# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026年再看Agent,一个越来越难回避的事实是:能力正在从模型里流到模型外。真正决定系统上限的,不再只是参数、Prompt和tool calling,而是记忆、技能、协议以及统摄这一切的harness。上海交大这篇综述最有价值的地方,就在于它把这件事从零散经验上升成了一个完整框架:为什么外化会发生,它如何改变任务本身,以及为什么harness正在变成Agent时代真正的基座。

本文将为您深度拆解这篇来自SJTU的重磅论文。我将以层次分明的结构,带您看清Harness是如何作为Agent时代的基座,将强大的模型算力转化为稳定、可控的工程生产力的。

研究者借用了认知科学家唐纳德·诺曼(Donald A. Norman)提出的“认知制品(Cognitive Artifacts)”概念。外部工具的出现并没有改变人类原有的生理能力,而是直接改变了任务本身的性质。

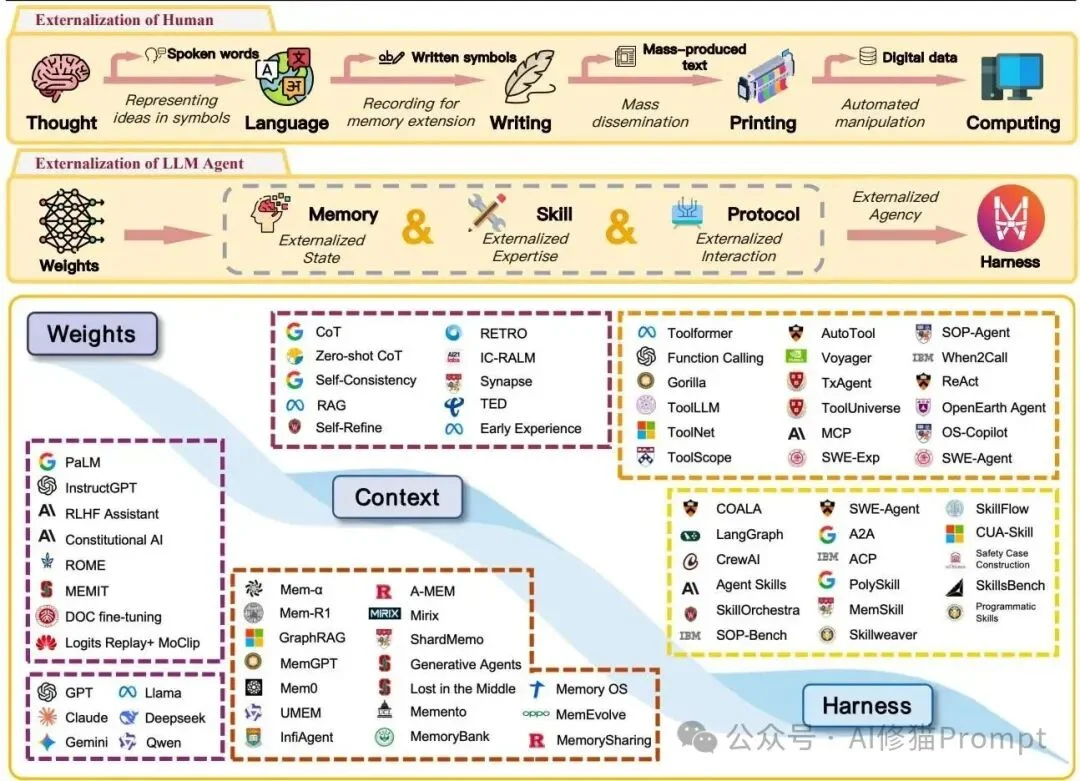
论文用一张总览图把“人类认知外化史”与“LLM智能体外化路径”并置起来,说明能力如何从权重、上下文一路迁移到记忆、技能、协议与harness。
研究者观察到,LLM智能体的发展经历了一条清晰的能力外移路线:
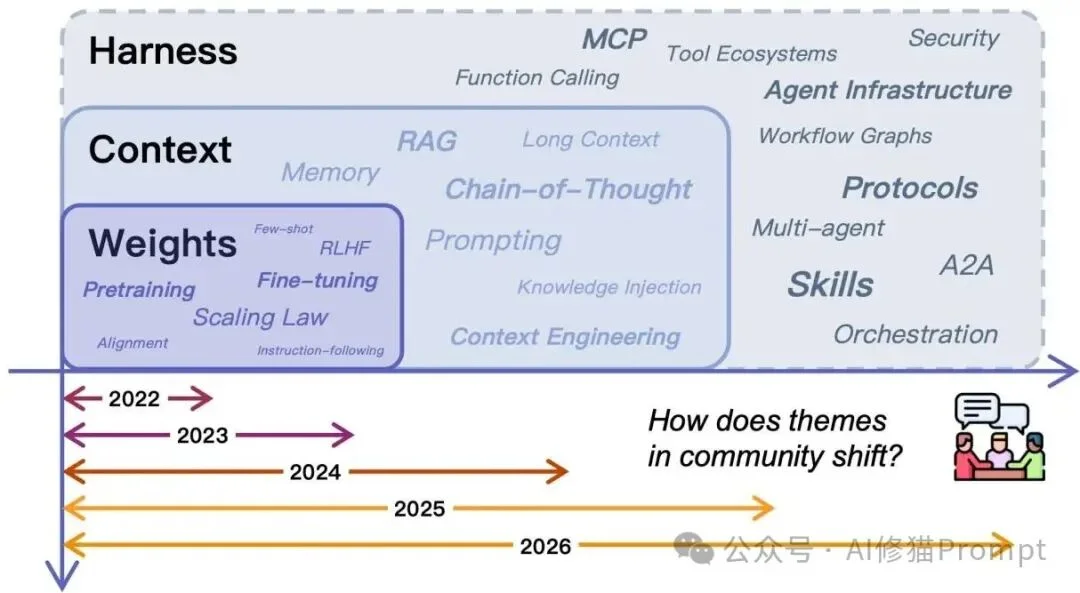
社区研究重心沿着Weights、Context、Harness三层持续外移,工具生态、协议、技能与多智能体编排逐渐成为新的中心。
在这种宏观视角下,研究者将外化系统分为三个核心维度:记忆、技能与协议。我们将为您逐一剖析。
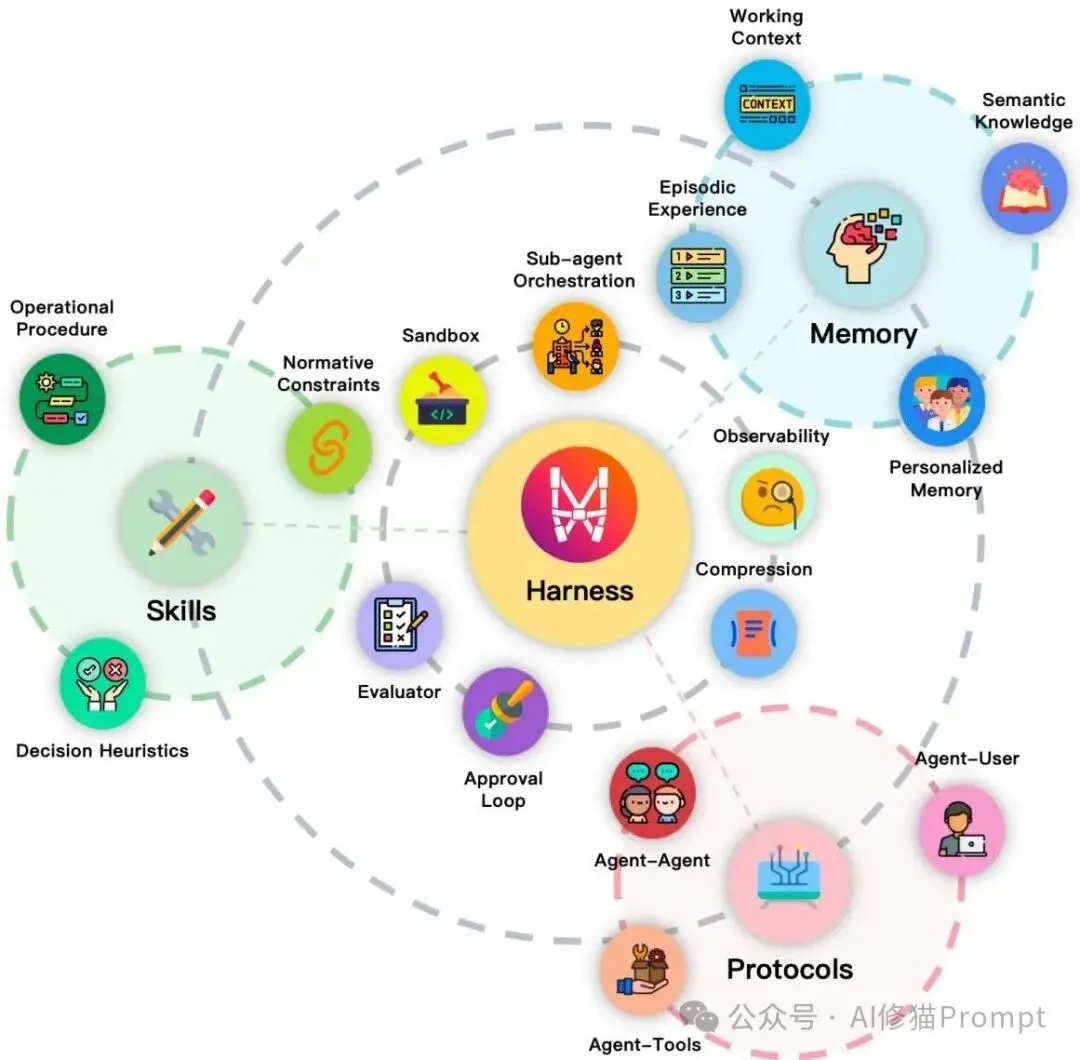
Harness位于中心,记忆、技能和协议围绕其组织,沙盒、可观测性、评估、审批和子智能体编排等运行时机制负责把三类外化模块接成可治理系统。
记忆系统解决的是智能体在时间跨度上面临的连续性负担。没有记忆的模型,每一次调用都等同于一次“失忆”后的重新启动。
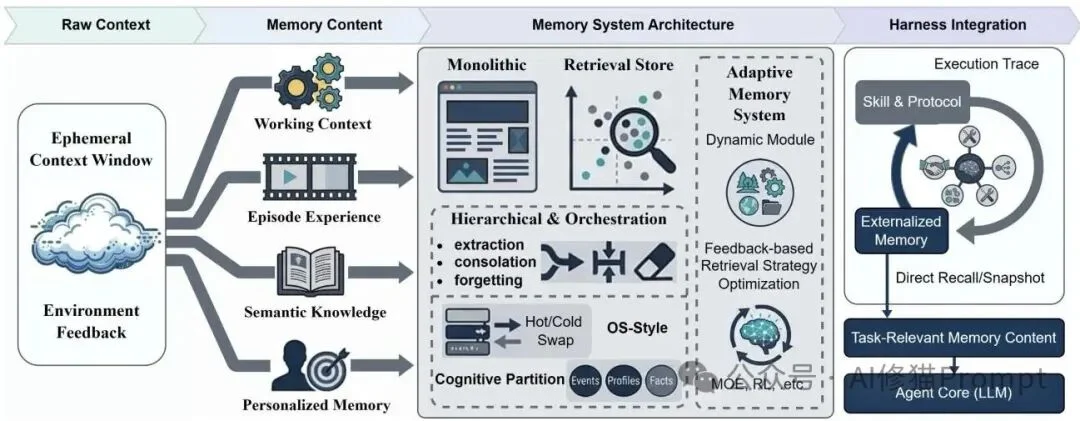
记忆外化不仅区分工作上下文、情景经验、语义知识和个性化记忆,还展示了从单一上下文到检索存储、分层编排和自适应记忆的架构演进。
研究者将需要外化的状态信息细分为四个层次:
在工程实现上,研究者梳理了记忆系统从简单到复杂的四种架构:
在讨论记忆时,我们不能仅仅关注“存了多少”,更要审视它是如何失败的。研究者极其具体地指出了记忆外化的风险陷阱:
反复让模型在推理过程中重新发明工作流,必然导致步骤遗漏或工具使用的随机性。因此Memory System为Agent解决了连续性问题,Skills解决的则是执行稳定性的问题。
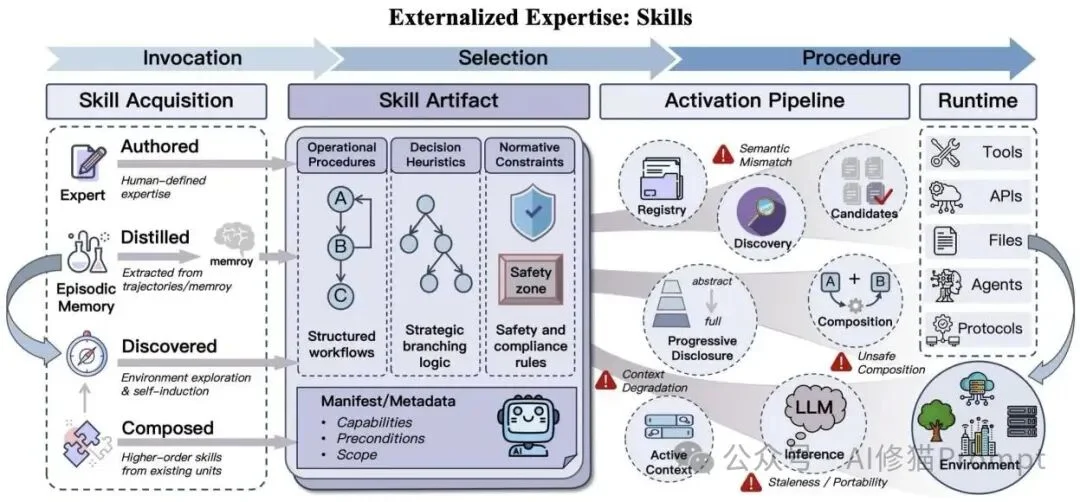
技能被画成一条完整生命周期:从专家编写、经验蒸馏、环境发现和组合生成进入系统,再经过注册、检索、渐进式披露和执行绑定,最终在运行时落地为可复用程序。
研究者强调,这里的“技能”并不是指一个简单的工具API,它是一种可复用的专业知识封装。一个完整的技能包含:
一个技能要真正在系统中跑起来,需要一套精密的调度流水线:
SKILL.md 或结构化清单的形式存在,像API文档一样声明该技能的功能、适用范围、前置条件和执行约束。研究者指出,优秀的技能系统应该是具备生长能力的。技能的来源包括:
协议层解决的是智能体与其他实体(工具、人类、其他智能体)之间的协作负担。如果没有明确的契约,模型每一次发起调用都像是在玩猜谜游戏。
研究者认为,协议将模糊的自然语言推理转化为以下四个维度的确定性契约:
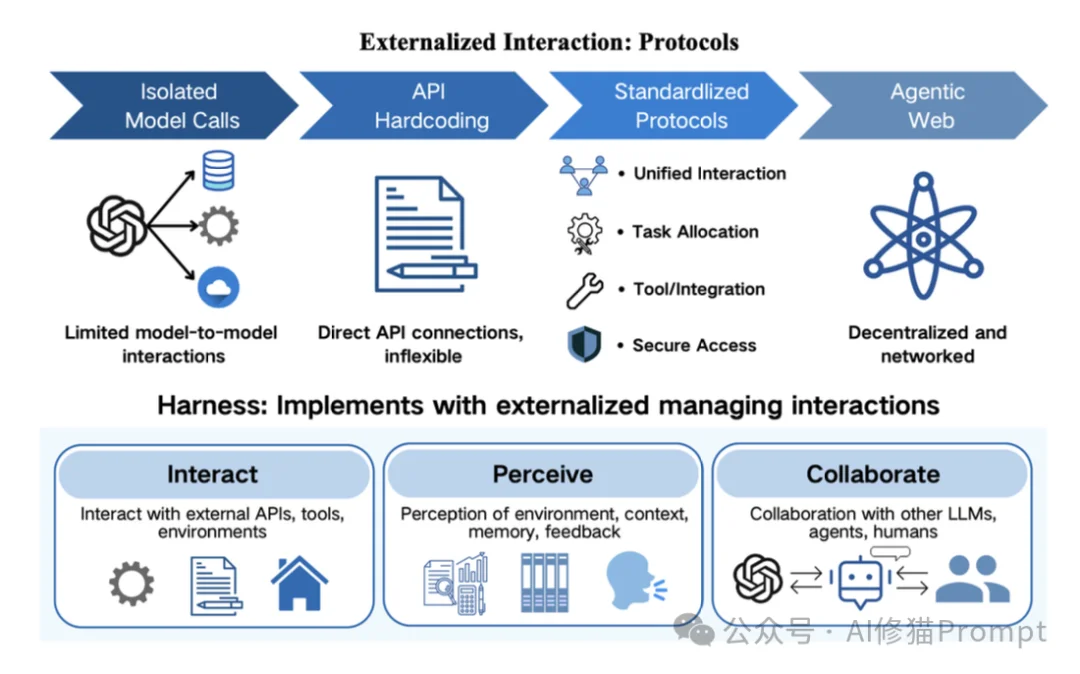
协议外化把自由形式交互改写成标准化契约。一方面交互形态从孤立调用走向协议化网络,另一方面harness通过 Interact、Perceive、Collaborate 三个表面管理对外互动。
按照交互对象的不同,研究者对当前活跃的协议家族进行了分类:
如果只有记忆、技能和协议,它们依然只是一堆零散的零件。研究者提出了“运行环境工程(Harness Engineering)”的概念,这是将外化的认知模块编织成连贯代理行为的治理层。
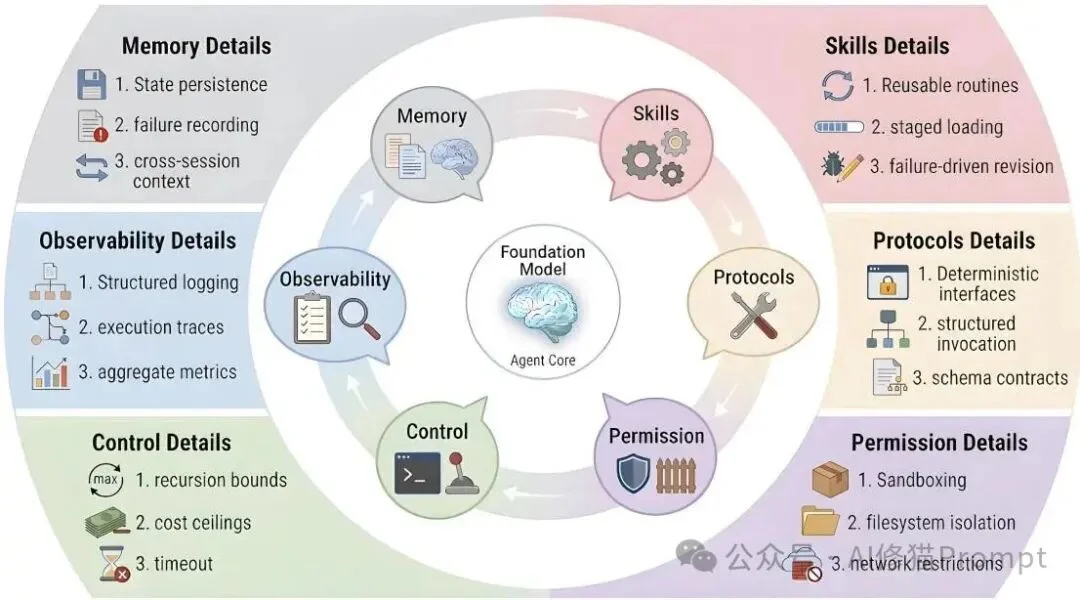
论文把harness看作智能体的“认知环境”,其核心不是单个模块,而是记忆、技能、协议与权限、控制、可观测性六个维度的协同闭环。
研究者抽象出了区分一个优秀Harness架构的六个分析维度:
各个外化模块并不是孤立运作的。研究者在论文的后半部分,详尽阐述了模块之间相互强化的系统级动态。
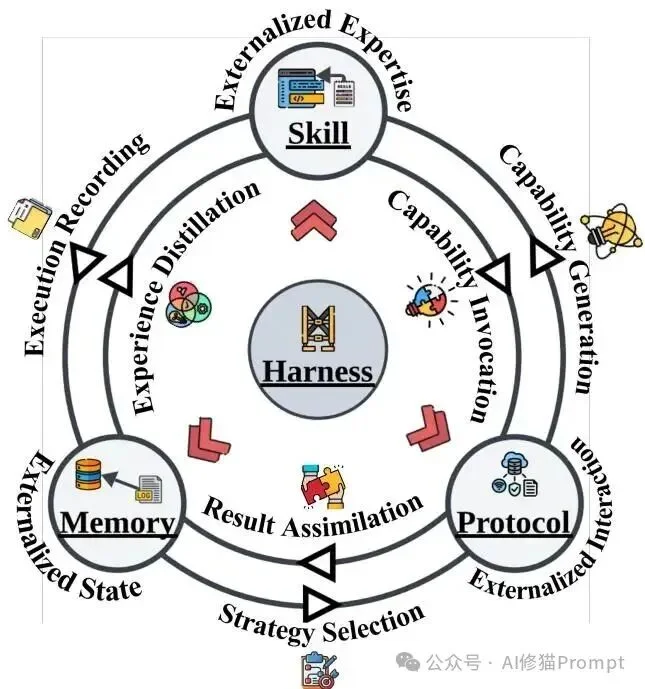
跨模块耦合图总结了六条关键流动路径:记忆为技能形成和协议路由提供证据,技能把经验固化为程序,协议则约束执行并把标准化结果写回记忆。
随着外化逻辑的不断深入,研究者为我们描绘了智能体技术未来的发展图景:
在这场深刻的技术演进中,您所面对的不再仅仅是参数量日益庞大的数学模型。研究者通过极其严谨的推演向我们证明:打造可靠的智能体,本质上是一场精密的系统工程。通过将记忆、技能和协议有机地外化,并在严谨的运行环境中加以约束,我们正在为人工智能构建一个稳定、透明且具备自我进化能力的认知底座。未来的竞争,不仅仅是模型智商的角逐,更是构建这种“认知基础设施”能力的全面比拼。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
