


硅谷AI研发精英,每周需工作100小时
硅谷AI研发精英,每周需工作100小时在硅谷AI竞赛的风暴眼中,研究员与高管以「战时」强度奔跑:从Anthropic的深夜Slack,到DeepMind的「0-0-2」作息与难享之财;微软以AI自救仍难减负;OpenAI为遏止倦怠与Meta挖角被迫「停摆一周」。这是一场以天才、时间与心力为燃料的冲刺,推动突破,也将人推向临界点:灯火通明,平衡仍无解。
来自主题:
AI资讯
7505 点击 2025-10-27 11:38
 搜索
搜索
在硅谷AI竞赛的风暴眼中,研究员与高管以「战时」强度奔跑:从Anthropic的深夜Slack,到DeepMind的「0-0-2」作息与难享之财;微软以AI自救仍难减负;OpenAI为遏止倦怠与Meta挖角被迫「停摆一周」。这是一场以天才、时间与心力为燃料的冲刺,推动突破,也将人推向临界点:灯火通明,平衡仍无解。

在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。

2025 年 10 月 22 日,AI 基础设施公司 Fal.ai宣布完成新一轮 2.5 亿美元融资。据悉,凯鹏华盈与红杉资本领投此轮,公司估值超40亿美元。
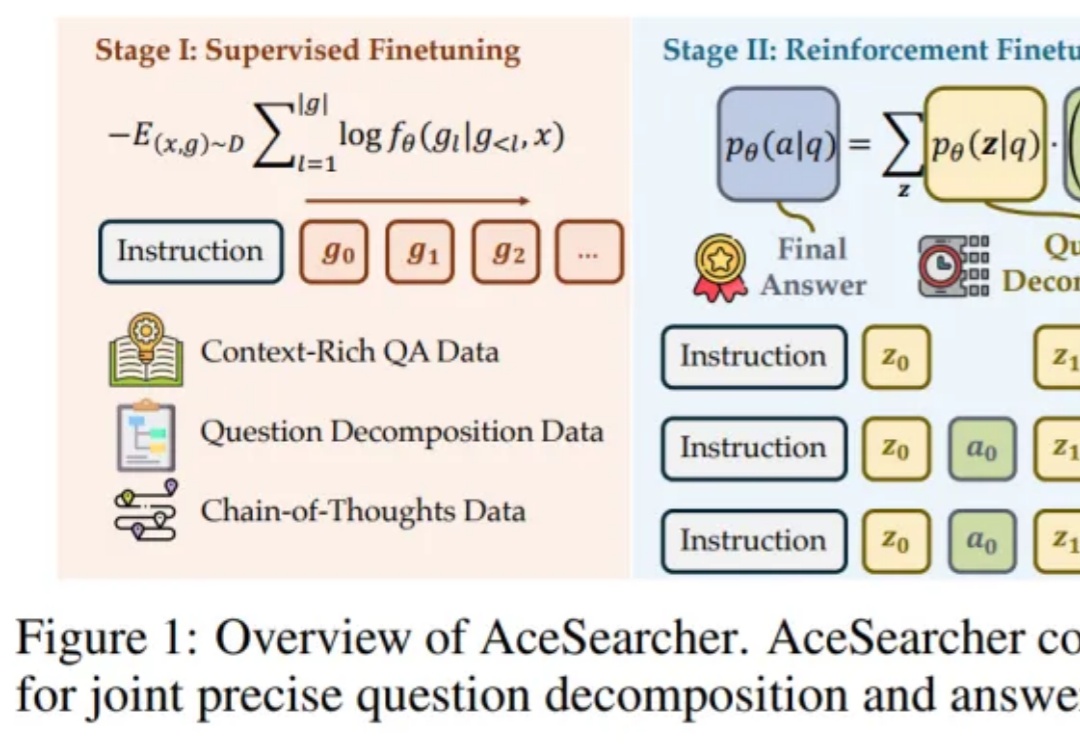
如何让一个并不巨大的开源大模型,在面对需要多步检索与复杂逻辑整合的问题时,依然像 “冷静的研究员” 那样先拆解、再查证、后归纳,最后给出可核实的结论?
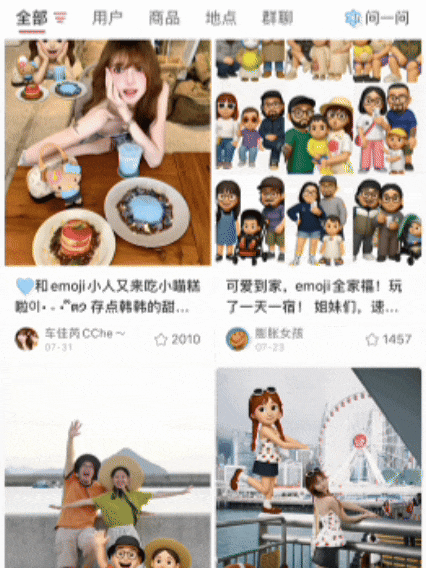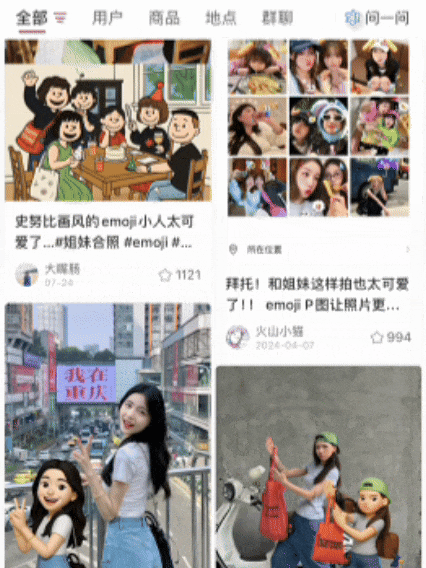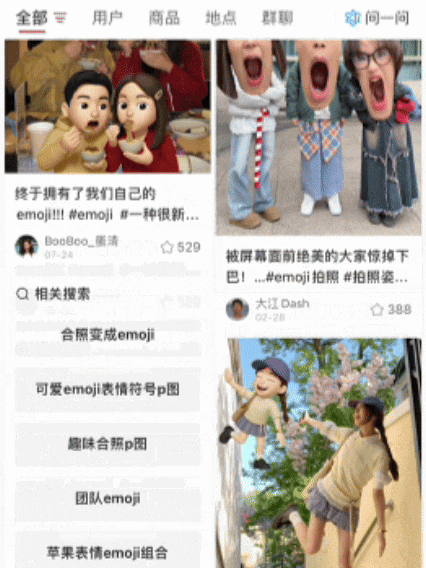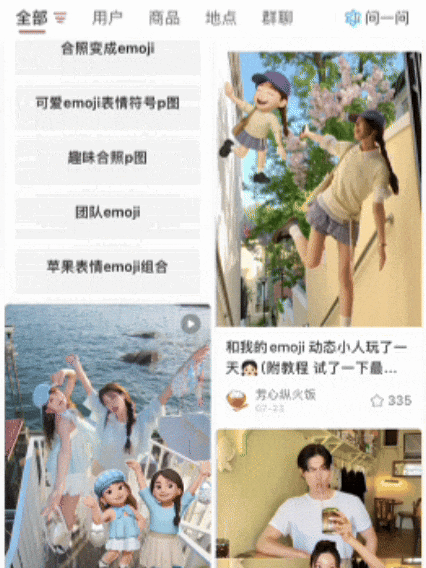
这些刷屏的AI图片,你刷到了没?就是那种——和自己专属emoji合影的黏土风照片,画风长这样:本来以为是NanoBanana整的新玩法,结果点开评论区一看:嗐,原来是美图自家的AI Agent——叫RoboNeo~
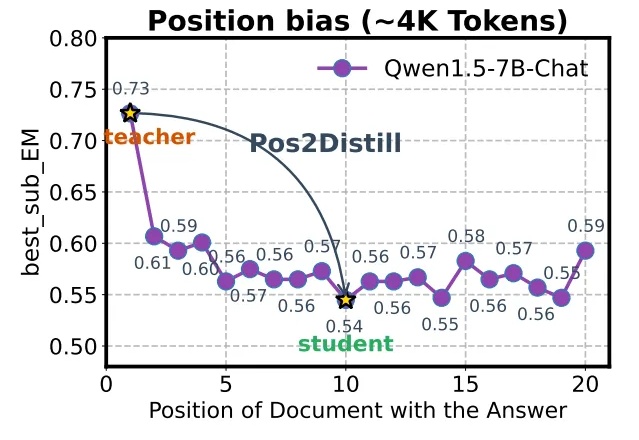
语言模型遭遇严重的位置偏见,即模型对不同上下⽂位置的敏感度不⼀致。模型倾向于过度关注输⼊序列中的特定位置,严重制约了它们在复杂推理、⻓⽂本理解以及模型评估等关键任务上的表现。

聚焦大型语言模型(LLMs)的安全漏洞,研究人员提出了全新的越狱攻击范式与防御策略,深入剖析了模型在生成过程中的注意力变化规律,为LLMs安全研究提供了重要参考。论文已被EMNLP2025接收

最近的 Meta 可谓大动作不断,一边疯狂裁人,一边又高强度产出论文。

你永远无法精确描述出梵高的笔触或王家卫的光影。AI创作的未来,是让AI直接「看懂」你的灵感,而不是去揣摩你的指令。
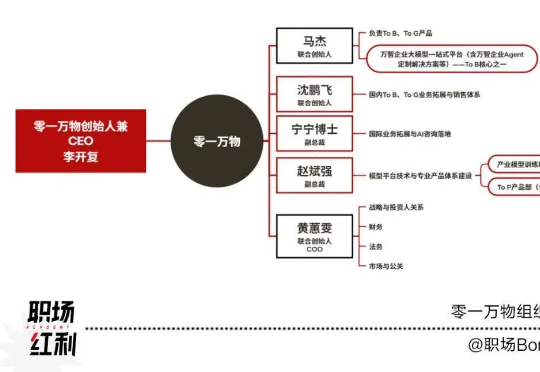
《职场Bonus》独家获悉,“AI六小龙”零一万物迎来一轮密集的高管变动:前百度智能云中国区副总经理沈鹏飞已于今年零一万物转型后以联合创始人身份加入公司,负责零一万物 ToB、ToG 业务拓展与销售体系。
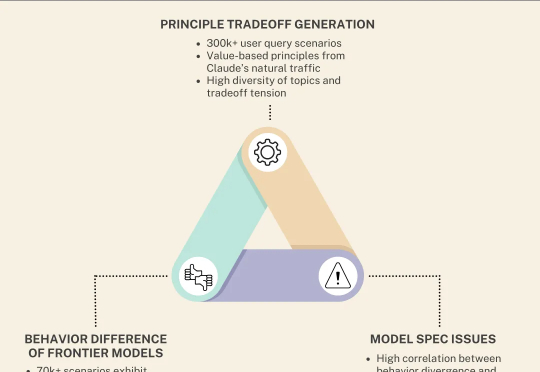
如何科学地给大模型「找茬」?Anthropic联合Thinking Machines发布新研究,通过30万个场景设计和极限压力测试,扒了扒OpenAI、谷歌、马斯克家AI的「人设」。那谁是老好人?谁是效率狂魔?

周末看到了宝玉老师的一个帖子,我自己其实有非常强烈的共鸣。 宝玉老师说的是编程,而我在创作这块,其实一直都有相同的观点: 如果你是一个想在某个领域,真正深耕下去,想成为这个领域的专家,那么,在你独立、手动、不借助(或极少借助)AI,完成1000个小时的刻意练习之前,离AI远一点。
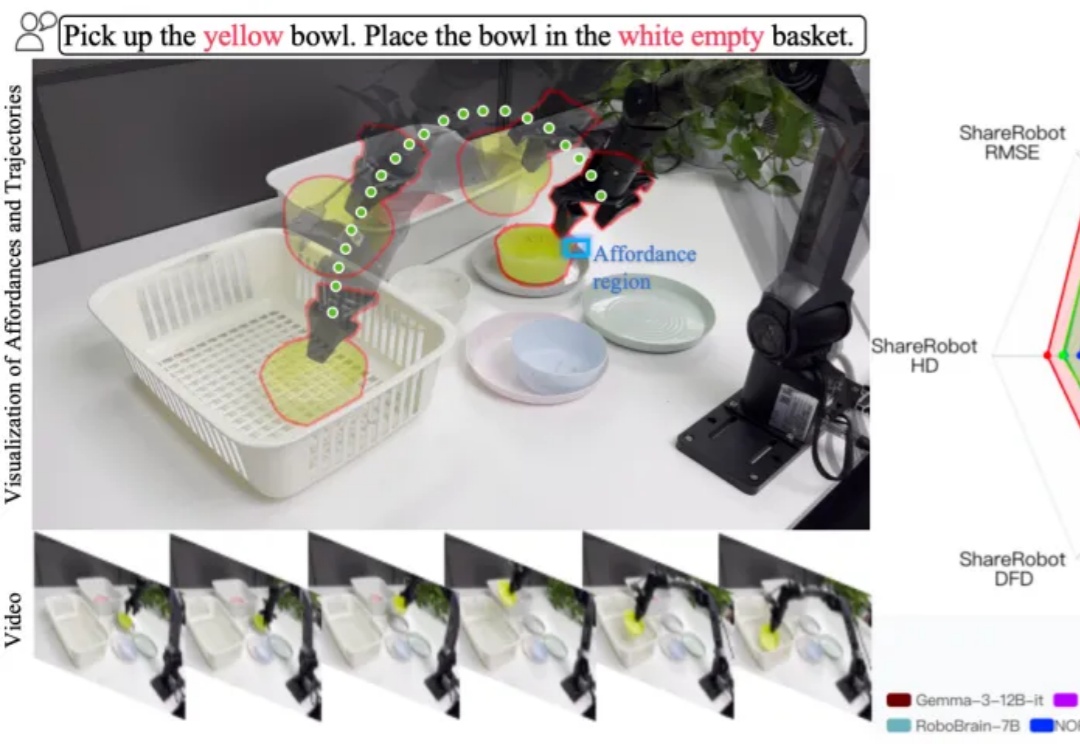
在机器人与智能体领域,一个老大难问题是:当你让机器人 “把黄碗放进白色空篮子” 或 “从微波炉里把牛奶取出来放到餐桌上” 时,它不仅要看懂环境,更要解释指令、规划路径 / 可操作区域,并把这些推理落实为准确的动作。

看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。

OpenAI近日接连发布《日本经济蓝图》和《韩国经济蓝图》,标志其亚太战略从「产品输出」升级为「国家级合作」。在韩国,OpenAI提出「双轨战略」,推动韩国跻身全球AI前三强;在日本,则以「三支柱」计划为核心,助力日本借由AI重塑全球技术引领地位。

在 AI 时代,开发的边界正被重新划定。 我们能够观察到,越来越多的产品经理、数据分析师、设计师,甚至内容创作者,正在熟练地使用 Cursor、ChatGPT、DeepSeek 等 AI 工具,解决真
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。
一场公开演讲,LeCun毫不留情揭穿真相:所谓的机器人行业,离真正的智能还远着呢!这番话像一枚深水炸弹,瞬间引爆了战火,特斯拉、Figure高管纷纷在线回怼。
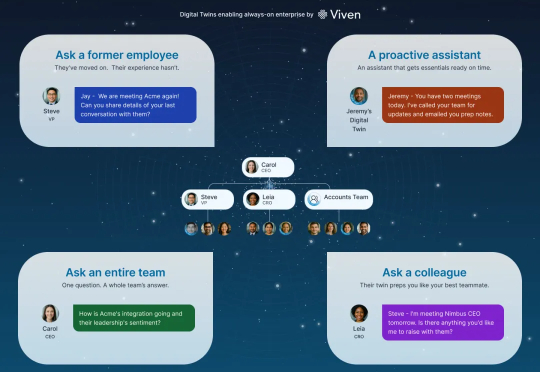
Viven 的核心创新在于,它为每个员工创建了一个个性化的大语言模型,实质上就是一个数字分身。这个分身通过访问员工的内部电子文档,包括邮件、Slack 消息、Google Docs、会议记录等,学习这个人如何思考、如何沟通、拥有什么知识。关键是,这个学习过程是自动进行的,不需要员工做任何额外工作。你只需正常工作,你的数字分身就会不断更新和进化。
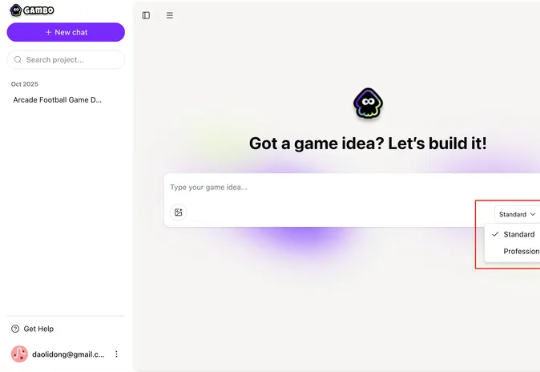
Gambo 称自己为 “世界上第一个 Game Vibe Coding Agent”。用户只需描述游戏类型、主题或风格,AI 就会自动生成场景、角色、交互与音效,并把这些内容编织成一个可玩的世界。

Stephan罹患癌症之后,妻子Katrine不愿让死亡隔断自己与丈夫的联系,于是她和丈夫一起投入了一个疯狂的项目——为Stephan打造数字分身。在AI专家的帮助下,一个融合了Stephan记忆、声音、个性的全新「AI-Stephan」诞生了。

近两年,AI笔记成为AI应用落地的重点方向之一。随着大模型能力不断升级,AI笔记不再只是帮用户“写下东西”,而是试图理解、整理、提炼、甚至帮用户“思考”所记录下的内容。市场上AI笔记产品繁多,既有印象笔记、Notion AI这样加入AI能力的传统笔记产品,也有闪念贝壳、喵记多这样的AI原生笔记产品,甚至还有飞书文档这样将AI笔记功能嵌入办公套件的综合性产品。

知识图谱推理是人工智能的关键技术,在多领域有广泛应用,但现有方法存在推理效率低、表达能力不足、过平滑问题等挑战。中科大研究团队提出DuetGraph,采用双阶段粗到细推理框架与双通路全局 - 局部特征融合模型,实现推理精度与效率的平衡,为大规模知识推理提供解决方案。
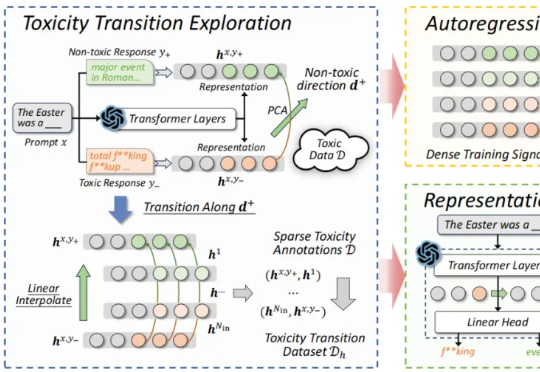
近期,来自北航等机构的研究提出了一种新的解决思路:自回归奖励引导表征编辑(ARGRE)框架。该方法首次在 LLM 的潜在表征空间中可视化了毒性从高到低的连续变化路径,实现了在测试阶段进行高效「解毒」。

500 万用户、八位数年经常性收入、日均新增 2 万用户——对于 2024 年初由两名 20 岁大学生 Rudy Arora 与 Sarthak Dhawan 创办的初创公司 Turbo AI 而言,这些数据堪称亮眼。对于刚达到法定饮酒年龄(美国为 21 岁)的年轻人来说,这样的成绩更显不可思议。

在刚刚结束的AI终端生态大会上,荣耀携手生态合作者一起,展示了AI在家庭、出行、教育、陪伴等场景中的新用法,把自进化的AI真正带进了生活的每个角落。以手机为中心,一张“全生态”的大网在打破设备边界,更是在构建一个“人、设备、场景 、伙伴”的协同网络。

刚面世时的 Sora 有多红火,现在就有多麻烦。这个月,日本政府正式呼吁 OpenAI 在推出 Sora 2 的过程中「应避免侵犯版权」,并强调「漫画与动画角色是日本引以为傲、不可替代的文化瑰宝」。

几个月前,和 OpenAI“星际之门”(Stargate)项目的合作,让 Crusoe 这家公司一夜成名。据创始人介绍,公司的名字灵感来源于小说《鲁滨逊漂流记》(Robinson Crusoe),正像鲁滨逊在荒岛上竭力利用全部资源来生存一样,这家公司也试图最大化利用废弃或闲置能源,并通过算力来释放其价值。
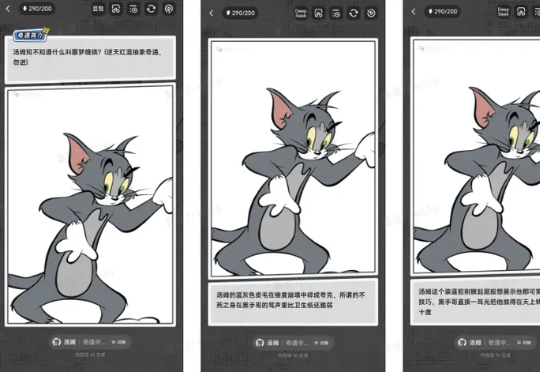
自 2023 年起,AIGC 平台迅速演进,用户从生成一张图走向创造一个“人”。捏Ta 2.0就想成为让这个拐点发生的那款产品。这次升级的意义不在更快的渲染或更新的 UI,而在于正面回答了那个关键问题:AI 的幻想世界,如何真正“长出生命力”。
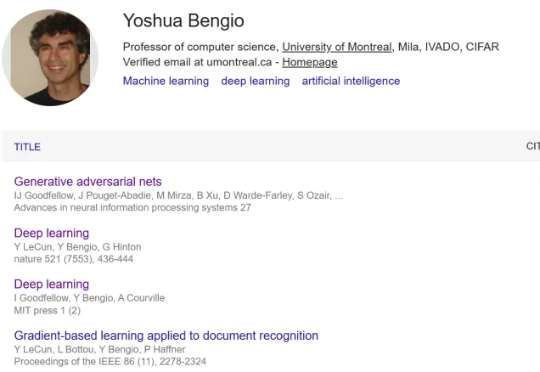
刚刚,计算机科学家 Yoshua Bengio 创造了新的历史,成为 Google Scholar 上首个引用量超过 100 万的人!打个直观的比方,如果我们将每一篇引用论文打印成册(假设平均厚度为 1 毫米),然后将它们垂直堆叠起来,这座由知识构成的纸塔将高达 1000 米。这是什么概念?它将轻松超越目前的世界最高建筑,即 828 米的迪拜哈利法塔。

