# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT


该工作已被机器学习领域顶级会议 ICML 2026 录用,论文题目 “PRISM: Parallel Residual Iterative Sequence Model”。
(一)Transformer 的无限背包与线性注意力的有限背包

背包容量有限,每来一个新 token,模型必须决定往里写什么、同时擦掉什么。这个 "写与擦" 的规则,决定了有限背包模型的天花板。但在深入讨论 "写与擦" 之前,我们先要回答一个更基本的问题。
(二)有限背包本质上是 RNN,为何还能并行?
确实如此,有限背包模型的数学形式本质上就是 RNN:
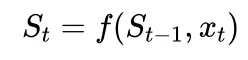

关键在于一个数学技巧:Parallel Scan(并行前缀扫描)。

(三)为什么并行这么重要?GPU 的 "搬运工" 瓶颈
一个常见的误解是将 "串行慢" 归因于更多的浮点运算。实际上,瓶颈在别处。现代 GPU 的计算核心(Tensor Core / CUDA Core)算力极为充沛,A100 GPU 每秒能做 312 万亿次浮点运算(312 TFLOPS)。真正的瓶颈不是 "算",而是 "搬"。
GPU 的存储分为两层:
打个比方:SRAM 像工作台(小但触手可及),HBM 像仓库(大但每次取货要走一趟)。
所以每一次计算都要经历一个 "搬运" 流程:把数据从 HBM 搬进 SRAM,在 SRAM 里算完,再把结果搬回 HBM。这个搬运的时间往往远超计算本身,这就是所谓的 memory-bound(存储带宽瓶颈)。

能否适配parallel scan 不仅是算法设计上的美学选择,更直接决定了 10-100 倍的实际运行速度差异。
(四)Rank-1 写入的瓶颈
以 GDN (Gated DeltaNet)为代表的线性注意力模型,每个 token 对 S 做的是一次 rank-1 更新:
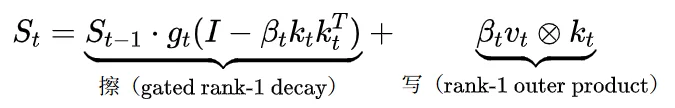

如果一个 token 携带的语义是多维度的(它同时是某个句法结构的成分、某个语义角色的载体、某个 topic 的关键词),rank-1 的一行写入无法同时在这些维度上做精细调整。信息在压缩写入时不可避免地丢失。
核心矛盾:背包有限,每次却只允许写一行。这是当前所有线性复杂度模型的共有瓶颈。
(五)TTT 的突破与代价
既然 rank-1 写入太浅,一个自然的想法是:让模型学会更深的写入规则。
TTT(Test-Time Training)系列工作采取了一种根本性不同的策略:把记忆状态从一个 linear 矩阵 S 升级为一个 MLP 的权重矩阵。每来一个 token,对 MLP 的权重做多步梯度下降(multi-step GD),逐步精炼写入内容。这带来了显著的质量提升。

在设计 PRISM 之前,我们首先深入分析 TTT-MLP 的梯度结构,弄清楚它的高表达力到底从何而来。
(一)步长 × 残差 × 方向 模式的涌现

(二)高表达力与串行是同一根因的两面

具体来说,它造成了两个维度的串行瓶颈:
1. Token 间串行(Inter-token Seriality)

2. Step 间串行(Intra-step Seriality)
瓶颈 C(方向与残差的同步):在多步 GD 中,第 l+1 步的写入方向必须等待第 l 步的权重更新完毕才能确定,残差也必须等上一步算完才能得到,强制引入一个无法展开的循环。
瓶颈 C 是最核心的矛盾:它同时是 rank-L 表达力的载体和步间串行的根源。因此消除瓶颈 C 不能简单取消迭代,必须在取消同步耦合的同时保留多方向和残差递减带来的表达力。
基于上述分析,PRISM 的策略非常明确:在兼容 parallel scan 的线性状态 S 上显式重建 TTT-MLP 的 步长 × 残差 × 方向 模式,然后分维度消除串行。
(一)核心迭代形式:步长 × 残差 × 方向
PRISM 显式构造了 TTT-MLP 的多步迭代模式:


与 TTT-MLP 的对应关系:


(二)消除 Token 间串行:A/B 分离 + 局部 Anchor 代理

至此,序列级别的 parallel scan 已完全恢复。anchor 让不同 token 的迭代可以同时启动,但每个 token 内部的 L 步之间仍需顺序执行(瓶颈 C)。
(三)消除 Step 间串行:解耦链 + 闭合式预计算
解决瓶颈 C。因为有了 anchor,两条链自然解耦:

L 步的串行循环被消解为单步闭合式计算。整个多步梯度下降计算过程可以编译成一个 fused kernel,数据只需要从 HBM 搬进 SRAM 一次。
(四)架构全貌与 GDN 退化
多步梯度下降计算过程的原始产出是 L 个 rank-1 迭代计算:
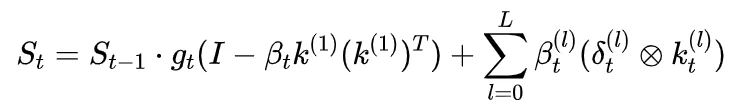

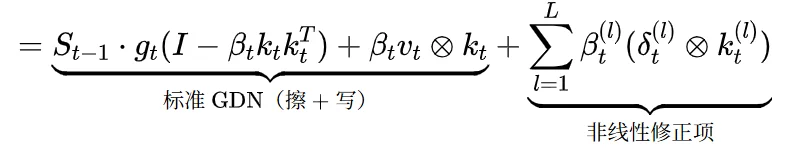
PRISM 可以视为一种多步残差拟合计算过程,L=1 时精确退化为 GDN。 后续步只是在第一步的基础上追加非线性修正,且可以使用 low rank 网络增量,额外参数量不超过基础模型的 10%。
(一)序列推荐
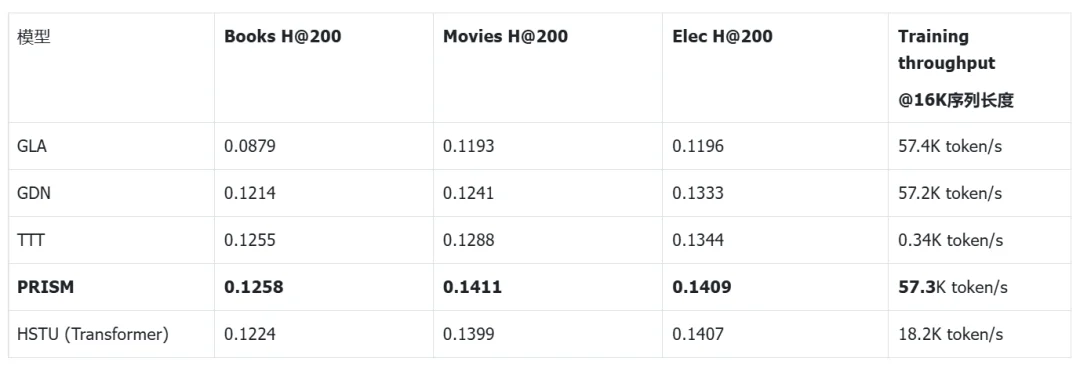
在公开序列推荐基准 Amazon 上,PRISM 表现与 Transformer baseline 效果接近,超过大多数线性注意力类方法。计算效率方面,PRISM 与 GDN 同级,比 TTT-MLP 快 174 倍。
(二)语言建模(基于 SlimPajama 2B 训练,130M 参数)
在更大规模的语言建模实验上(SlimPajama 2B tokens, Mistral tokenizer),PRISM 同样取得了全面领先:
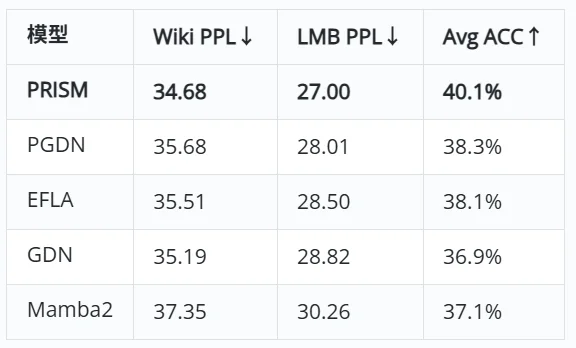
PRISM 在 WikiText PPL、LAMBADA PPL 和 9 项 Zero-Shot 下游任务平均准确率上均为最优,领先 GDN 3.2 个百分点。
(三)组件消融
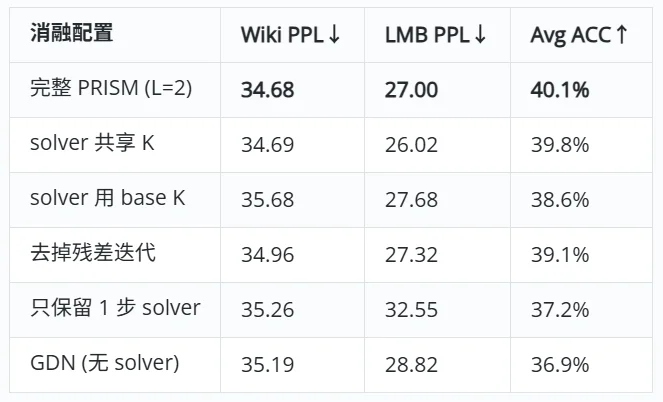
训练 PPL 差异极小,但下游泛化差异巨大。单步 solver (L=1) 的训练 PPL 几乎等于完整版,但 Avg ACC 下跌 2.9 个百分点 ——rank-L 的真正价值不在 next-token prediction 上,而在需要精确长程检索的下游任务上。

(一)有限背包终究有限,混合架构也许是必然

从 PRISM 的视角看,这个直觉有一个很好的技术解释。PRISM 用短卷积(ShortConv)计算的局部 anchor 替代全局状态 S 来近似残差。由于短卷积窗口通常只覆盖最近 3-4 个 token,对于需要跨越数千步的长程依赖,近似质量必然下降。
如果在 PRISM 层之间穿插少量 Transformer 层,后者就充当了一种全局的、非线性的历史状态精确计算器,能补偿 anchor 在长程上的近似误差。从这个角度看,Transformer 本身就是 ShortConv anchor 的 "全局升级版":ShortConv 用固定窗口的局部卷积近似历史状态,Transformer 用全局 attention 精确算历史状态。

(二)线性注意力的 LoRA?
PRISM 的最终形式有一个有趣的结构特征:
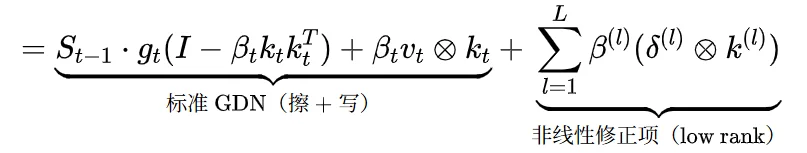
这个 "基础迭代过程 + low rank 旁路" 的形式,跟 LoRA(Low-Rank Adaptation) 非常相似,这启发了一个微调场景下的有趣思路。
LoRA 的核心思想是:冻结预训练好的大模型权重,只在关键层旁边加一条 low-rank 旁路来做微调。受 PRISM 形式的启发,我们可以设想一种面向 Linear Attention / SSM 模型的参数高效微调方法:对已训练好的模型,冻结基础迭代过程,只在写入支路上增加一条 PRISM 风格的残差拟合旁路,此外,这条旁路有闭合式(不增加训练时间),而且第一步退化为原模型的标准写入(不破坏预训练知识)。这意味着它满足 LoRA 的两个关键要求:参数高效和不损害原模型能力。
PRISM 验证了 "写入前思考" 范式在线性注意力模型中的可行性:通过分析 TTT-MLP 的梯度结构揭示 步长 × 残差 × 方向 迭代模式,在线性状态上显式重建该模式并通过 anchor 代理和闭合式预计算实现完全并行。最终架构极简 ——GDN + 非线性旁路,训练速度与 GDN 同级,参数增量不到 10%。在推荐和语言建模两个场景上的验证表明,这是一项通用的线性注意力增强技术。未来我们将进一步探索 PRISM 在更大参数规模上的 scaling 行为和推荐系统上的应用效果,以及其作为线性注意力模型参数高效微调方法的实际效果。
参考文献:
[1] Sun et al. “Learning to (Learn at Test Time): RNNs with Expressive Hidden States.” NeurIPS 2024.
[2] Yang et al. “Gated Delta Networks with Pairwise Tokenized Graphs.” NeurIPS 2024.
[3] Katharopoulos et al. “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention.” ICML 2020.
文章来自于"机器之心",作者 "机器之心"。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
