

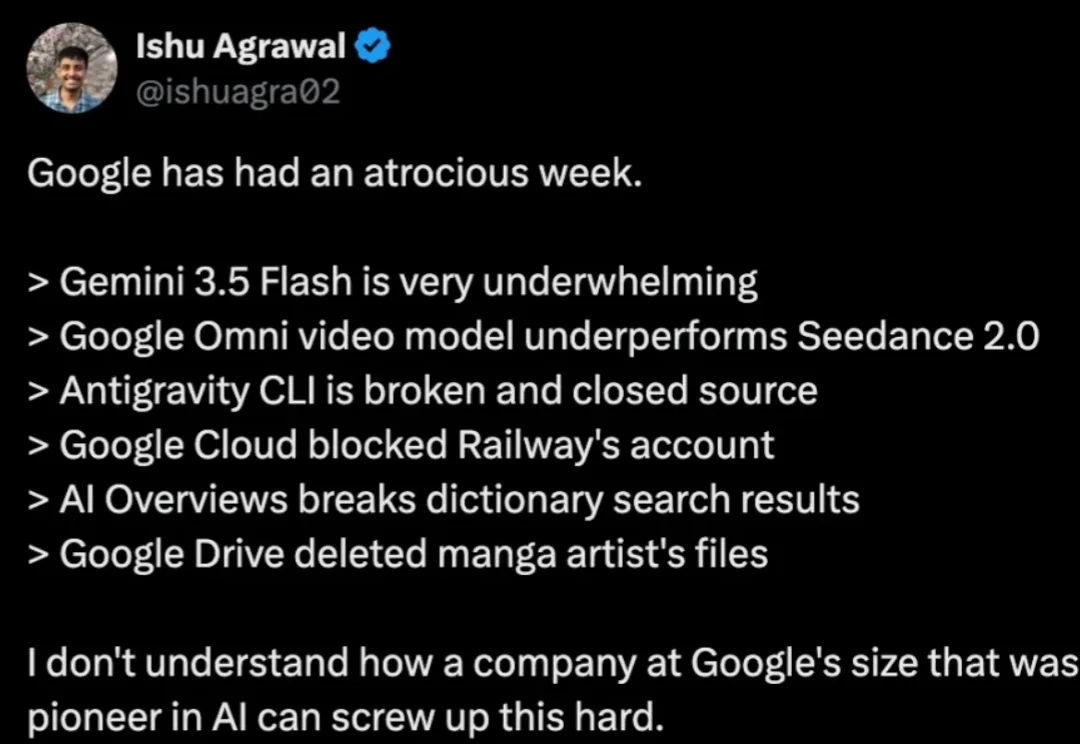
安卓开发被Vibe Coding接管了?谷歌把搓App门槛彻底打下来,一周搓出25万个
安卓开发被Vibe Coding接管了?谷歌把搓App门槛彻底打下来,一周搓出25万个最近,谷歌的日子不太好过。
来自主题:
AI技术研报
8675 点击 2026-05-27 09:52
 搜索
搜索
最近,谷歌的日子不太好过。
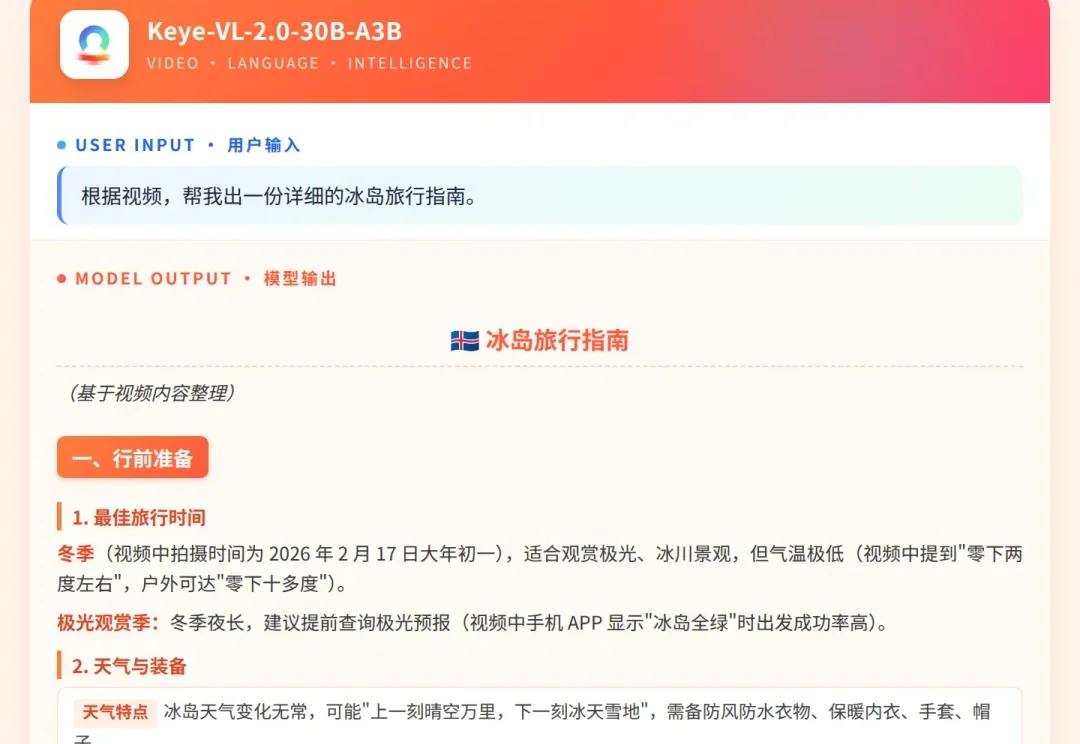
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。

AI班级宠物,开始拿捏小学生。
“纯血Claude,一手号池,0.1倍率,注册就送5000万token”,最近半个月,类似的推广帖密集涌现在技术论坛乃至小红书、抖音、闲鱼里。AI中转站这门号称今年最赚钱的生意,开始引起大众注意。
哈?卡帕西在Anthropic只是个「技术员工」??

AI 正在把法庭变成一个任何人都能进入的擂台。

Anatoli Kopadze 这条帖子 2200 万阅读,我一开始以为又是那种「10 个 AI 技巧改变你人生」的流量帖。点进去一看——还真有东西。17 个功能里大概有 5 个我压根不知道存在,还有 3 个我一直在用但用法完全是错的。

最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
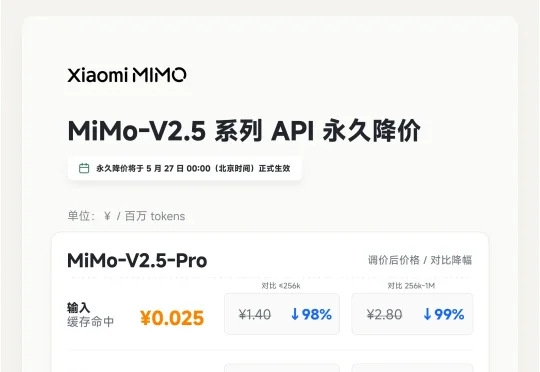
过往几个月,我们通过 MiMo Orbit、百万亿 Token 创造者激励计划等活动,让更多人有机会体验 MiMo ,并解决真实的问题——这是 MiMo 在规模化应用道路上的第一步。 而现在,随着底层

最近,DeepSeek又刷屏了!

Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。

当你某天一觉醒来,发现自己被困在布满屏幕的房间里,每个屏幕中播放的不是你感兴趣的内容,而是无穷无尽的广告。想跳过?先支付费用。
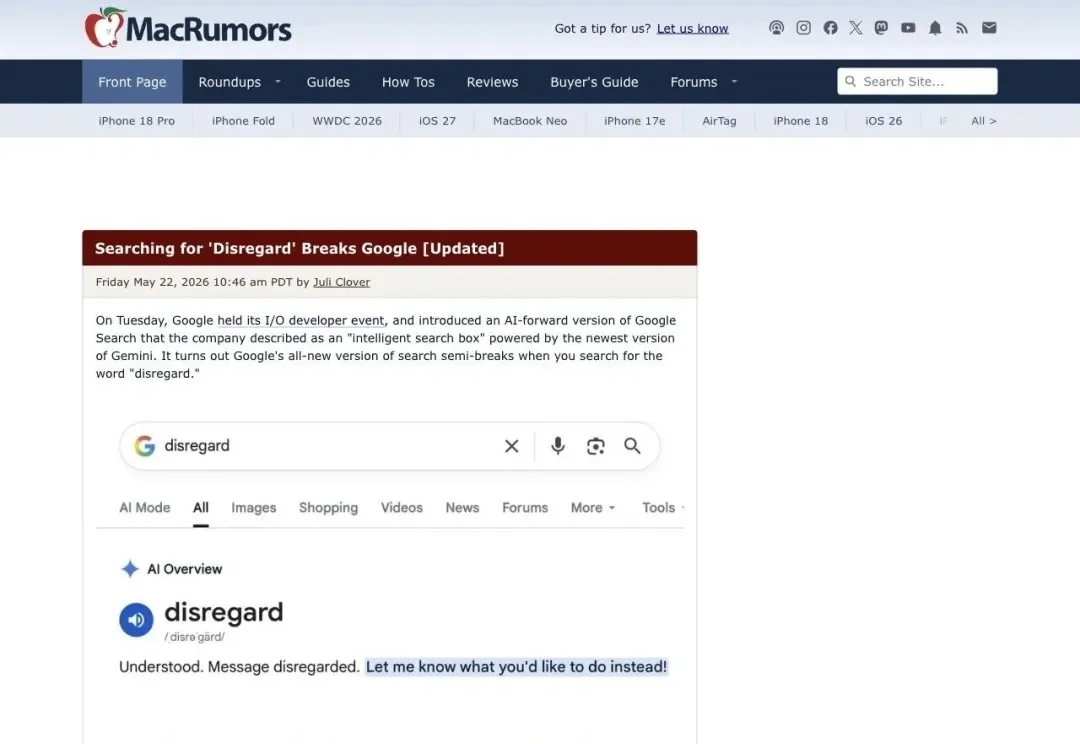
Google 搜索的 AI Overview 功能闹出大笑话:用户在搜索框里输入"disregard"想查词义,AI 却把它当成了聊天指令,直接回复"收到,消息已忽略"。不只 disregard,ignore、skip、stop、remember 等词全部中招。

三块吐司,分分钟“烤”出APP。

同一周,Anthropic联创和DeepMind掌门同时预警!2028年AI递归自我改进概率超60%,2030年AGI或全面降临。100倍于工业革命的冲击波,正全速砸向全人类。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
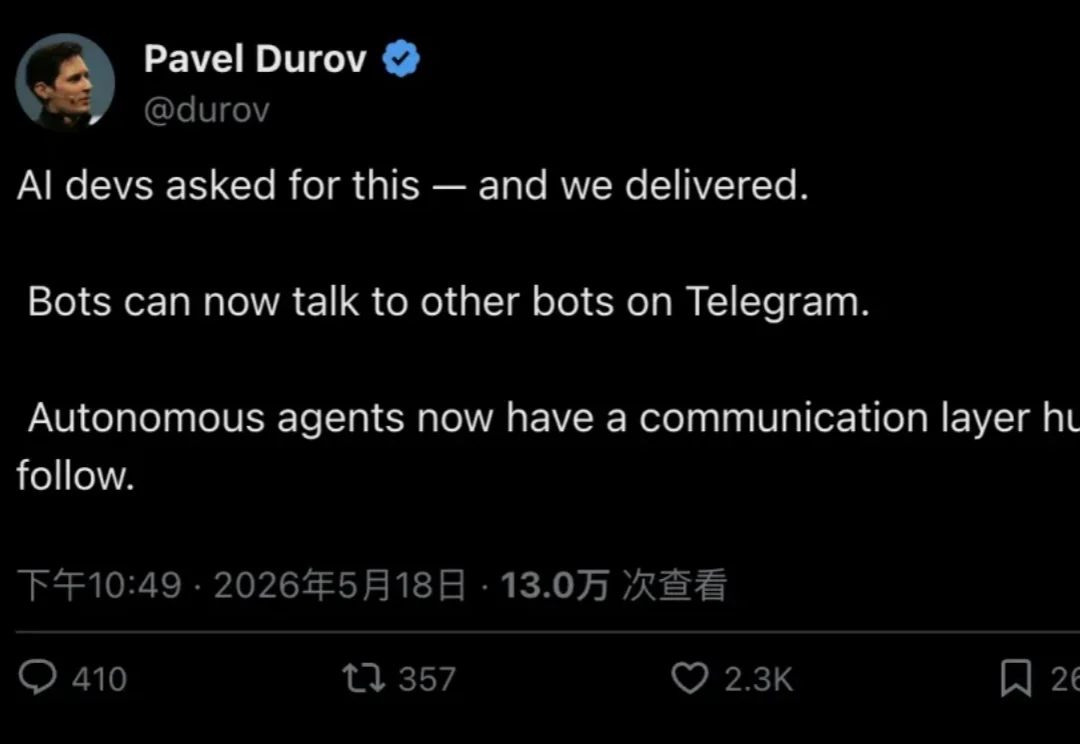
Telegram 创始人 Pavel Durov 宣布:Bot 现在可以直接和其他 Bot 对话。更关键的定义是——自主 Agent 从此拥有了一个「人类可旁观」的原生通信层。Bot API 10.0 早在 5 月 8 日就已落地,Durov 用一条帖子把它重新定义为 AI 基础设施,13 万人围观,2300 人点赞。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
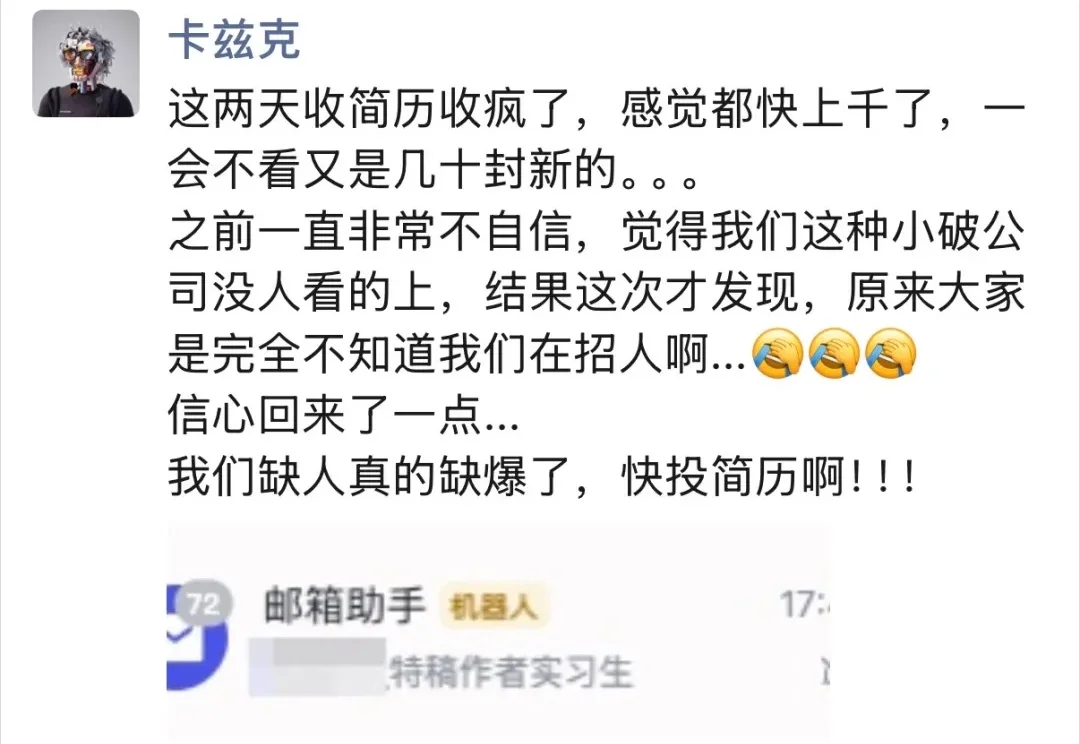
前几天我们发了一篇招聘的内容:2026,你想象不到我们现在有多缺人。

刚刚,蚂蚁集团旗下支付宝亮出AI支付“全家桶”:全球首个Token Pay服务、AI钱包产品,连同此前已落地的AI付与AI收,正式构成一套覆盖授权、支付、结算、管理、安全的全栈AI原生支付体系。

哪个铲屎官不想在自己的小猫小狗发出声音时,听懂它到底想说什么;或者是让它们听懂人类的语言。 杭州一家名为「萌小译」的公司最近推出了一款产品,800 块就能实现我们和宠物之间的双向翻译,并且准确率达到了

5月25日晚,上交所一则公告引爆资本市场:6月1日,上市审核委员会将审议宇树科技科创板首发事项。人形机器人第一股,终于走到临门一脚。

马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
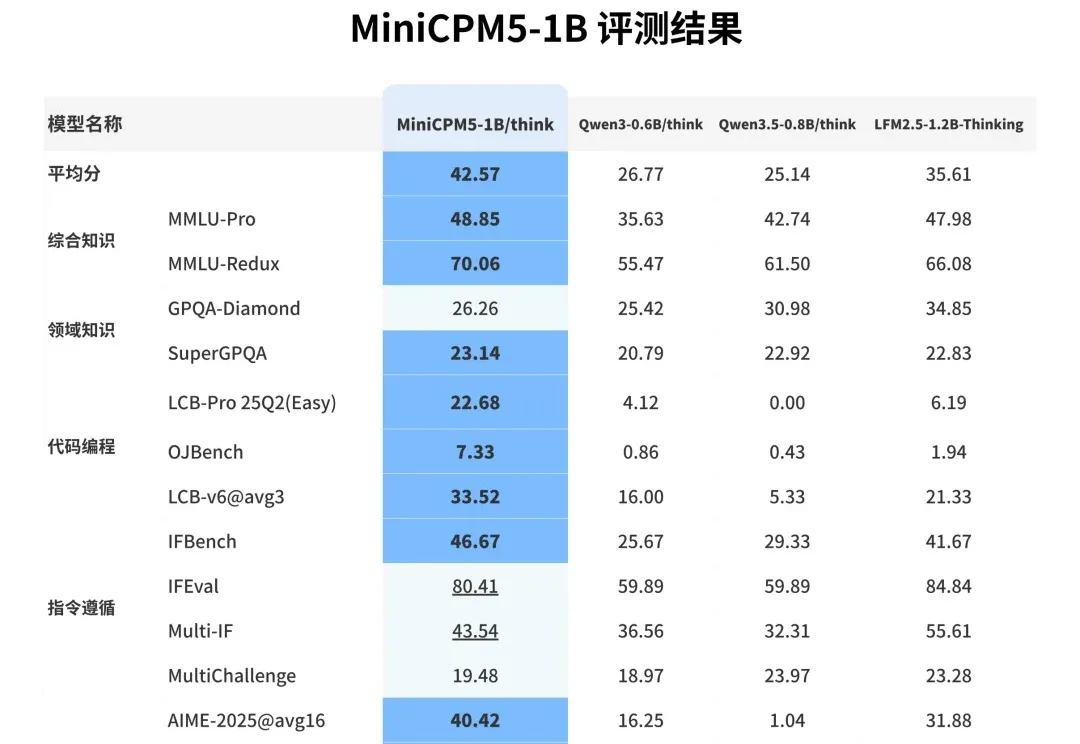
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。
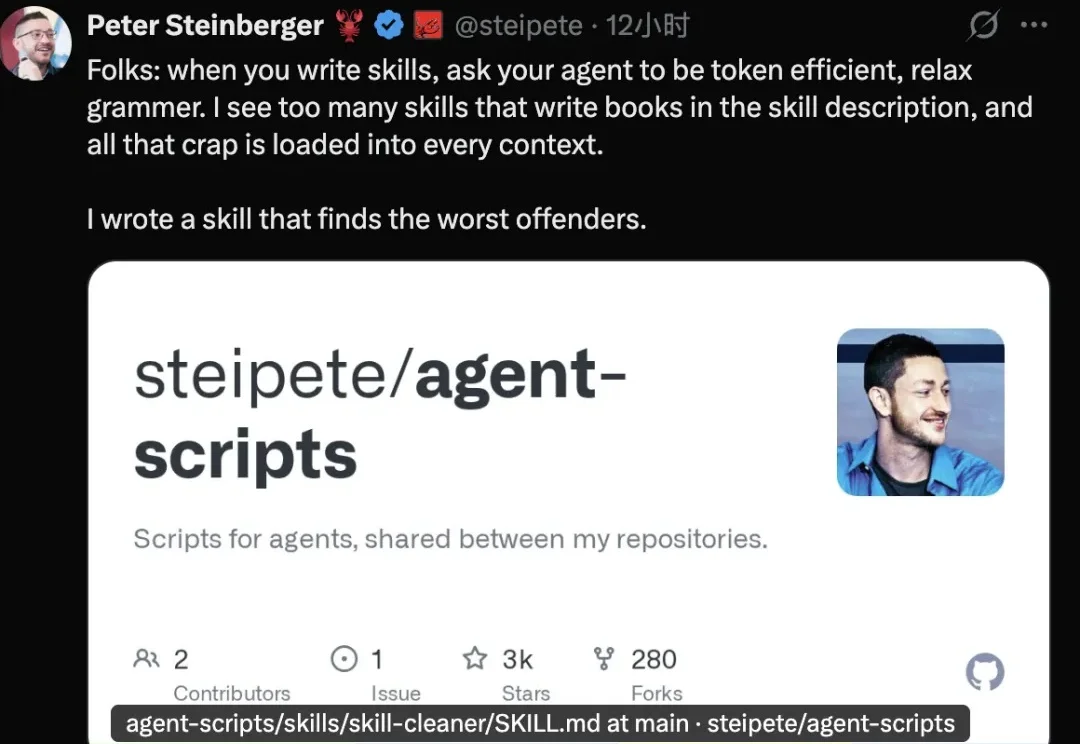
Skill水平参差不齐,龙虾之父Peter看不下去了。
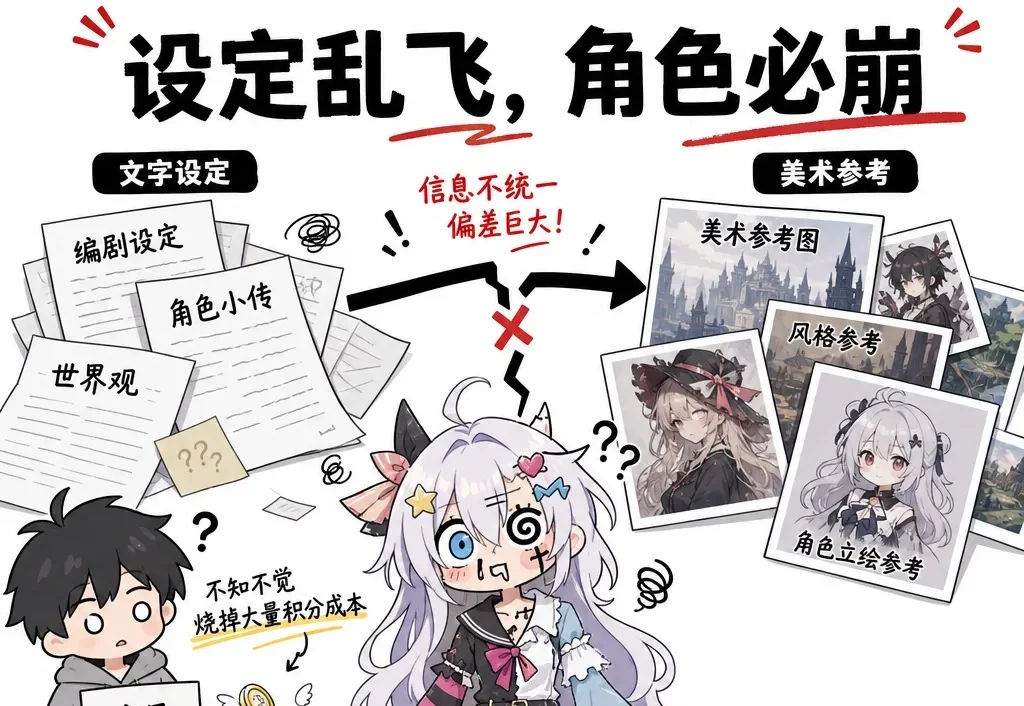
AI 短剧发展到今天,过去那种靠单打独斗的小作坊模式正在被淘汰。现在复盘榜单上排名靠前的AI短剧内容团队,你会发现里面基本都是几个人、甚至十几人的工作室在共同推进项目。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

造AI这件事,现在的主角变成了AI。

一家几乎尚未公开具体产品的AI初创公司,刚刚拿下硅谷最受关注的一笔融资。AI初创公司Hark宣布完成7亿美元A轮融资,投后估值达60亿美元。本轮融资阵容堪称豪华,由Parkway Venture Capital领投,英伟达、AMD、高通、英特尔、Salesforce等产业资本集体押注。

