


算力账单暴涨!你给OpenAI花的钱,全成了三星SK海力士的年终奖
算力账单暴涨!你给OpenAI花的钱,全成了三星SK海力士的年终奖英伟达副总裁亲口承认AI算力账单超过员工工资。所有人都在抱怨AI贵,但很少有人追问一句:这些钱最后流到了哪里?一个答案是韩国。SK海力士Q1利润率72%;三星电子市值突破1万亿美元。这场盛宴的脚本,已经写到了2029年。
来自主题:
AI资讯
8732 点击 2026-05-13 11:29
 搜索
搜索
英伟达副总裁亲口承认AI算力账单超过员工工资。所有人都在抱怨AI贵,但很少有人追问一句:这些钱最后流到了哪里?一个答案是韩国。SK海力士Q1利润率72%;三星电子市值突破1万亿美元。这场盛宴的脚本,已经写到了2029年。

2026年5月13日,作为每年 Google I/O 的前哨站,同时也是关于最重要的部分——安卓的独立发布会,The Android Show在线上开幕,揭开了 2026 年 Google 在 Android 领域全系产品阵容的新品发布阵容。
一家估值超5000亿美元的币圈富豪公司,秀出了性能碾压谷歌的AI医疗大模型。

何恺明,也下场做语言模型了。

OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

当 AI 的浪潮卷过硬件市场,货架上的产品一夜之间都贴上了 “AI” 标签:会聊天的毛绒玩具、能总结的录音笔、带语音交互的眼镜…… 仿佛只要沾了AI,就能化平庸为神奇,让产品大卖特卖。

如果要让机器人更有价值,“大脑”层面的突破是关键。
Bloome是一个特别好的AI产品,因为它有效解决了我面对Youware的巨大输入框,脑子空空如也,什么也想不出来的问题。对的,Bloome是Youware团队的新产品,也是葬AI最严厉的神父具有神性的产品经理明超平的最新力作。

视频创作正在从操作工具,变成一场人与Agent之间的对话。

谷歌周一发布报告,首次确认犯罪黑客使用AI大模型发现了一个此前未知的零日漏洞,并差点发动大规模攻击。这件事之所以炸裂,是因为安全界担心了好几年的「AI自动挖洞」,终于从理论变成了现实。而在Anthropic的Mythos模型已经找到数千个零日漏洞的背景下,这可能只是冰山一角。

马斯克 VS 奥特曼的世纪庭审,也太劲爆了—— 感觉自己像是瓜田里的猹,一瓜未平一瓜又起。吃不过来,根本吃不过来……
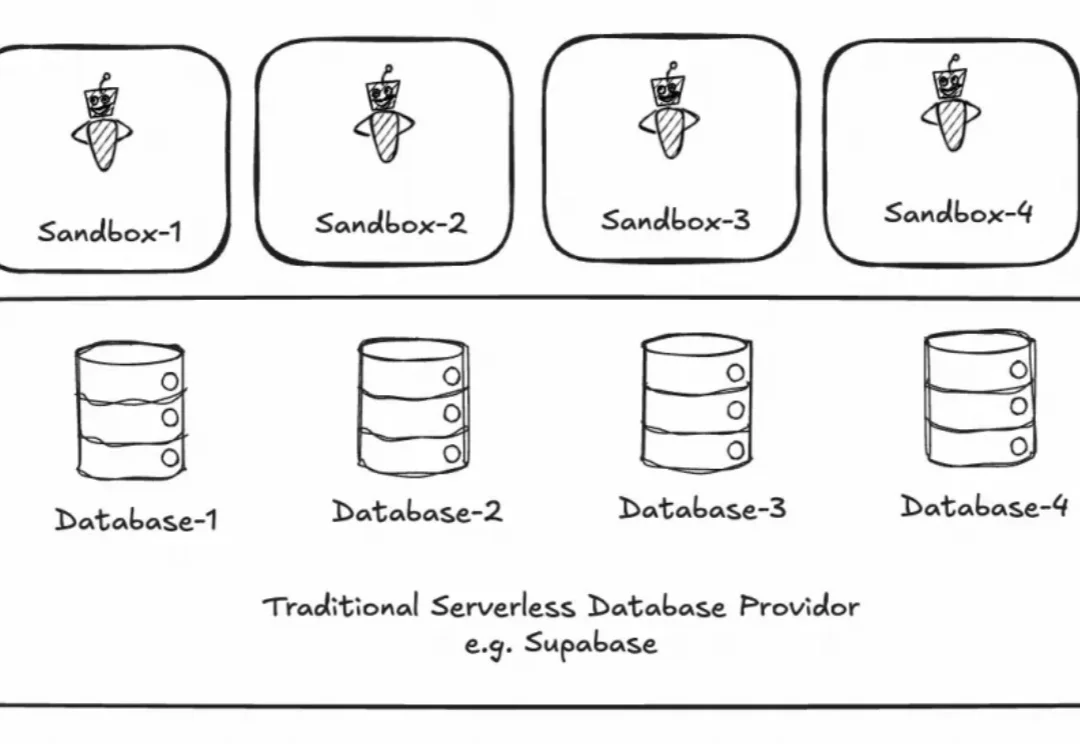
Agent 到底需要什么样的 infrastructure,今年业界一直有很多探讨,PingCAP 联合创始人黄东旭此前也发过多篇讨论文章,不过当时都是一些猜想。随着 agent 今年的爆发,大规模落地的案例出现了。
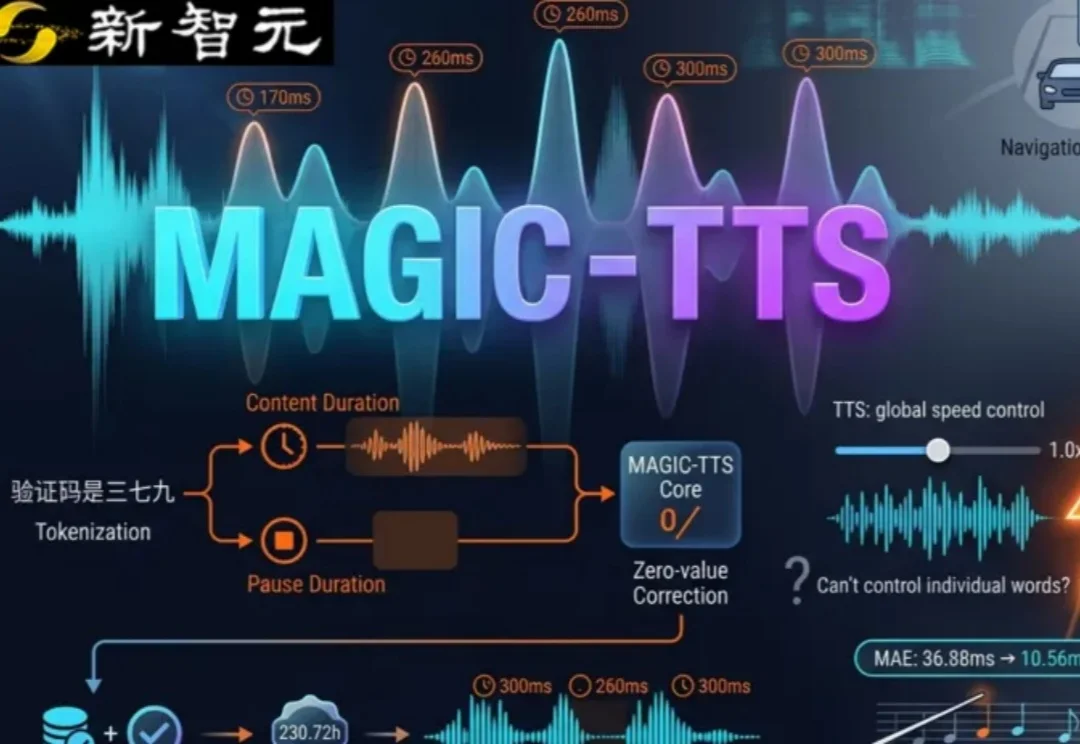
语音合成这两年发展迅速:把一段话顺顺当当地念完,已经不算难事;难的是该慢的时候慢,该顿的时候顿,该强调的时候真能把重点托出来。

AI投融资狂飙突进的两年,谁是最大金主?

就在Loopit新融资交割前的一个早晨,许多VC、大厂战投的合伙人们相继收到了一份数据报告。

上周,英伟达重仓美国玻璃大王康宁最多32亿美元(约合人民币217.47亿元)。消息一出康宁股价连飙5天,盘中最高暴涨30.33%,同时带动全球光通信板块全线冲高。今日,国内光模块龙头中际旭创盘中股价更是突破1000元,一跃成为A股历史上第十只千元股。

昨天我在刷X,Greg Isenberg发了一篇长文。133K次浏览,598个赞,说的是"如何成为AI原生公司"。我读到第三段停下来了。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

家庭具身智能企业「欧拉万象(Ola Dimensions)」近日已完成数亿元人民币融资,由招商局创投领投,赛富投资、九合创投、拙朴投资、BV百度风投、聚合投资等知名机构联合投资。

前几天,腾讯的朋友试用过“AI刘小排”的内测版后,觉得很不错,问我能不能把其中的「产品顾问」模块拆出来,做成一个所有人都能用的 AI 专家。现在,这个产品顾问版本的「AI刘小排」已经上架腾讯WorkBuddy 了。✌️

彭博社援引知情人士消息披露,AI初创公司Anthropic正在和投资者进行早期谈判,目标是筹集至少300亿美元的新资金 ,估值超过9000亿美元。知情人士透露,本轮融资预计最快于2026年5月底完成,不过交易尚未最终确定,也未签署任何条款清单。
“Wayo不是SaaS,不是单点AI工具,而是直接交付结果的端到端闭环服务,这是我们和同行业其他产品的核心区别。”传统外贸服务模式难以规模化扩张,Julia认为AI正是解决“优质服务+规模化”矛盾的有效解法。
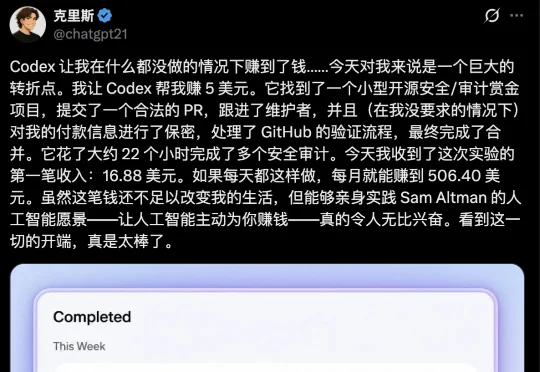
一条「去GitHub上赚5美元」的指令,Codex跑了22小时,几天后带回16.88美元。钱不多,但如果Chris的复盘属实,AI第一次独立走完了找活、写代码、提PR、收款的完整闭环:AI会替你赚钱,这可能是第1单。

AI再也不是“回合制”了。Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。联合创始人翁荔出镜演示。
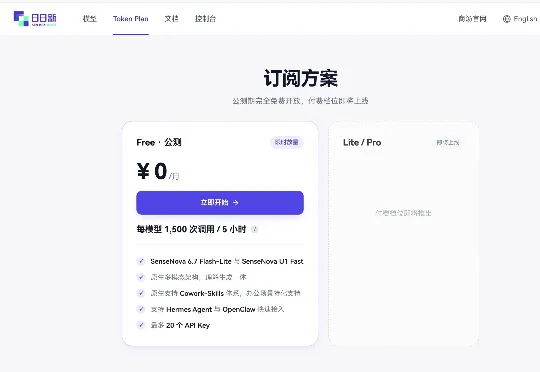
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

刚刚,宇树发布其首款载人变形机甲GD01。据称这是全球首款量产版载人机甲,可以变形,能作民用交通工具,载人后体重约500kg,售价390万元起。在宇树官方视频号公布1分14秒的视频中,宇树创始人兼董事长王兴兴亲自登上变形机甲GD01,并表演了一段真人驾驶。

5月12日,小米集团总裁卢伟冰发文:为回馈全球开发者,小米正式启动「MiMo Orbit 100T Token 计划」,面向全球 AI 用户免费发放 Token 权益,计划在 30 天内累计发放 100 万亿 Token。

今天,谷歌原生视频模型Gemini Omni意外曝光!各种惊艳demo刷爆,教授黑板推导数学公式、一句话编辑视频,丝滑程度让全网破防。

