ICML 2025 | CoTo:让LoRA训练「渐入佳境」,模型融合、剪枝样样精通
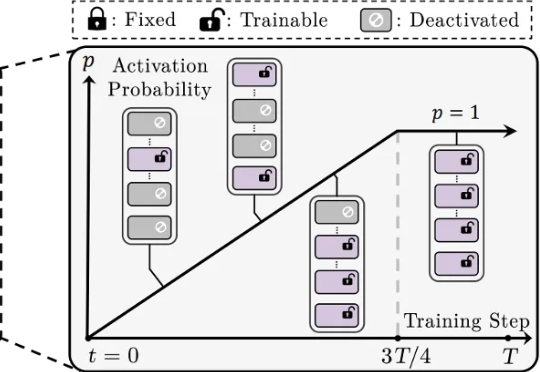
ICML 2025 | CoTo:让LoRA训练「渐入佳境」,模型融合、剪枝样样精通还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。
来自主题:
AI技术研报
7986 点击 2025-07-27 13:12