# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。

这不是第一个试图「什么都做」的模型。过去两年,多模态是所有大模型公司都在讲的故事。大多数方案的本质是拼接:语音进来先转文字,文字处理完再转语音,图片走一条独立通道,视频又是另一条。模块之间的信息在翻译中不断损耗。
Qwen3.5-Omni 走了另一条路。它的 Thinker-Talker 架构让所有模态在同一个模型内原生处理——Thinker 负责跨模态的深度推理,Talker 负责实时语音输出,两者共享同一套表征空间。
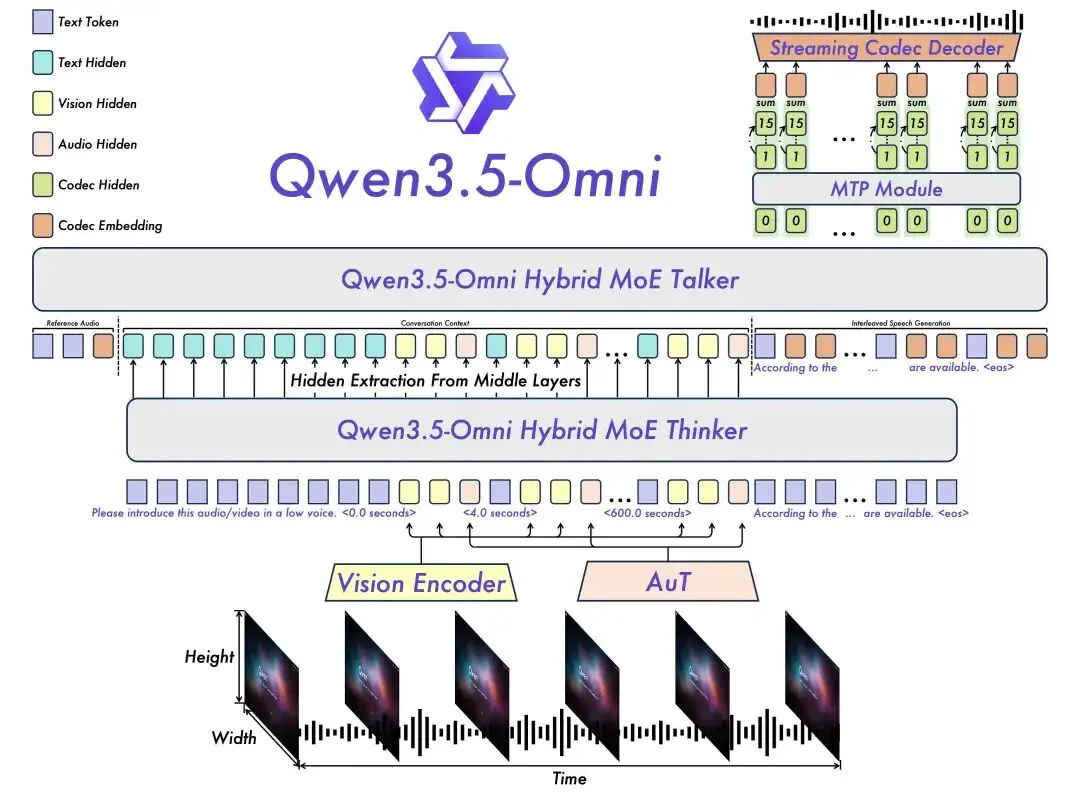
结果是:在音频、视频、推理和交互任务上拿下 215 项子任务的 SOTA 成绩,音频理解/推理/识别/翻译/对话全面超越 Gemini-3.1 Pro,同时视觉和文本能力保持同尺寸 Qwen3.5 的水平,没有退化。
比数字更值得看的,是 Qwen 团队在发布页上放出的那批演示视频,不是做题,也不是跑分,而是在展示「和 AI 互动」这件事可以是什么样。
Qwen3.5-Omni 处理视频素材是多管齐下:自动切片,标注时间戳,识别画面中的人物、动作与空间关系,同时分析音轨中的背景音效和对话内容。模型真正在做的,对时间线上视听信息的同步解析。像下面的视频片段来自《舌尖上的中国》,3.5-Omni 能生成的是结构化的细粒度描述。
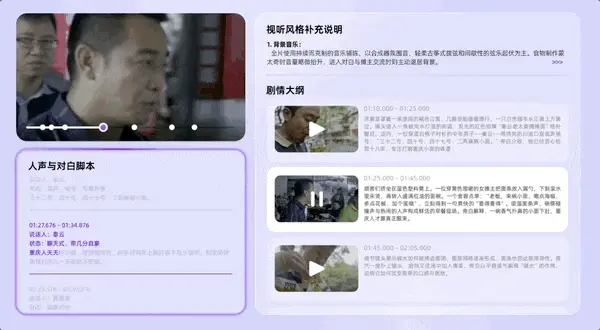
更复杂的场景里,模型处理的是电影片段:多人、多镜头、复杂音效叠加。它能区分不同角色的对话,识别背景音乐的情绪色彩,描述镜头调度和场景切换。

这些能力可以用在什么场景下呢?一个偏向应用的演示是内容合规审查:给模型一段游戏视频,它自动按时间段输出违规类型、风险等级和具体描述,生成完整的合规预警摘要表。传统方案需要人工逐帧审核,这里模型直接给出结构化结果。

如果说上面的演示展示的是模型「看」的能力,下面这组则展示了它「进入场景」的能力。
博客上的一个演示是多轮对话与智能打断:用户举着手机和模型共读一篇论文,随时插话提问。模型基于 Omni 架构原生支持语义打断,区分用户的有意打断和无意义的背景音,不会在你清嗓子的时候停下来。这依赖于模型对 turn-taking 意图的实时识别,而不是简单的音量阈值检测。
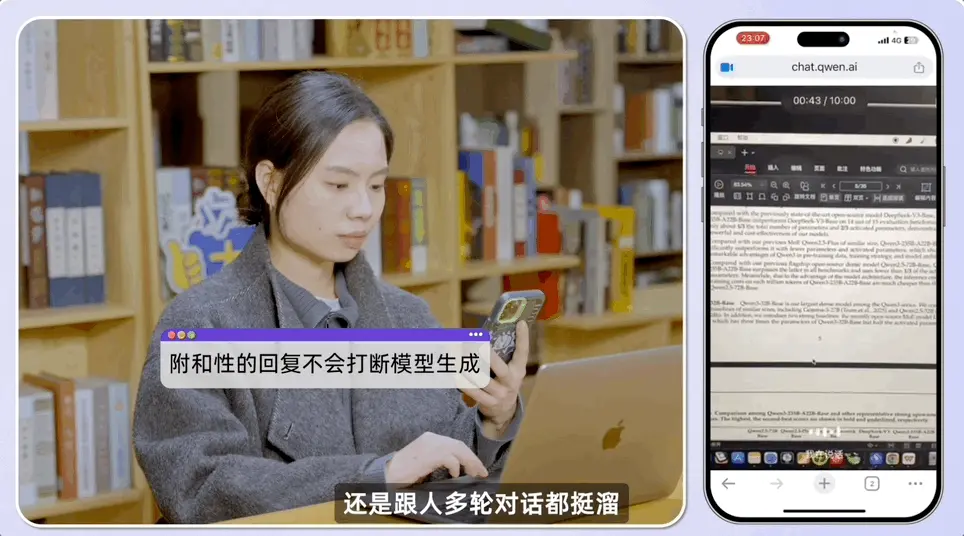
另一个令人印象深刻的演示是歌词字幕生成:一首糅合了多种方言的 rap 被送入模型,输出是带精确时间戳的逐句歌词。并且没有「翻译」的调整,比如在识别粤语歌词时,返送的就是粤语行文,没有自作主张转换成普通话。Qwen3.5-Omni 支持 113 种语言的语音识别和 36 种方言的语音生成,这个覆盖面本身就是一个值得注意的信号。
模型在海量文本、视觉以及超过1亿小时的音视频数据上进行原生多模态预训练。相比上一代 Qwen3-Omni,多语言能力大幅增强:语音识别从此前的版本跃升至 113 种语言,语音生成覆盖 36种方言。
最出人意料的一组演示来自 Qwen 团队称为「Audio-Visual Vibe Coding」的能力。
第一个案例:用户展示一段音乐游戏的视频,模型观察游戏画面和音效后,直接生成可运行的游戏代码。不是描述游戏逻辑,而是写出代码。
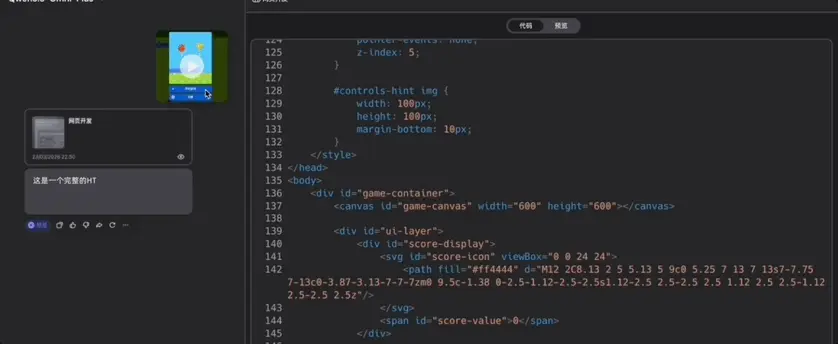
第二个案例更接近实际产品开发:用户展示一个产品原型的演示视频,模型将视觉设计和交互逻辑转化为前端代码。
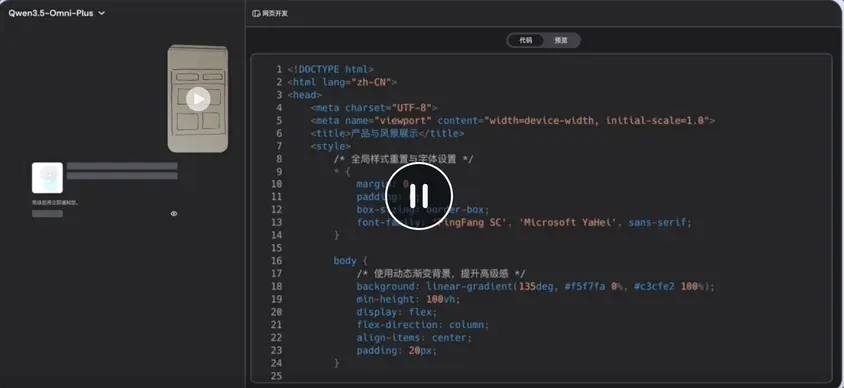
Qwen 团队在技术报告中指出,这种「看视频写代码」的能力并不在模型的训练目标中——它是原生多模态 Scaling 过程中涌现出来的。当视觉、听觉和语言的表征被联合训练到足够深度时,模型自发地学会了在模态之间建立因果关系,而不仅仅是相关性。
支撑这些能力的,是 Qwen3.5-Omni 的 Hybrid-Attention MoE 架构,在同一潜空间内联合训练所有模态的 token。这意味着模型在「思考」时,文字、图像、声音是同一种东西,不存在模态间的翻译损耗。
以往的语音大模型要么思考慢但回答深,要么响应快但内容浅。但今天 Qwen 发布的这些演示视频,比任何 benchmark 数字都更能说明,全模态 AI 在 2026 年能做到什么。
文章来自于微信公众号 "APPSO",作者 "APPSO"


【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
