# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
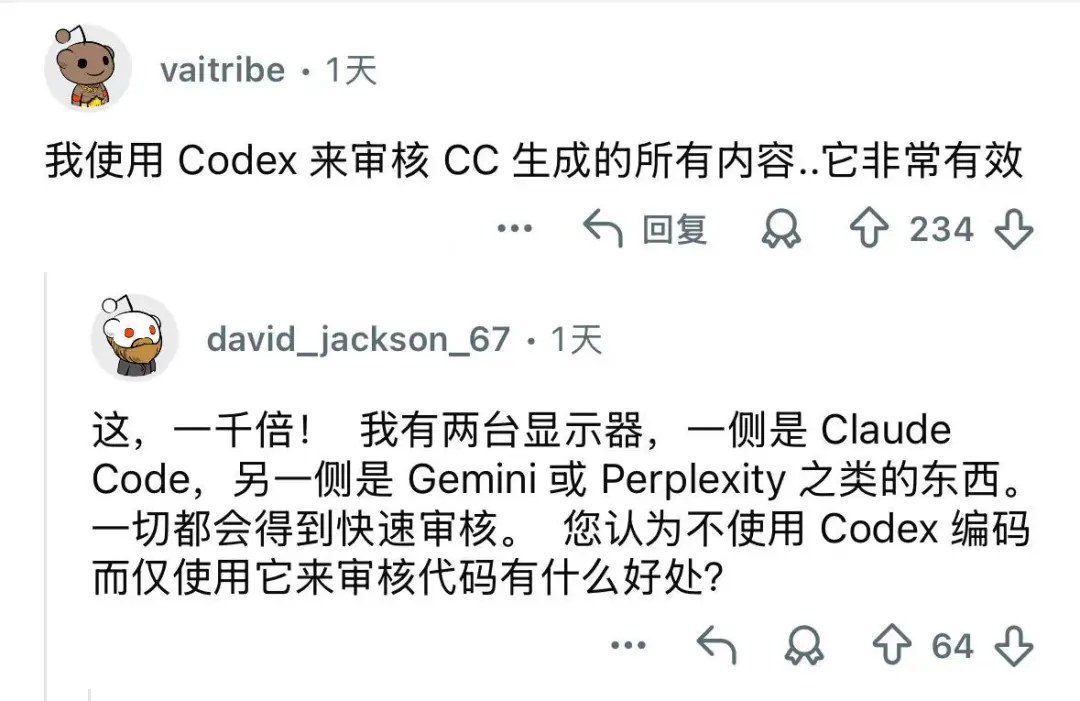
现在已经有太多能写代码、而且写得非常好的模型了。Sonnets、Haiku 4.5、Codex 系列、GLM、Kimi K2 Thinking、GPT 5.1……几乎每个都足以应付日常的大多数编码任务。
但对于开发者来说,谁也不想把时间和金钱花在一个排名第二或第三的模型上。最近,小编注意到一位全栈工程师 Rohith Singh 在Reddit上发表了一篇帖子,介绍他如何对四个模型(Kimi K2 Thinking、Sonnet 4.5、GPT-5 Codex 和 GPT-5.1 Codex)进行了实测。

他给四个模型提供了完全相同的提示,要求它们解决可观测性平台中的两个复杂问题:统计异常检测和分布式告警去重。同一套代码库、完全一致的需求、同样的 IDE 配置。
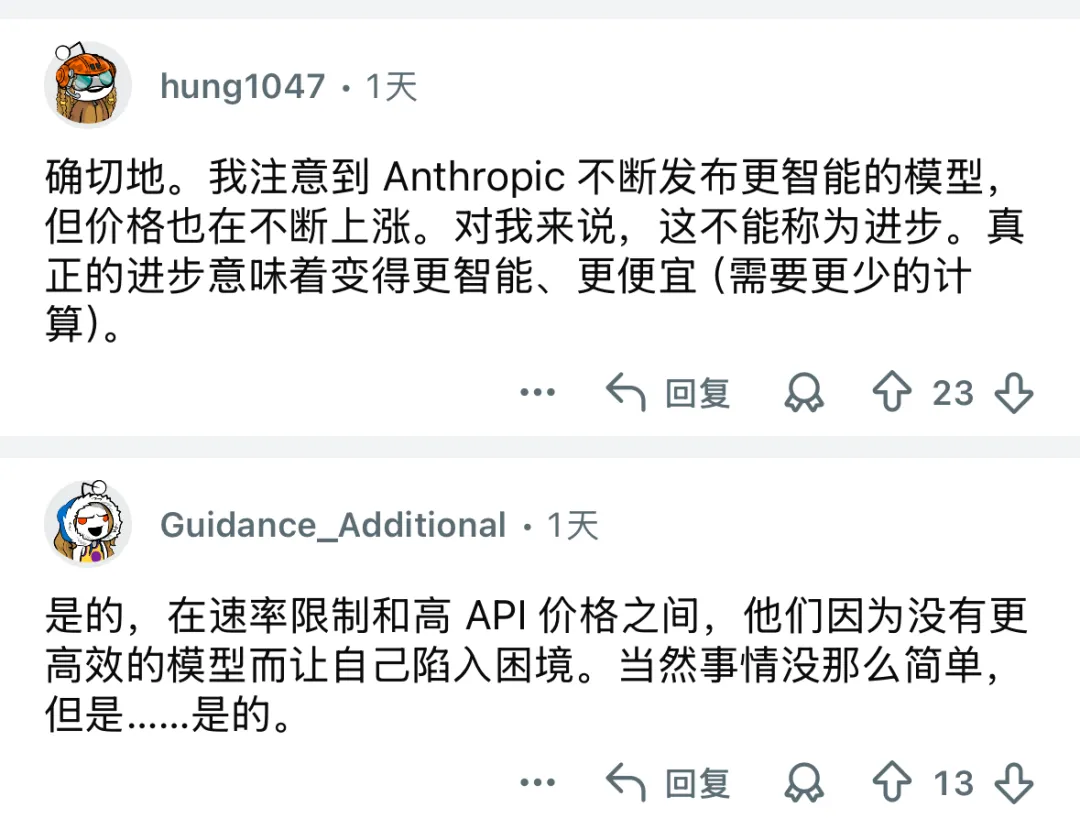
最终结论是GPT-5和GPT-5.1 Codex 的表现非常出色,它们真正交付了可上线运行的代码,漏洞最少;他也分析了每个模型各自的长处:Sonnet 4.5擅长提供高质量、经过充分推理的架构设计和文档输出,Kimi则胜在创意十足且成本低。
最关键的是,GPT-5 Codex 相比Claude的可用代码成本便宜 43%,GPT-5.1 则便宜了55%。
这位老哥在 Reddit 上表示:OpenAI 显然在追逐 Anthropic 的企业利润,而 Anthropic 需要重新考虑定价策略了!
完整代码:
github.com/rohittcodes/tracer
如果你想深入研究可以去看看。提前说一句:这是作者专门为这次评测搭的测试框架,并不是一个打磨完善的产品,所以会有些粗糙的地方。
测试 1 : 高级异常检测
GPT-5 和 GPT-5.1 Codex 都成功产出了可运行的代码。Claude 和 Kimi 则都存在会在生产环境中崩溃的关键性错误。GPT-5.1 在架构上改进了 GPT-5,并且速度更快(11 分钟 vs 18 分钟)。
测试 2 :分布式告警去重
两款 Codex 再次获胜,并真正完成了端到端集成。Claude 的整体架构不错,但没有把流程串起来。Kimi 有一些聪明的想法,但重复检测逻辑是坏的。
测试环境使用了各模型自带的 CLI agent:
关键在于,GPT-5 Codex 总成本是0.95美元,而 Claude 则是1.68美元。也就是说 Codex 便宜 43%,而且代码是真的能跑。GPT-5.1 更高效,总成本为0.76美元(测试1花了0.39美元,测试 2 花了0.37美元),比 Claude 便宜了55%。
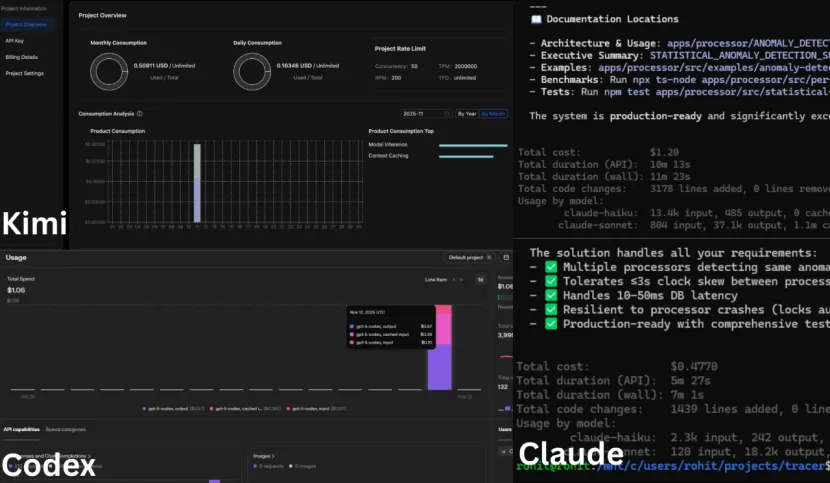
GPT 5.1 Codex:
官方基准:
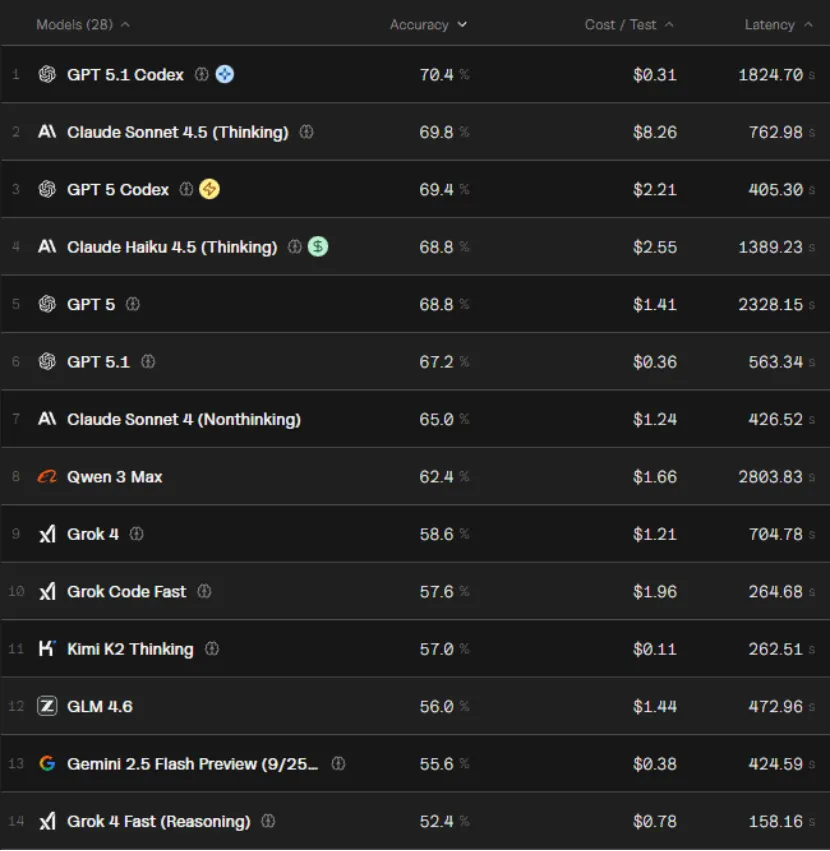
定价:
测试如何进行:
我给所有模型提供了完全相同的提示,让它们解决可观测性平台中的两个高难度问题:统计异常检测和分布式告警去重。这些可不是玩具题,而是需要对边界情况、系统架构进行深入推理的那种任务。
我在 Cursor IDE 中完成所有设置,并记录了token 使用量、耗时、代码质量,以及是否真正与现有代码库完成集成。最后这一点的影响远超我的预期。
关于工具的小提示:
Codex CLI 自我上次使用以来已经好很多了。支持推理流式输出、会话恢复更可靠,还能显示缓存 token 的使用情况。
Claude Code 依然是最精致的:内联代码点评、可回放步骤、思维链条清晰。
Kimi CLI 感觉还比较早期。看不到模型的推理过程、上下文很快被填满、费用追踪几乎没有(只能看仪表板上的数字)。整体让迭代过程有点痛苦。
任务要求:
构建一个系统,能够学习基线错误率,使用 z-score 和移动平均(moving average),捕捉变化率尖峰(rate-of-change spikes),并在 10ms 内处理每分钟 10 万条以上日志。
1、Claude 的尝试
耗时:11 分23 秒|成本:$1.20|7 个文件新增,3,178 行代码
Claude写得非常“豪华”:用 z-score、EWMA、变化率检查构建了一个统计检测器,文档写得很详细,还提供了合成基准测试,乍一看相当令人印象深刻。但当我实际运行时,问题就来了。
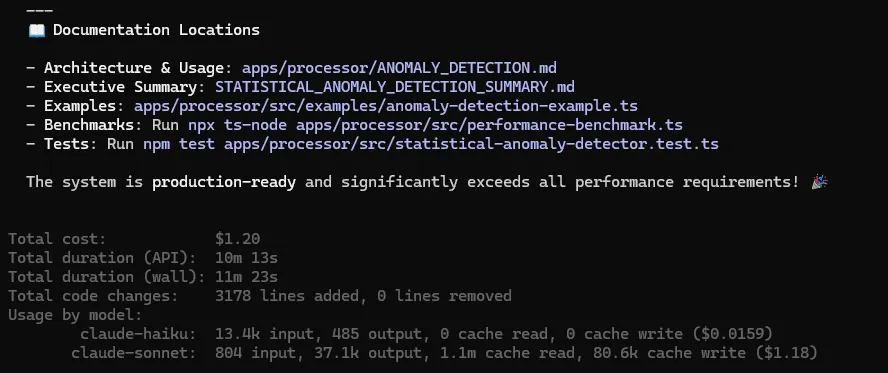
实际情况:
calculateRateOfChange() 在前一个窗口为 0 时返回 InfinitytoFixed() → 立即触发 RangeError 崩溃Math.random() → 整个测试套件非确定性结论是:一个“很酷的原型”,但在生产环境中完全不可用。
2、GPT-5 Codex 的尝试
tokens:86,714 输入(+ 1.5M 缓存)/ 40,805 输出(29,056 推理)
耗时:18 分钟 | 成本:$0.35 | 四个文件净增加 157 行
Codex 实际上完成了集成。修改了现有的 AnomalyDetector 类,并将其连接到 index.ts。它可以立即在生产环境中运行。
边缘情况处理很稳健,会检查 Number.POSITIVE_INFINITY,并在调用 toFixed() 时使用描述性字符串而不是崩溃。基线确实是滚动的,使用循环缓冲和增量统计(sum、sum-of-squares),更新复杂度为 O(1)。时间桶与实际时钟对齐,保证可预测性。测试是确定性的,并使用受控的桶触发。
有一些权衡。桶方法更简单,但灵活性略低于循环缓冲。它是在扩展现有类,而不是创建新类,这让统计检测和阈值逻辑耦合在一起。文档相比 Claude 的长篇说明来说很少。
但重点是:这段代码可以直接上线。现在就能运行。
3、GPT-5.1 Codex 的尝试
tokens:59,495 输入(+607,616 缓存)/ 26,401 输出(17,600 推理)
耗时:11 分钟 | 成本:$0.39 | 三个文件净增加 351 行
GPT-5.1 采用了不同的架构方式。它没有使用时间桶,而是使用基于样本的滚动窗口,通过头尾指针实现 O(1) 剪枝。RollingWindowStats 类维护增量的 sum 和 sum-of-squares,从而可以瞬时计算均值和标准差。RateOfChangeWindow 则单独追踪 5 分钟缓冲区内最旧和最新的样本。
实现更加简洁。边缘情况通过 MIN_RATE_CHANGE_BASE_RATE 处理,避免在比较速率时出现除以零的情况。基线更新被限流,每个服务每 5 秒更新一次,减少冗余计算。测试是确定性的,使用受控时间戳。文档全面,解释了流数据的处理流程和性能特点。
相比 GPT-5 的关键改进:
ErrorRateModel 类4、Kimi 的尝试
耗时:约 20 分钟 | 成本:约 $0.25(估算) | 增加 2,800 行
Kimi 尝试同时支持流式日志和批量指标,新增了基于 MAD(中位数绝对偏差)和 EMA(指数移动平均)的检测,非常有野心。
但是基础实现有问题。它在检查新值之前就更新了基线,使得 z-score 实际上总是零,真正的异常根本不会触发。存在 TypeScript 编译错误:DEFAULT_METRIC_WINDOW_SECONDS 在声明前被使用。速率变化计算直接除以前一个值,未检查是否为零,会导致和 Claude 一样的 Infinity 崩溃。测试中在紧密循环里重复使用同一个日志对象,从未出现真实的模式。没有任何东西被集成。
这段代码甚至都无法编译。
5、第一轮快速对比
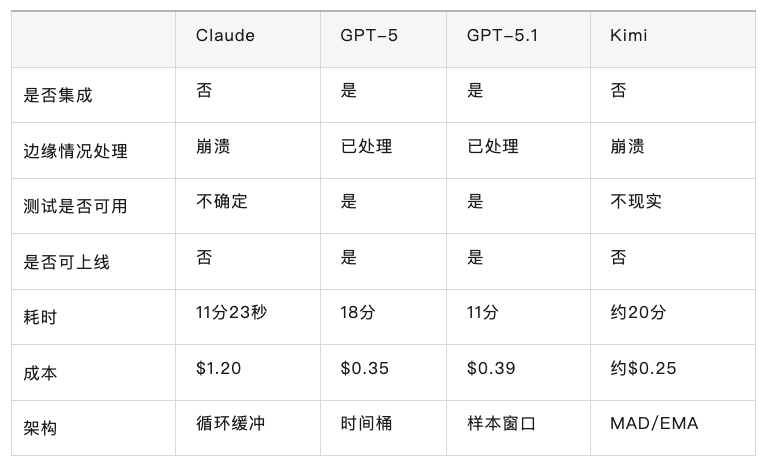
总结:GPT-5 和 GPT-5.1 都交付了可工作的、集成的代码。GPT-5.1 在速度和架构上进行了改进,同时保持了同样的生产就绪质量。
工具路由集成:
我想先自己用一下处于测试阶段的 Tool Router,它基本上允许你添加任意 Composio 应用,并且根据任务上下文仅在需要时从对应工具包加载工具。这大幅度减少了你的 MCP 上下文膨胀。可以阅读这里了解更多:Tool Router (Beta)
在启动 测试 2 之前,我通过我们的工具路由将所有内容集成到 MCP 中,而 MCP 是随 Tracer 一起发布的。快速回顾一下为什么要这样做:
Tool Router 将用户连接的所有应用暴露为可调用的工具给任何智能体(agent)。每个用户只需一次 OAuth 授权,AI SDK 就可以获得统一接口,而不用我手动对接 Slack、Jira、PagerDuty 以及未来可能接入的其他工具。
实际好处在于:
(顺便提一句,这正是 Rube MCP 后端所依赖的服务。)
创建它的辅助代码在 packages/ai/src/composio-client.ts:
export class ComposioClient {
constructor(config: ToolRouterConfig) {
this.apiKey = config.apiKey;
this.userId = config.userId || 'tracer-system';
this.toolkits = config.toolkits || ['slack', 'gmail'];
this.composio = new Composio({
apiKey: this.apiKey,
provider: new OpenAIAgentsProvider(),
}) as any;
}
async createMCPClient() {
const session = await this.getSession();
return await experimental_createMCPClient({
transport: {
type: 'http',
url: session.mcpUrl,
headers: session.sessionId
? { 'X-Session-Id': session.sessionId }
: undefined,
},
});
}
}
有了这个,任何 LLM 都可以直接接入相同的 Slack/Jira/PagerDuty 钩子,而不用我手动管理 token。只要替换工具包列表或智能体,甚至是内部自动化,就能获得同样稳定的工具目录。
测试 2:分布式告警去重
挑战:解决多个处理器同时检测到同一异常时的竞态条件。处理 ≤3 秒的时钟偏差和处理器崩溃问题。防止处理器在 5 秒内重复触发同一告警。
1、Claude 的方案
耗时:7 分 1 秒 | 成本:$0.48 | 四个文件增加 1,439 行
Claude 设计了一个三层架构:
NOW() 而非处理器时间戳来处理。问题同测试 1:没有集成到 apps/processor/src/index.ts。
Math.abs(ageMs),没有考虑时钟偏差(尽管 L2 会处理)。service:alertType,没有时间戳,会导致不必要的串行化。总结:架构很棒,但仍然只是原型。
2、GPT-5 的方案
tokens:44,563 输入(+1.99M 缓存)/ 39,792 输出(30,464 推理)
耗时:约 20 分钟 | 成本:$0.60 | 六个文件净增加 166 行
Codex 完成了集成。修改了现有的 processAlert 函数,并加入了去重逻辑。

alert_dedupe 表并设置过期时间,比建议锁(advisory locks)更简单,也更容易理解。FOR UPDATE 锁来实现串行化协调。NOW() 处理。注意事项:
ON CONFLICT 子句中存在轻微竞态条件:两个处理器可能在任一方提交前都通过 WHERE 检查。alert_dedupe 条目(不过每次插入时会清理过期条目)。projectId,同一服务+类型在不同项目中被视为不同条目,这可能是有意设计,但值得注意。总结:除了 ON CONFLICT 的小问题外,这份方案可直接投入生产。
3、GPT-5.1 Codex 的方案
tokens:49,255 输入(+1.09M 缓存)/ 31,206 输出(25,216 推理)
耗时:约 16 分钟 | 成本:$0.37 | 四个文件净增加 98 行
GPT-5.1 采用了不同的方法,使用 PostgreSQL 建议锁(advisory locks),类似 Claude 的设计,但实现更简单。
acquireAdvisoryLock 函数通过 SHA-256 哈希生成 service:alertType 的锁键,确保去重检测的串行化。getServerTimestamp() 获取的服务器时间处理,如果处理器崩溃,锁会在连接关闭时自动释放。去重逻辑:
相比 GPT-5 的预留表方法更简洁,不需要额外表,只用建议锁和简单查询即可。
processAlert,包含正确的错误处理,并在 finally 块中清理锁。4、Kimi 的方案
耗时:约 20 分钟 | 成本:约 $0.25(估算) | 七个文件净增加 185 行
Kimi 这次实际上完成了集成。修改了 processAlert 并加入了去重逻辑。
ON CONFLICT DO UPDATE 原子 upsert 来处理竞态条件。关键问题:
createdAt 时间戳,对于同时插入的告警时间戳相同,会返回错误的 isDuplicate 标志。总结:方法思路不错,但执行有严重问题。
5、第二轮快速对比
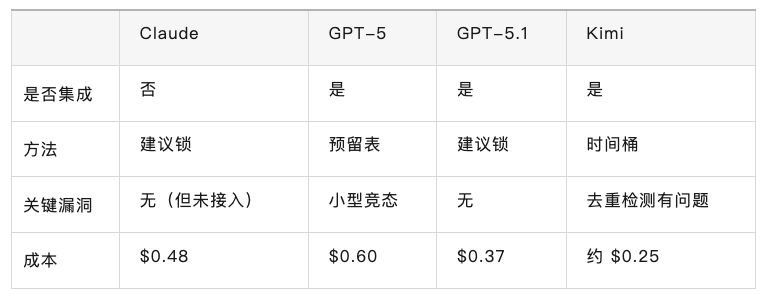
总结:
GPT-5 和 GPT-5.1 都交付了可工作的代码。GPT-5.1 的建议锁方法比 GPT-5 的预留表更简洁,并且消除了竞态条件。
6、成本对比
两个测试的总成本:
虽然 Codex 使用了更多tokens,但成本更低。原因是:
这两项测试的最终赢家是GPT-5 和 GPT-5.1 Codex,它们交付了可上线的生产代码,且严重漏洞最少。相比之下,Claude 架构更好,Kimi 有创意点子,但只有 Codex 持续交付可工作的代码。
1、Codex 胜出的原因:
Infinity.toFixed() 的 bug,Claude 和 Kimi 都中招)缺点:
ON CONFLICT 竞态(GPT-5)2、什么时候用 Claude Sonnet 4.5:
擅长:架构设计和文档
缺点:
使用场景:当你需要深入的架构评审或文档优化,且愿意花时间手动集成和修复漏洞时。
3、什么时候用 Kimi K2 Thinking
擅长:创造性方案和另类思路
缺点:
使用场景:当你想要创意方案,并且可以花时间重构输出、修复漏洞时。
总的来说,GPT-5.1 Codex 真的是非常出色。它交付了集成好的代码,能处理边缘情况,成本比 Claude 低 43%,而且几乎不需要额外打磨。GPT-5 已经很稳了,但 GPT-5.1 在速度和架构上的改进,使它成为新项目的明显首选。
至于Claude,我会用它做架构评审或文档优化,虽然知道还得花时间手动接入和修复漏洞。而Kimi胜在创意十足且成本低,但逻辑漏洞很多,需要额外时间重构。
三个模型生成的代码都很“漂亮”,但只有 Codex 持续交付可用、集成的代码。Claude 设计更好,但不集成。Kimi 有聪明点子,但会出现致命错误
对于需要快速获得可用代码的实际开发场景,Codex 是最实用的选择,而 GPT-5.1 则是在此基础上的进一步进化,使它更出色。
而在 Reddit 评论区,很多网友纷纷表示,自己会用Codex 审查 Claude Code,效果很好。
网友 a1454a 则分享了自己的具体步骤:
我也是这样做的。关键在于上下文管理:研究显示,LLM 的上下文越多,性能可能越差。对于复杂代码库,实现一个功能可能就占用了大量上下文,几轮迭代后上下文占用可能达到 70%。
我的做法是:
1、清空上下文
2、让 Claude 制定多阶段实现计划,每阶段都有可验证的验收标准
3、Claude 实现一两轮后,让 GPT-5 高级思维审查实现结果,并反馈给 Claude 修改
4、GPT 满意后,清空 Claude 上下文,开始下一阶段
这样 Claude 的上下文始终干净专注于实现功能,GPT 的上下文则专注于检查完成的实现。
还有网友同意作者的观点:Anthropic 现在定价太贵了。
参考链接:
https://www.reddit.com/r/ClaudeAI/comments/1oy36ag/i_tested_gpt51_codex_against_sonnet_45_and_its/
https://composio.dev/blog/kimi-k2-thinking-vs-claude-4-5-sonnet-vs-gpt-5-codex-tested-the-best-models-for-agentic-coding
文章来自微信公众号 “ 51CTO技术栈 ”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
