# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI音效已经进化成这样了吗??
打开声音🦻,来快速感受一下最新feel:
模拟婴儿哭声,那叫一个高低起伏、荡气回肠,整个节奏和婴儿表情姿态神同步了。

一辆火车由远及近驶来,整个背景音也颇具空间层次感,毫不违和。

甚至连小号这种乐器演奏,声音也能和演奏者的动作一一对上。

没错,这就是阿里通义语音团队最新开源的泛音频生成模型ThinkSound,主要用于视频配音,主打让每一帧画面都有专属匹配音效。
据介绍,它首次将今年大热的CoT思维链推理引入了音频领域,解决了传统视频配乐技术往往只能生成单调的背景音,而难以捕捉画面中的动态细节和空间关系的难题。
就是说,AI现在也能像专业音效师一样逐步思考,通过捕捉视觉细节来生成音画同步的高保真音频。

官方测评显示,ThinkSound在业界知名的音视频数据集VGGSound上,对比6种主流方法(Seeing&Hearing、V-AURA、FoleyCrafter、Frieren、V2A-Mapper和MMAudio),在核心指标上均实现了显著提升。
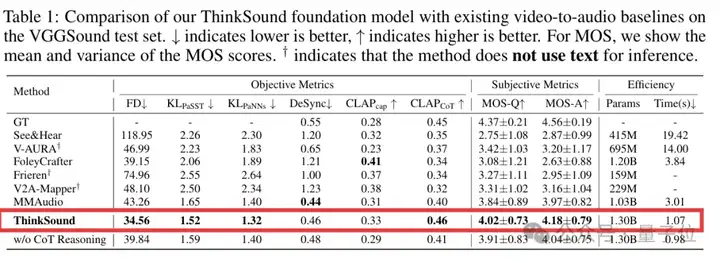
p.s. ↓ 表示越低越好,↑ 表示越高越好
目前ThinkSound一共有三种型号(1.3B、724M、533M)可选,开发者可在GitHub、HuggingFace、魔搭社区下载体验。
为什么需要“会思考”的音频生成模型?
其实这主要是因为,现有端到端视频-音频(V2A)生成技术难以捕捉音画细节。
比如对于猫头鹰何时在轻声啾啾、何时振翅准备起飞,或者树枝在振动时发出的轻微摩擦声,由于缺乏对视觉—声学细节的深入理解,生成的音频往往显得过于通用,有时甚至会出错,导致音画不匹配。
而引入链式思维(CoT)推理后,整个过程可以拆解为:先分析视觉动态、再推断声学属性,最后按照时间顺序合成与环境相符的音效。
这一模仿人类音效师的多阶段创作流程,能精准建立起声音和画面之间的对应关系。
一言以蔽之,正如推理能力能提升语言模型的回答质量,CoT也能增强AI生成音效的真实感与同步性。
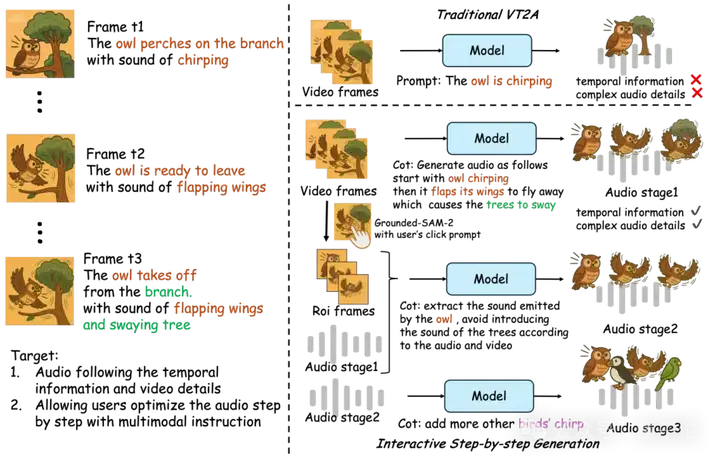
从更多生成结果也能看到,当音频模型懂得“思考”后,音画同步这事儿也就变得更加简单了。
玩法也很easy,用户仅需上传一段视频,模型就能自动“按帧匹配音效”——
给一段Sora模型生成的视频,各种地上跑的、水里游的都能一键自动生成音效,仔细听还能发现真实的环境噪音。

值得一提的是,理论上ThinkSound不限制上传视频的时长,但考虑到生成效果,当前团队建议最佳视频时长为10s。
那么,链式思维推理具体如何发挥作用的呢?概括而言,ThinkSound拥有两大核心模块:
基于以上模块,实现了一个三阶思维链驱动的音频生成过程。
按照团队介绍,这一过程核心面临两个挑战:
如何构建符合预期的CoT?以及如何将CoT有效地注入到音频流匹配模型中?
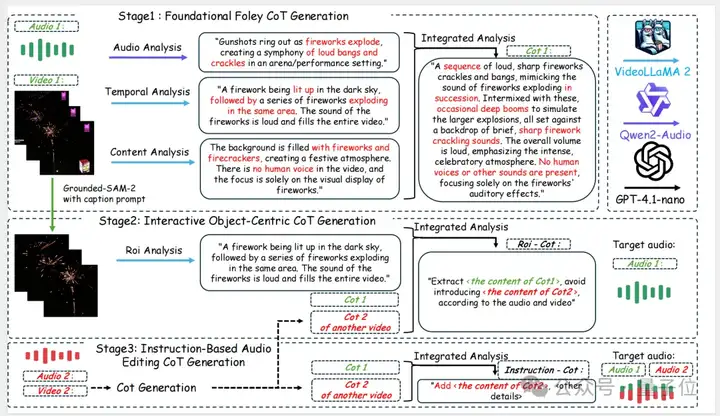
第一阶段,基础音效推理链构建(Foundational Foley CoT Generation)。
首先,ThinkSound会同时分析音频和视频,从声音、时间顺序和内容三个角度理解发生了什么。
具体而言,团队首先通过VideoLLaMA2生成CoT推理链,分别提取画面中的运动动态(如猫头鹰振翅瞬间)与场景语义(如夜晚森林环境)。
然后结合Qwen2-Audio生成的初步音频描述,由GPT-4.1-nano输出结构化的CoT步骤,确保推理包含事件识别、属性推断与因果顺序,为后续合成模块提供时空对齐精度。
第二阶段,面向交互的对象级推理链构建(Interactive Object-Centric CoT Generation)。
接下来用户可以点击视频里的某个部分,ThinkSound会找出视频中具体的声音来源区域(如烟花、鸟、车等),进行单独分析。
这时会用到Grounded SAM-2(开源视频目标定位与追踪框架),来标注并跟踪视频中的“感兴趣区域”(ROI)。
所谓“感兴趣区域”,是指视频中那些可能发出声音或与音频内容紧密相关的可见对象或区域,如一只正在叫的猫头鹰(←ROI)对应着猫头鹰鸣叫。
之后再把这些区域与原始声音对照,分析具体哪一部分该保留、哪一部分是干扰;并融合其他视频的CoT信息,辅助判断应该怎么处理音频。
第三阶段,基于指令的音频编辑推理链构建(Instruction-Based Audio Editing CoT Generation)。
最后用户可以一句话(如“加点爆炸声”“去掉人声”)下达编辑指令,ThinkSound将根据原始音频和推理链,执行编辑操作。
具体而言,它把指令与当前音频对应的推理链进行融合,利用GPT-4.1-nano生成一套结构化的音频编辑步骤。
最终,所有CoT指令都会被传递给统一音频基础模型,该模型基于条件流匹配 (conditional flow matching) 技术实现高保真音频合成。
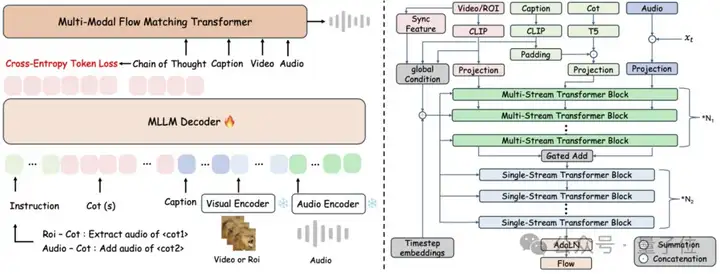
简单来说,在音频生成的底层实现上,ThinkSound采用了一种结合视觉、语言和上下文信息的多模态流式建模方法。
就是说,它能同时理解视频画面、文字描述和声音上下文,并将这些信息融合起来,以逐步生成真实自然的音效。
与此同时,团队还专门为ThinkSound构建了一个链式音频推理数据集——AudioCoT。
数据集主要包括两大类,时长总计2531.8小时:
第一类:源自VGGSound (453.6小时) 和AudioSet (287.5小时),经9.1秒固定长度分段、剔除静音片段、并特别排除了含人声片段后精选而来的视频—音频对,涵盖动物鸣叫、机械运转、环境音效等真实场景。
第二类:源自AudioSet-SL (262.6小时)、AudioCaps (112.6小时)、Freesound (1286.6小时) 与BBC Sound Effects (128.9小时),利用多样化的字幕/标签描述加深模型对听觉语义的理解。
有了以上数据后,团队继续通过一套精细的处理流程,来确保模型真正实现音画同步。
这个流程分为三个主要阶段:
总之,借助以上架构和数据集,ThinkSound能同时完成音频生成和编辑任务。
除了在VGGSound上超越6种主流音频生成方法,团队还进行了消融实验。
他们核心验证了两件事:
结果发现,对比单纯的CLIP文本编码和T5链式推理,后者所生成音频的真实感和质量大大提高。
此外,将CLIP的视觉特征和T5的文本推理结合起来,能进一步优化音频的理解和表现。
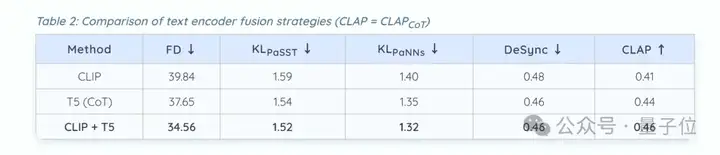
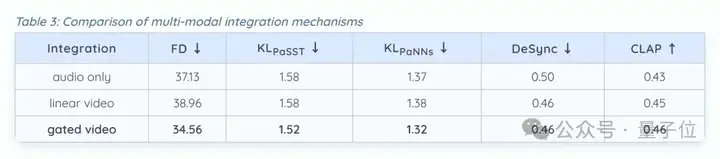
其次,把视频和音频的特征在同一时间点进行对齐和合并,能比单独输入音频更好地同步声音和画面。
而且门控融合(一个智能融合音频和视频特征的机制)能达到最好的效果,它在各个指标上都表现最优。
这项研究来自阿里通义语音团队。
仔细梳理这个团队在语音生成领域的一系列动作,不难发现他们已经在开源社区占据了一席之地。
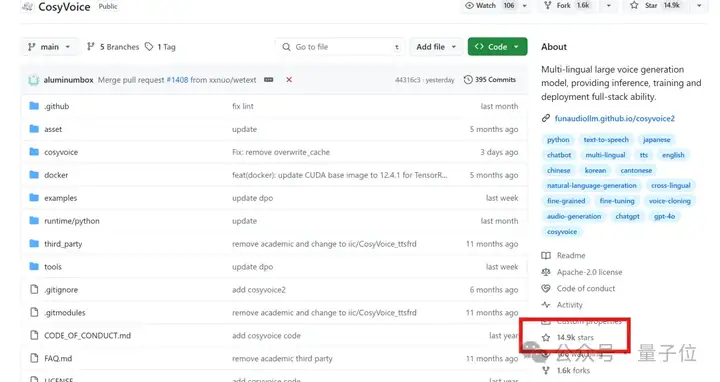
就在上个月,团队发布了语音生成大模型Cosyvoice 3.0,通过大规模数据预训练和特殊设计的强化学习后训练,它能提供多语言语音生成、零样本语音复刻等功能。
加上其1.0、2.0系列,Cosyvoice已在GitHub揽星14.9k,广受开源社区喜爱。
更早之前,团队还推出了基于模态对齐实现的端到端音频多模态大模型MinMo。
它在广泛的音频理解生成类任务,如语音对话、语音识别、语音翻译、情感识别上均获得良好效果,且延迟较低。
相关论文也早已在HuggingFace上公开。

再到这次的ThinkSound,团队依旧延续了开源路线,除了能在几个开源社区体验模型功能,他们后续还计划在完善模型后发布相应API。
最后顺便介绍一下论文作者。
论文唯一一作刘华岱,研究方向为AI音频生成与多模态理解,至今为止在ICML、ICLR、ACL等国际顶级学术会议发表论文十余篇。
其中,他还以一作身份主导了OmniAudio(ICML)、FlashAudio(ACL Oral)、AudioLCM(ACM MM)等开源音频生成工作。

项目主页:
https://thinksound-project.github.io/
论文:
https://arxiv.org/pdf/2506.21448
开源地址:
https://github.com/liuhuadai/ThinkSound
https://huggingface.co/liuhuadai/ThinkSound
https://www.modelscope.cn/studios/AudioGeneral/ThinkSound
文章来自于“量子位”,作者“一水”。


【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
