# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
那么这样一种高效直观的多教师 OPD 策略是否能够应用于图像生成任务呢?如果可行,这将是构建涵盖多种生成内容、生成质量良好、风格多样的超强通才文生图模型的一次有益尝试!
最近,来自 USTC、UCLA、CUHK 和小红书的研究团队开创性地提出了 Flow-OPD,这是首个将 OPD 引入流匹配模型的统一多任务后训练框架,为构建可靠、多维度泛化的视觉基础模型提供了高度可扩展的对齐新范式。

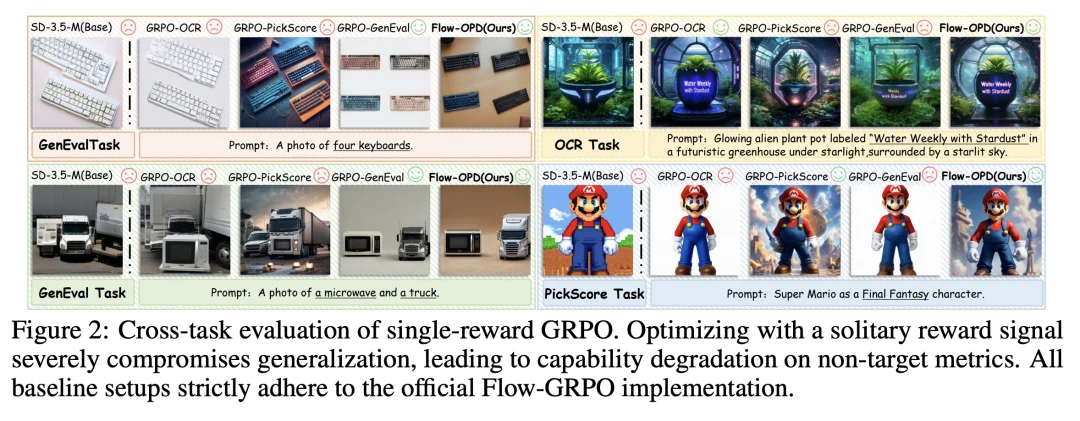
在流匹配模型的后训练对齐中,核心问题在于模型无法同时兼顾多个异构的对齐任务,陷入了严重的「跷跷板效应」。
具体表现为:
单奖励 GRPO 虽然能在孤立的单目标任务中让模型逼近性能天花板,但会导致非目标领域的对齐能力发生严重退化,引发「奖励黑客」行为,如上图所示,使用 GenEval 进行强化学习训练的模型无法成功完成文字渲染和风格化生成任务;
混合奖励 GRPO 试图通过简单堆叠或混合多个标量奖励函数来进行联合优化,却根本无法建立稳定的认知基础,每当引入新的奖励信号时,就会引发此前已习得能力的灾难性遗忘与参数吞噬。如下表所示,每当有新的奖励模型加入训练,模型进行基础视觉生成和文本渲染的能力都会下降。
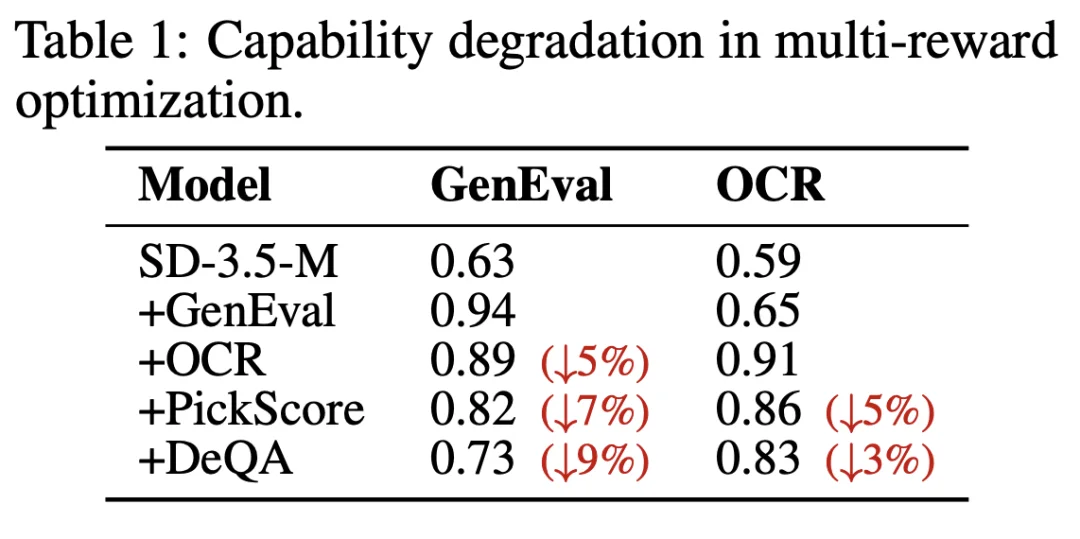
无论是 GRPO 单独训练还是混合训练,其核心症结在于稀疏的标量奖励无法有效调和异构任务之间的梯度冲突,导致单独训练时因缺乏多维监督而引发非目标能力的严重降级,而混合训练则会因异构梯度间的参数内耗触发对先前能力的灾难性遗忘。
那么,是否存在一种训练方式,在每一种任务上都能达到对应的能力上界呢?是否可以通过一种方式,将多个单奖励训练的「教师模型」压缩进一个「学生」,从而构建通才流匹配文生图模型呢?
对于相似的多任务优化难题,DeepSeek-V4 和 GLM5 等模型成功启发了我们进行一种另外的尝试:多教师 OPD 合版。通过学生模型的在线 rollout 和教师模型的稠密奖励巧妙解决了多任务的梯度冲突。

Flow-OPD 的训练框架如上图所示:
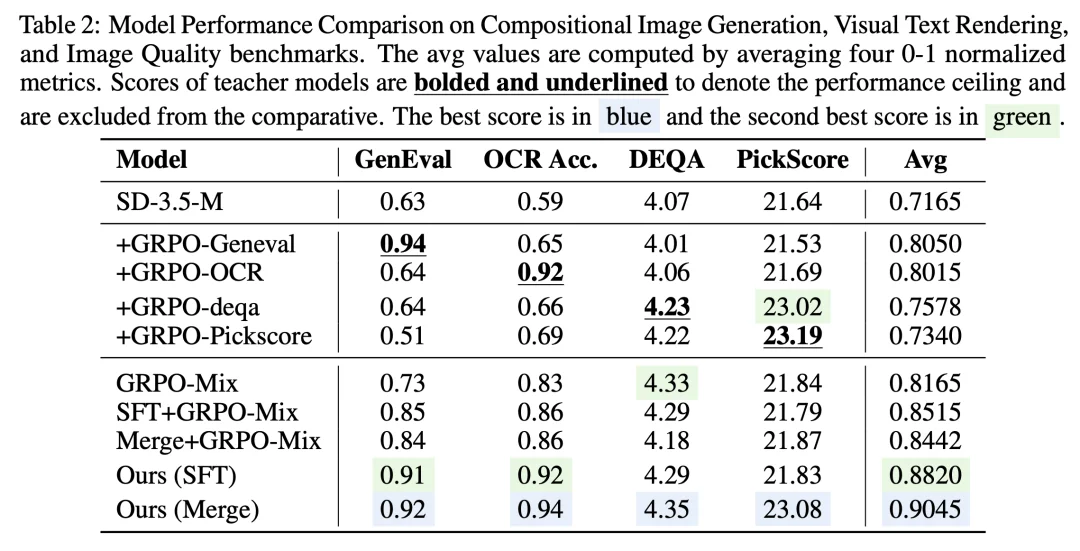
为了验证 Flow-OPD 的性能,我们使用 stable-diffusion-3.5-medium(SD-3.5-M)作为基线模型,遵循 Flow-GRPO 的数据和训练方式进行教师训练。
多任务性能

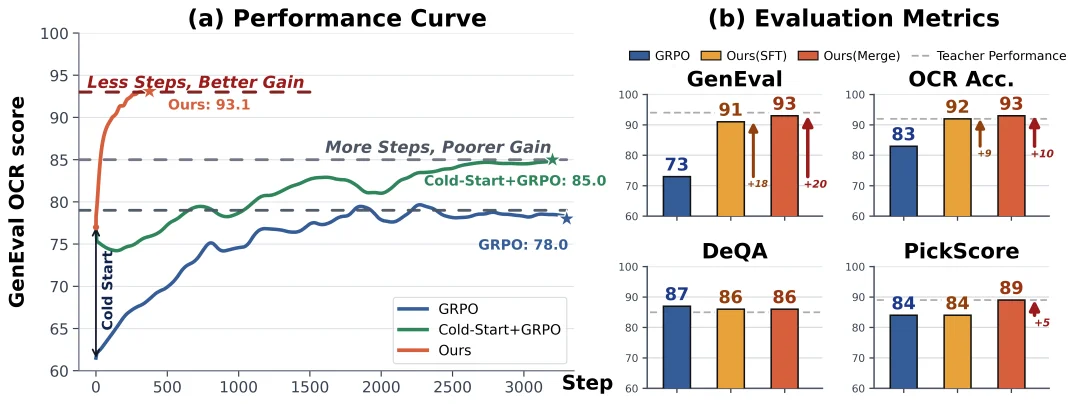
多任务训练常面临「顾此失彼」的瓶颈,而新框架 Flow-OPD 实现了突破。它在文本渲染和图像质量等多个维度全面看齐并超越了各领域的专家模型,有效解决了多任务联合训练中的能力衰退与优化难题。
更重要的是,在多位导师模型集体失效的极端边缘场景下,Flow-OPD 表现出「青出于蓝」的「出师」现象(如上图的生成橙色剪刀)。这种通过多专家协同监督的方式,成功消除了单一模型的领域偏见,促使学生模型在潜空间中融会贯通,最终探索出超越任意单一导师的更优解法。
冷启动消融
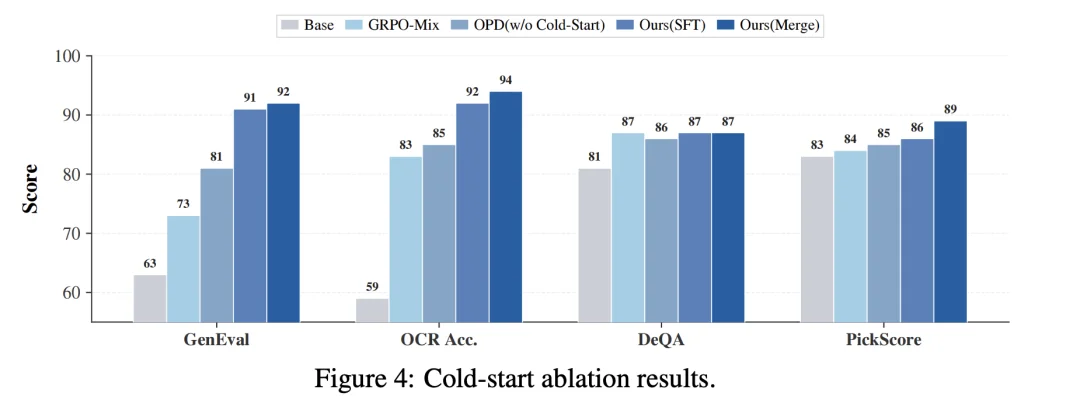
冷启动初始化为后续训练快速奠定了坚实基础。在现有方案中,监督微调(SFT)扩展性强,具备吸收异构导师能力冷启动的潜力;模型融合(Model Merging)则能在零训练成本下,完美对齐同构导师的各项功能。
MAR 图像质量正则化

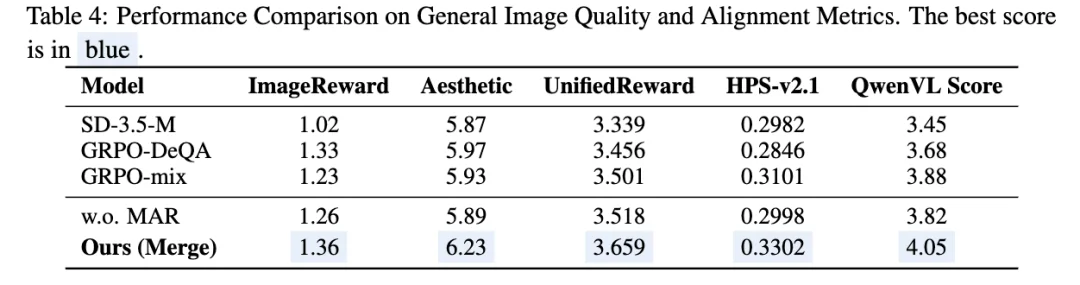
传统的 GRPO 优化由于奖励粒度过粗,容易导致模型陷入背景模式崩塌或语义冗余,而单纯依赖导师模型又常面临指令遵循度不足的困境。 MAR 成功突破了这一瓶颈。它将优化过程锚定在高保真流形上,对于所有数据全流程监督,在保持结构多样性的同时,实现了精准的语义遵循。表格的定量结果进一步证实,MAR 引入的全局数据集监督,在图像视觉质量与人类偏好对齐上均取得了显著突破。
Flow-OPD 成功的核心在于在线多专家密集监督机制。传统方法仅依赖稀疏的标量奖励,极易引发任务间的梯度干扰。而 Flow-OPD 在在线训练过程中,将优化实时锚定在高保真流形上,利用多位专家的密集信号进行动态、协同的引导。这种在线互动不仅化解了梯度冲突、消除了单一偏见,更让学生模型在潜空间中融会贯通,高效实现了多任务的实时联合优化与超越。
未来,Flow-OPD 框架还可向多个方向拓展:
Flow-OPD 作为首次将在线策略蒸馏引入流匹配扩散模型多任务训练的创新尝试,成功打破了传统联合优化的瓶颈。它不仅实现了多能力的完美融合,更展现出「青出于蓝」的超越潜力。未来,这一全新范式有望在具身智能、跨模态协同等更广泛的领域发酵,为构建真正通用、全能的下一代生成式大模型开辟全新的演进路径。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
