# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。
这催生出一个与语言模型 “思维链”(Chain-of-Thought, CoT)相对应的新概念 ——Chain-of-Frame(CoF)。其核心思想是:模型通过逐帧生成视频,以连贯的视觉推演方式逐步解决问题。然而,一个关键疑问仍未解决:这些模型是否真正具备零样本推理(Zero-Shot Reasoning)的能力?抑或它们只是在模仿训练数据中出现过的表面模式?
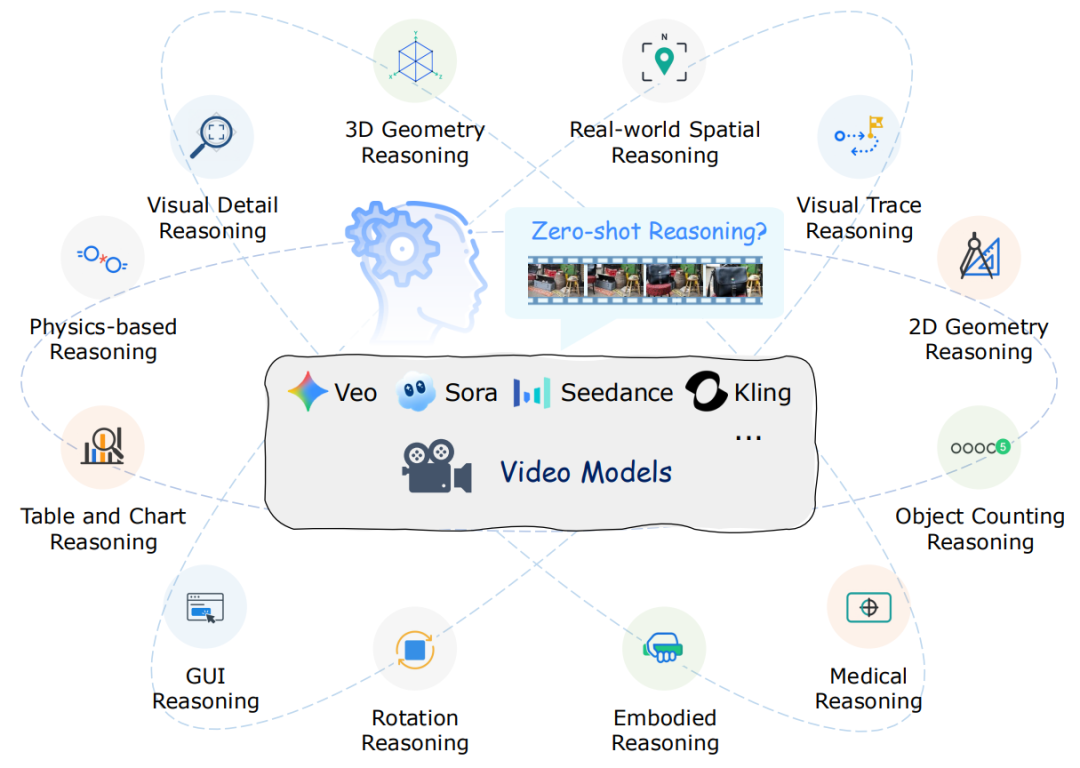
为探究这一问题,来自香港中文大学、北京大学、东北大学的研究团队进行了系统性研究,对 Veo 3 等模型的零样本推理潜力进行了深入评估,并提出了涵盖空间、几何、物理、时间等 12 个推理维度的综合测试基准 ——MME-CoF。

“帧链推理” 可以视作语言中 “思维链”(CoT)的视觉类比:
为全面揭示视频模型的推理潜力,研究团队设计了 12 个维度的测试任务,对 Veo 3 进行了系统的实证分析。以下选取其中三个典型维度进行说明(其余部分可参阅原论文)。



除上述三项外,其余九个维度同样揭示了 Veo 3 的限制:
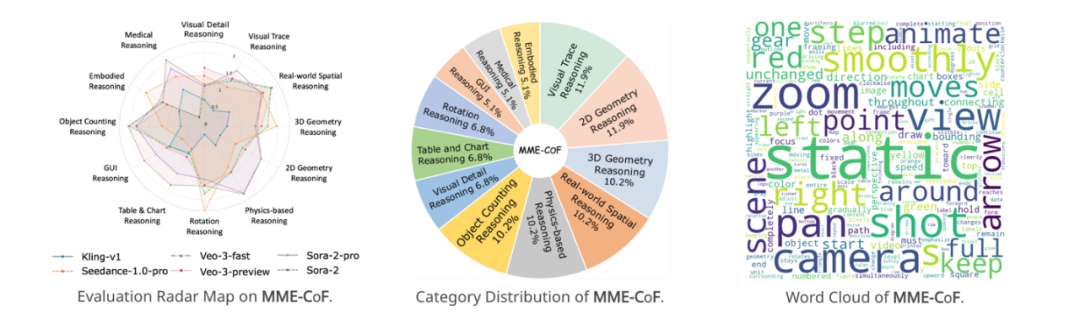
研究团队基于上述实证研究整理了 MME-CoF 基准,以标准化方式评估视频模型的推理潜能。其主要特征包括:
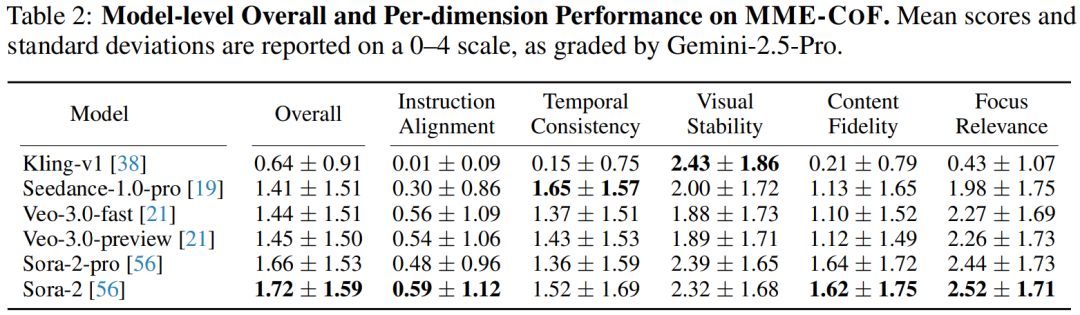
下表展示了多种视频生成模型在 MME-CoF 基准上的评测结果,评分由 Gemini-2.5-Pro 完成,量表范围为 0–4。研究团队从五个维度进行评估。整体来看,各模型的平均得分普遍低于 2 分。
综合 Veo 3 的实证分析,基于对众多视频模型的定量评估结果,研究者得出以下结论:
1. 尚不具备独立的零样本推理能力 —— 模型主要依赖数据模式,而非逻辑推演。
2. 强生成 ≠ 强推理 —— 其表现更多来自模式记忆与视觉一致性,而非概念理解。
3. 注重表象而非因果 —— 模型生成的结果往往 “看起来对”,但逻辑上并不成立。
4. 未来仍具潜力 —— 可作为视觉推理系统的有力补充模块,与逻辑模型协同构建更完整的多模态智能体系。
总体而言,这项研究为学界提供了清晰系统的实证分析和评估框架,揭示了视频生成模型在从 “生成” 迈向 “推理”、实现真正的 “通用视觉模型” 的过程中尚需跨越的关键鸿沟。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
