急。我们团队的优势之一是现在股权还有稀释的空间,可以再多拿几轮。
🚥 十字路口
FaceMind 当前的研发情况是怎样的?
🧑🏻💻 Adam 陆弘远
目前我们大部分资金都放在研发上,计划将一半以上的后续资金用于模型训练。最多的时候,我们同时运行近百卡。
数据主要是仿真机器人数据和真机数据的混合,有开源的,也有一部分是自采的,目前自采的比较少。
🚥 十字路口
当前,世界模型赛道的创业火热,你认为 FaceMind 的独特之处什么?
🧑🏻💻 Adam 陆弘远
永远在创新,去往没有人想过的地方。
也许某一天,我们就不再只做 world model 了,我们可能会比 LeCun 还早找到下一个 AGI 的解。
相较于从美国照搬一套逻辑的创业项目,我认为,“主动创造非共识”是我们竞争的最好手段。
🚥 十字路口
从 2023 年开始创业,3 年时间里,在团队合作中,有一些深有感触的挑战性时刻吗?
🧑🏻💻 Adam 陆弘远
我觉得最有挑战的事情是,我以前会让团队做一些他们不擅长的事,后来我意识到这样不行,一个人应该被放在能最大发挥他价值的地方。
还有一件事让我感触挺深的。我们有一位员工需要经常和家里报备、讨论,因为他的伴侣很担心他在创业公司。这让我意识到,创业确实需要相对年轻一点——因为只要自己一个人做决定就好,没有成家。当然,另一半特别支持的情况是例外。
另外,刚运营公司的时候我会很担心,觉得团队没有我就运作不下去,所以每天很操劳地盯着业务。现在好多了,关键位置都有合适的人在掌舵负责。
🚥 十字路口
你说自己有很强的“技术直觉”,假如“技术直觉”错了,会不会对公司和合作伙伴带来巨大损失?
🧑🏻💻 Adam 陆弘远
其实我觉得还好。我的技术直觉高于行业平均水平。其实大概前25%的水平,就能在自己的赛道上足够survive了。我自认达到了这个水平。
🚥 十字路口
你相信自己的“技术直觉”不会错?
🧑🏻💻 Adam 陆弘远
是的。我相信我的技术直觉是不会错的,我一向比大部分普通 level 的人要准得多。
🚥 十字路口
你曾说“自己不想做一个商人气质太重的人”,但创业本质上是商业行为,会面临融资稀释、产品方向妥协等现实问题,你怎么看?
🧑🏻💻 Adam 陆弘远
世界模型为导向的公司,在目前的阶段谈商业化还早了点。我们团队也有专门负责商业化的人。但我觉得融资并不是单纯以商业为导向的事情。
我不排斥把自己当做 businessman,这是一个很 nice 的 title。
🚥 十字路口
在“世界模型”这个全球技术路线正在涌现的领域,你觉得属于中国团队的机会在哪里?
🧑🏻💻 Adam 陆弘远
人才密度。在中国创业,AI 人才密度极高。
🚥 十字路口
你觉得,比如5年之后,世界模型公司会是怎样的竞争图景?
🧑🏻💻 Adam 陆弘远
我觉得可以类比一下:那时候,中国可能只剩下不到 6 家世界模型公司,每家公司一定会有一个更专注的领域,可能是视频生成、家用机器人,或者工业机器人。
那时候,也许大家再也不需要请保洁了,因为机器人长期成本更低;送外卖的小哥,可能也都变成了机器人。
🚥 十字路口
那时候,如果 FaceMind 成为你理想中的样子,那会是一家怎样的公司?
🧑🏻💻 Adam 陆弘远
我们全称叫 FaceMind Research Asia。我希望它成为一家像 Facebook、Google 和 Microsoft Research Asia 一样的公司,能给人类社会带来更大的幸福。
不过我其实觉得,那时候 FaceMind 很可能也不只在做世界模型了——技术永远在迭代,我们更想走在风口浪尖,去拥抱最新的技术。
文章来自于"十字路口Crossing",作者 "Koji"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
