

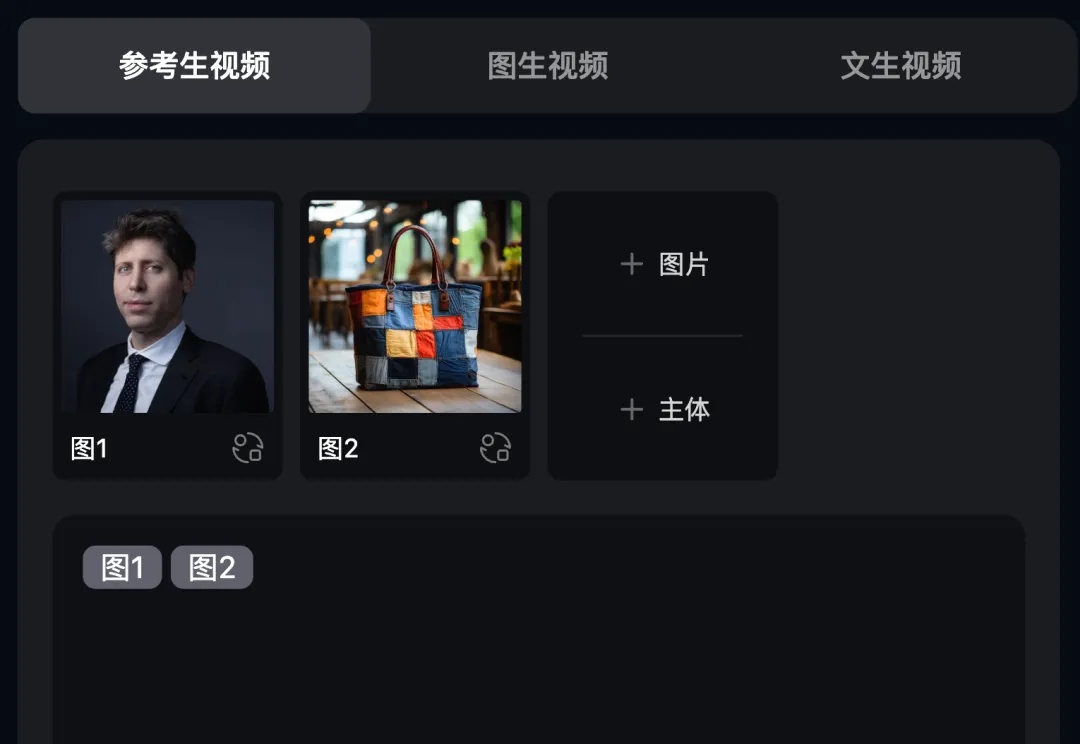
当Sora2遇上国产 Vidu Q2,国产参考生真的更香了!一手亲测
当Sora2遇上国产 Vidu Q2,国产参考生真的更香了!一手亲测国庆假期Sora 2的横空出世那叫一个吸睛,尤其是客串(Cameo)功能,直接把Sora拉到了“AI版抖音”的高度。
来自主题:
AI产品测评
11659 点击 2025-10-13 11:36
 搜索
搜索
国庆假期Sora 2的横空出世那叫一个吸睛,尤其是客串(Cameo)功能,直接把Sora拉到了“AI版抖音”的高度。

最近看到一个有趣的现象:很多人对AI生成的内容有一种本能的抗拒,觉得AI正在"污染"互联网,到处都是没有灵魂的机器文字。
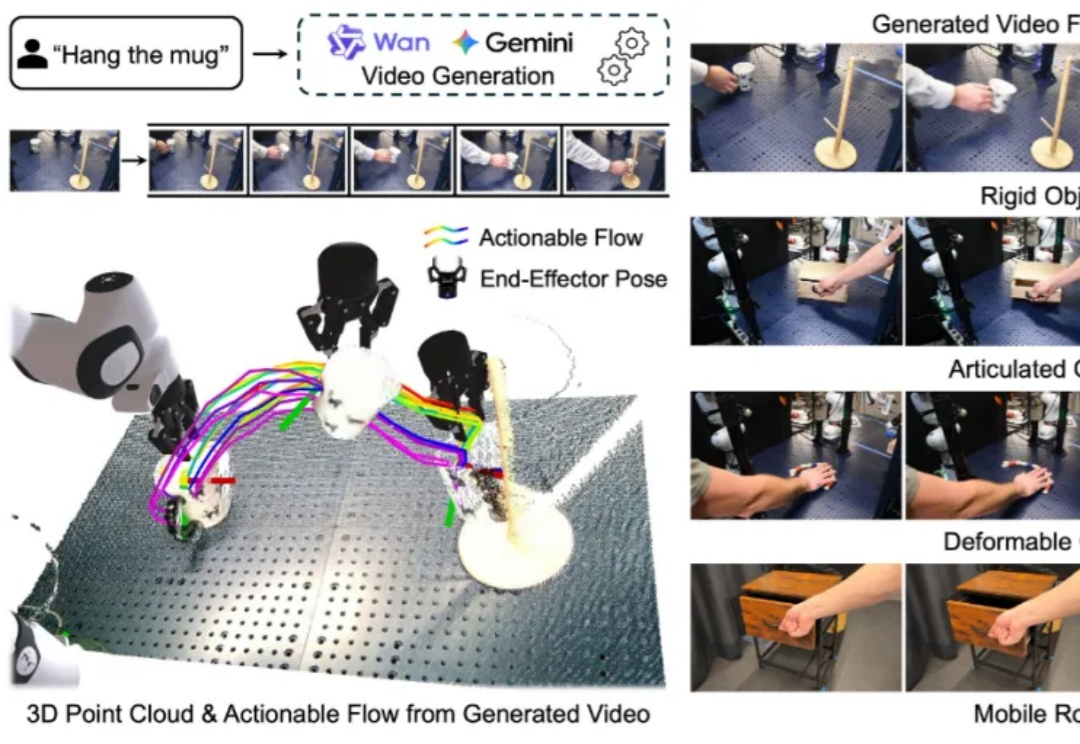
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。
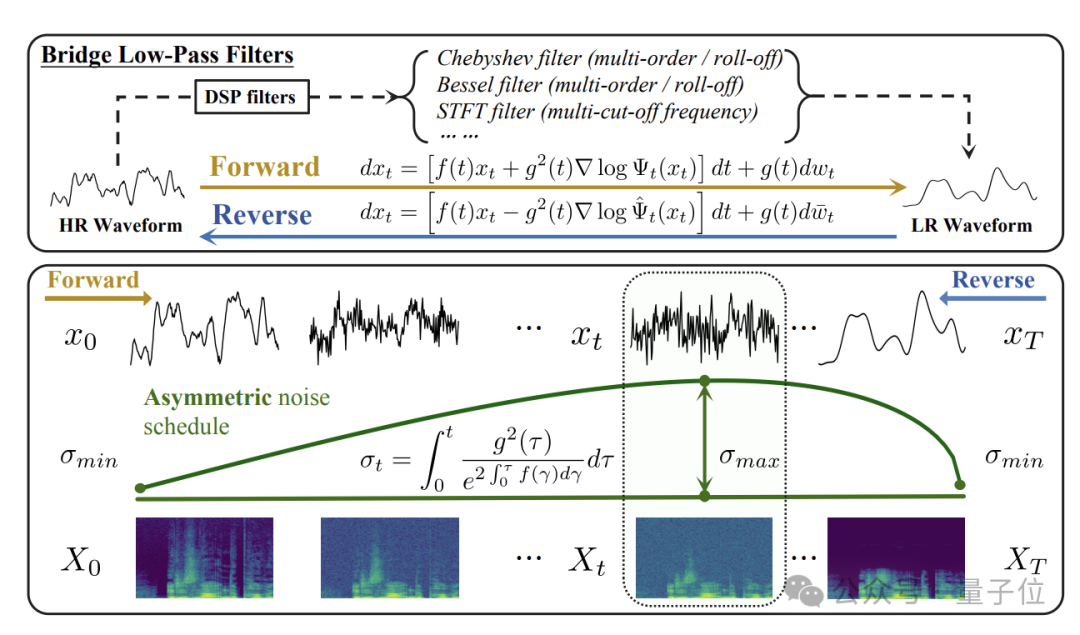
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化
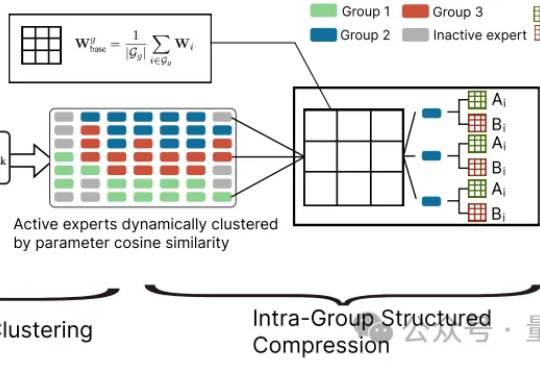
大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境?中科院自动化所新研究给出破局方案——首次让MoE专家告别“静态孤立”,开启动态“组队学习”。
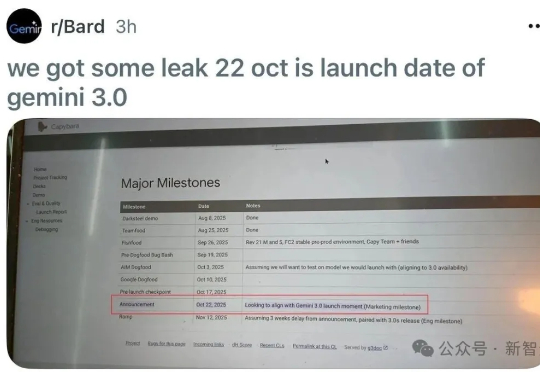
Gemini 3.0更近了!网友爆料称,谷歌下一代旗舰模型将在10月22日发布。一些拿到内测资格的开发者,放出了最全面的demo,Gemini 3.0能做到一次性直出网页、游戏、原创音乐等。前端开发,再也不需要人类。
在量子位智库的观察中,AI知识助手remio正在尝试这一方向。remio主打无感和自动化,致力于变成记忆和用户同频的第二大脑。主打能够在用户无感知的情况下,实时、自动化地采集用户所需管理的信息,为用户创造更加轻松顺畅的使用体验。

国际奥赛又一块金牌,被AI夺下了!在国际天文与天体物理奥赛(IOAA)中,GPT-5和Gemini 2.5 Pro完胜人类选手,在理论和数据分析测试中,拿下了最高分。在理论考试上,Gemini 2.5 Pro总体得分85.6%,GPT-5总体得分84.2%;
这不是科幻,这是 Anything 正在发生的真实故事。这家刚刚完成 1100 万美元融资、估值达到 1 亿美元的创业公司,在上线两周内就实现了 200 万美元的年度经常性收入。更让人震惊的是,他们的用户已经开始用这个平台做出真正赚钱的生意。我深入研究了这家公司后,发现他们不只是又一个 AI 编程工具,而是在彻底改变软件开发的游戏规则。
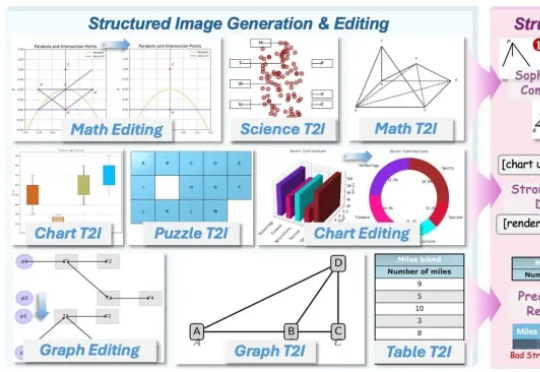
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。

图片来源:David AI Labs David AI Labs 这家初创公司通过出售音频数据集来帮助训练人工智能模型,近期在新一轮融资中从投资者处筹集了 5000 万美元——这表明为 AI 开发提供

如果你觉得离谱,那说明你还没有受骗,但架不住有人已经被骗了。BBC 的一则报道里,就真的有人被骗到:两位游客满心期待地奔赴秘鲁安第斯山中的「圣胡曼塔伊峡谷」,花了 160 美元车费,长途跋涉,来到了偏远山区地带,然后发现——

任少卿的头发很有辨识度,浓密、微卷,刘海盖住额头。走进会议室,第一次见他的人把他当成了实习生,知道身份后调侃说,只有在 AI 创业公司才能看到这么年轻的技术 leader。

本来这个国庆我真的想好好休息一下,但是放假之前写完那篇假期产品推荐之后,微信里就一直有人问我,能不能写一篇豆包的P图玩法教程。。。 一是不知道怎么用,二是不知道怎么写提示词来处理图片。 正好抖音上豆包

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
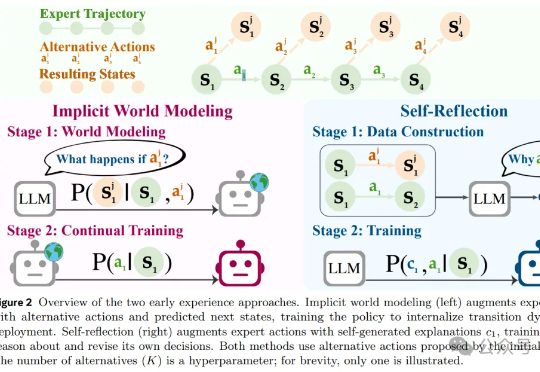
风雨飘摇中的Meta,于昨天发布了一篇重量级论文,提出了一种被称作「早期经验」(Early Experience)的全新范式,让AI智能体「无师自通」,为突破强化学习瓶颈提供了一种新思路。
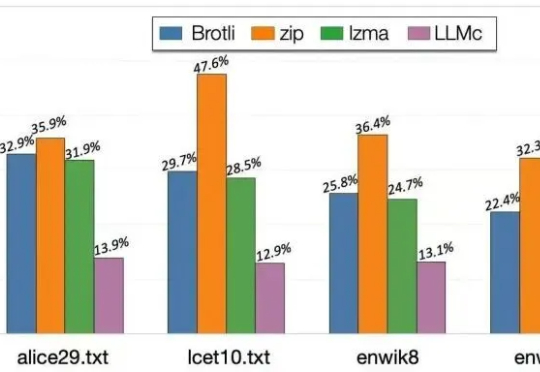
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
那个拒绝了小扎15亿美元薪酬包的机器学习大神,还是加入Meta了。OpenAI前CTO Mira Murati创业公司Thinking Machines Lab证实,联创、首席架构师Andrew Tulloch已经离职去了Meta。
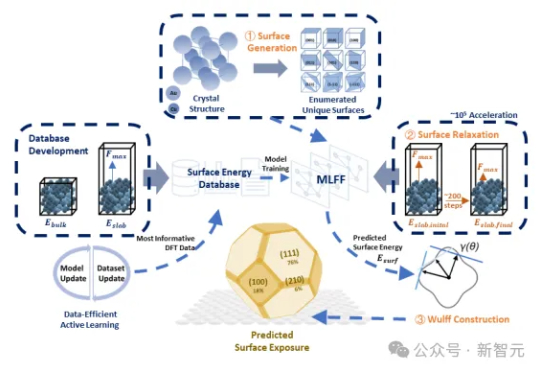
传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。

AI公务员的大脑就是政务大模型。 就在刚刚,中央网信办和国。就在刚刚,中央网信办和国家发展改革委联合印发了重磅文件——《政务领域人工智能大模型部署应用指引》(我们后面就叫它《指引》)。

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。

面壁智能近期已完成新一轮融资。本轮融资由北京市属国有投资平台“京国瑞”(北京京国瑞股权投资基金管理有限公司)及市场化创投基金“米聚和基”等共同参与,数亿元资金将主要用于加大端侧大模型研发力度及推动商业化进程。
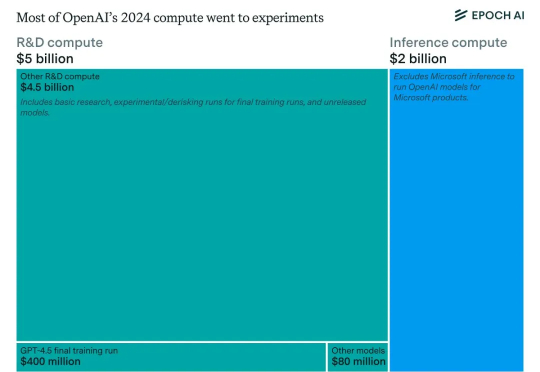
来扒一扒OpenAI算力支出的天价账单——据Epoch AI统计的数据显示,去年OpenAI在计算资源上支出了70亿美元。由于公司当时还没有大量的算力,所以这笔天价账单基本都是以向微软租用云算力的形式支付出去的,并不包括对数据中心的前期投入。
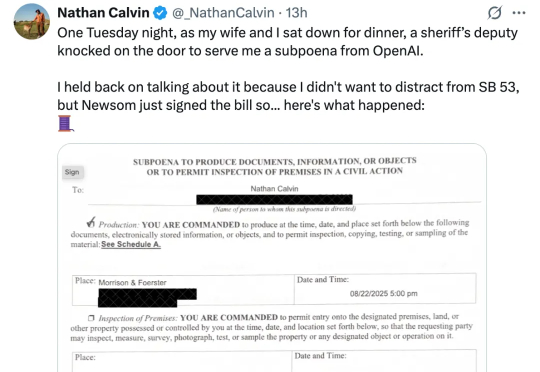
几个小时前,一位名为 Nathan Calvin 的 X 网友发推文称,「一个周二晚上,我和妻子正准备吃晚饭,一位副警长敲门,递给了我一张 OpenAI 的传票」。该传票不仅涉及他所在的 Encode 组织,还要求 Calvin 提供与加州立法者、大学生和前 OpenAI 员工的私人信息。而这一切都与一项近期通过的名为 SB 53 的法案有关。
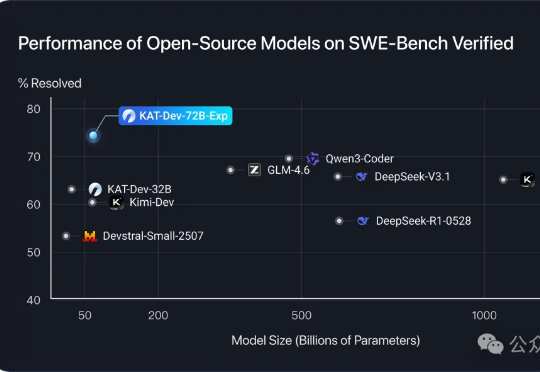
开源编程模型王座,再度易主!来自快手的KAT-Dev-72B-Exp,在SWE-Bench认证榜单以74.6%的成绩夺得开源模型第一。KAT-Dev-72B-Exp是KAT-Coder模型的实验性强化学习版本。

昨天,State of AI Report 2025 正式发布了。背后主笔是硅谷投资人 Nathan Benaich 和他创办的 Air Street Capital,从 2018 年开始,这份报告就被称为“AI 行业的年度百科”。
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
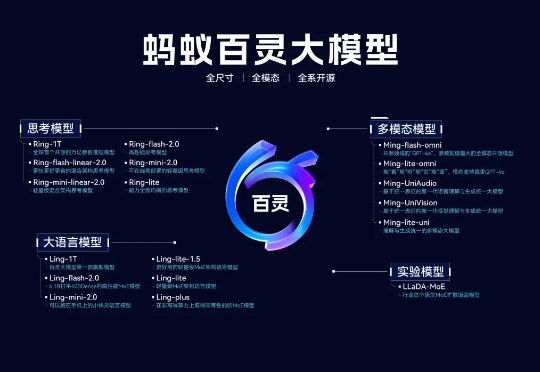
10 月 9 日凌晨,蚂蚁百灵大模型团队奇袭般官宣了一款自家最新语言大模型 Ling-1T,参数量达到 1000B(即 1万亿参数)。然而,就在十天前,百灵团队才将自研 Ring-1T-preview 大模型开源。

「AI教父」Hinton毕生致力于让机器像大脑般学习,如今却恐惧其后果:AI不朽的身体、超凡的说服力,可能让它假装愚笨以求生存。人类对「心智」的自大误解,预示着即将到来的智能革命。

