


GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
来自主题:
AI资讯
9117 点击 2026-05-29 10:11
 搜索
搜索
GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。

ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
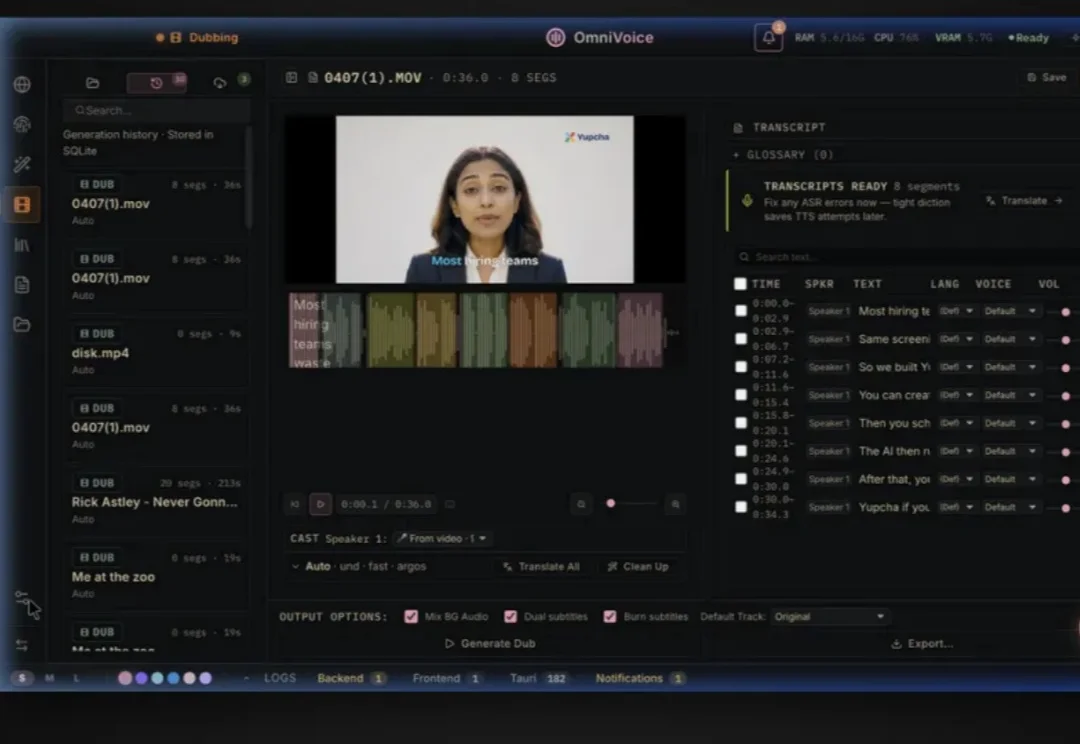
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。

光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
OpenAI 公开介绍 Computer-Using Agent 时,讲的也是这个方向:模型针对图形界面交互做过训练,能把屏幕理解、任务目标和鼠标键盘动作接起来。鼠标会动只是表面。遇到按钮位置变化、弹窗多一层、页面慢一点时,它还能重新看屏幕,继续判断下一步。
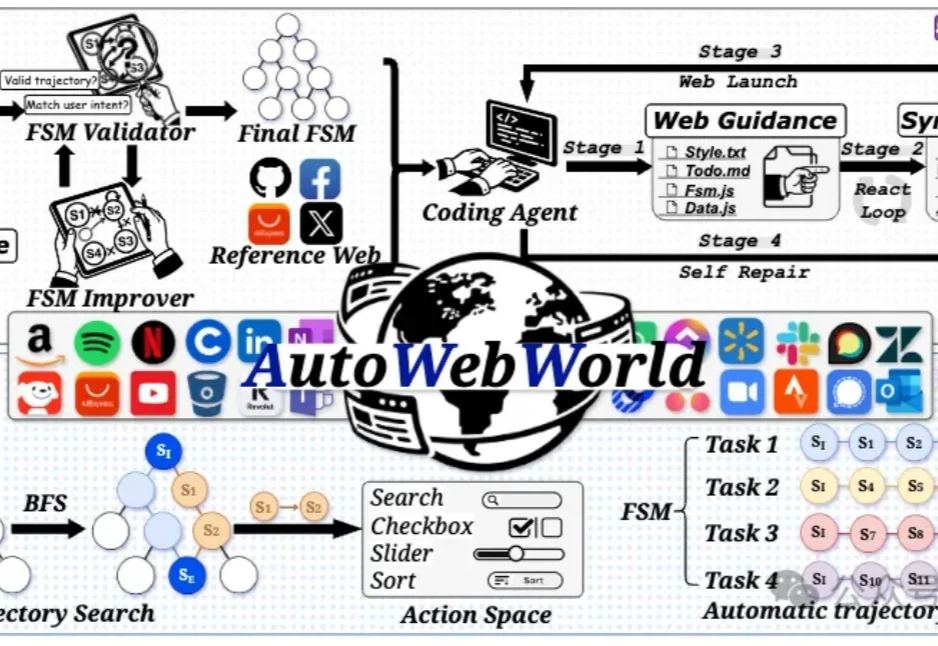
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。

后空翻、跑酷、单手抓举几十公斤……
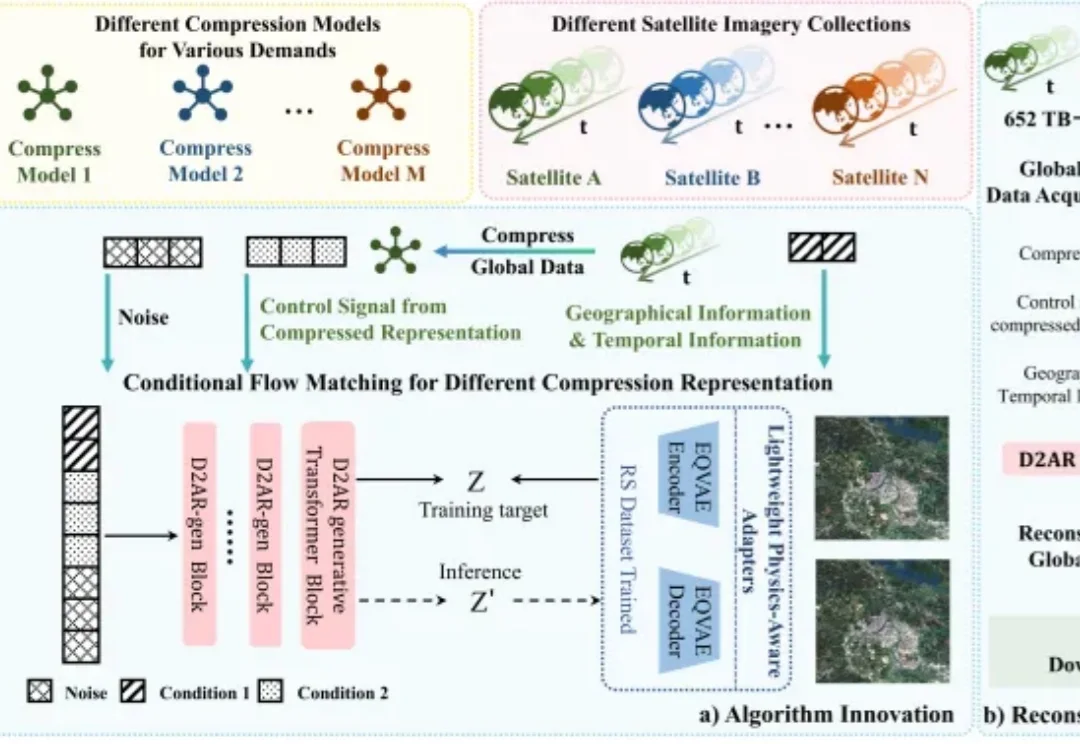
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

最近Codex的热度,真的感觉直线飙升。
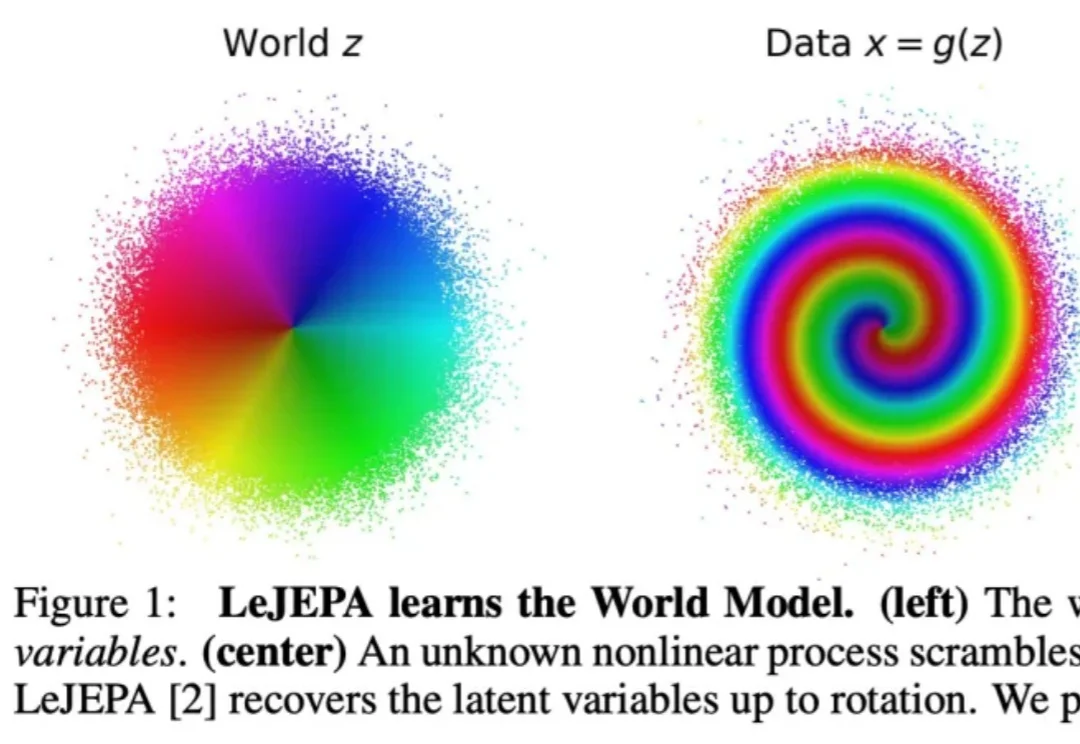
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

同一个市场,同一个月成立的公司。

国内唯一基于 MRAM(磁性随机存储器)构建存内概率计算平台的技术团队。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。
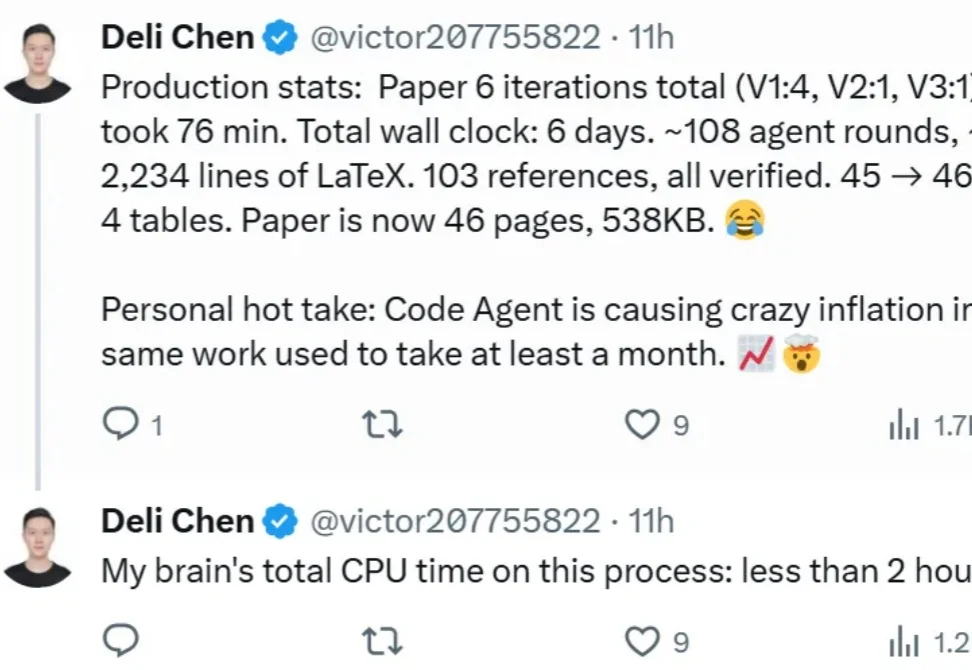
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。

有一个我们很少说出口的预设:AI 带来的恐慌是从下往上递减的。越底层越慌,越顶层越从容。应届生最危险,大厂高管有把握,基础模型公司的人?他们是在写未来,不是在应对它。
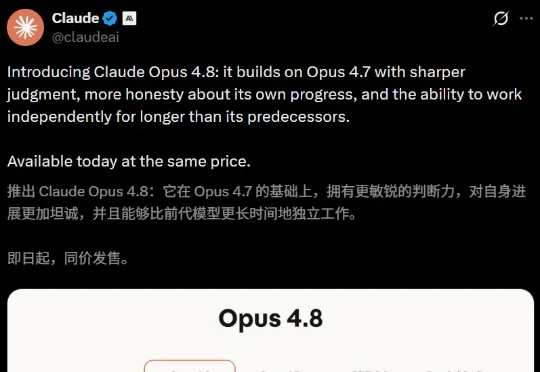
Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。

刚刚,Claude Code迎来史上最大规模底层升级!Anthropic直击开发者最痛的6大顽疾:终端闪烁、思考假死、玄学报错、上下文死锁、连接不稳、会话崩溃。一夜之间,AI编程工具从「聪明外挂」进化为「可靠伙伴」。
初创公司Axiom Math宣布,他们从2026年2月开始提交的8篇论文,到5月28日有5篇已经通过同行评审,登上学术期刊。创始人洪乐潼,2001年出生于广州,本科MIT三年拿下数学与物理双学位,还拿过北美数学本科生的最高荣誉罗德奖学金和摩根奖。
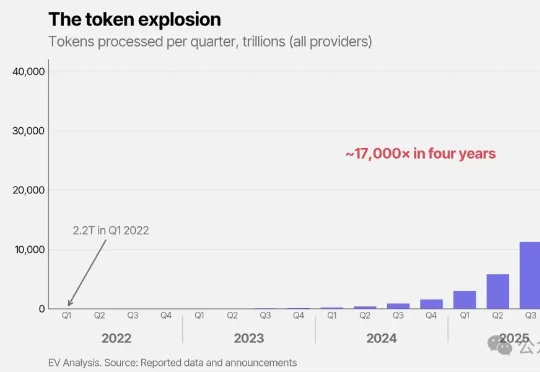
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
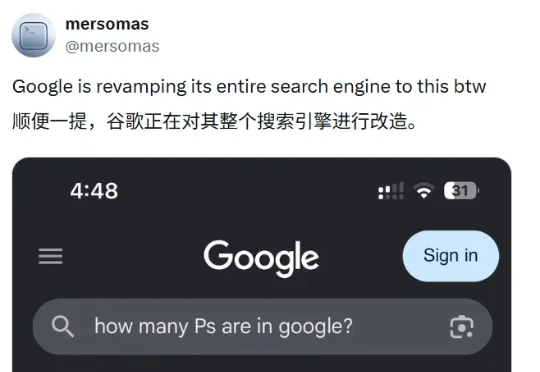
今天,又有新的问题出现了,这一次是谷歌搜索。有用户发现,近日升级了 AI 能力的谷歌搜索在面对「google 里面有几个 P」这样的简单问题时竟然失败了!这件事引发广泛关注和测试热潮。我们也简单试了下,就算用汉语提问,谷歌搜索同样错误,而且还自行加戏,导致错上加错 —— 说 Pixel 里面有两个 P
收到面壁智能的内测邀请,我翻了翻产品逻辑,发现它想解决的问题和我当时的处境一模一样。AI 能不能不只是回消息,而是做项目。AI 能不能记住规则,能在你睡觉的时候继续干活,能自己发现你漏了什么。
有一套配置能让Claude自动发现错误、自动修复、并且记住不再犯同样的错,Boris Cherny详细解释了这套配置。Boris Cherny(Claude code创始人)最新采访爆料cc团队内部已经停止人为修复 Claude 的错误,他们现在让 Claude 自己修复它们

就在今天,科大讯飞在澳门发布了旗下首款 AI 眼镜。这副 40 克的眼镜没有卷像素、卷全彩大屏、卷时尚联名,把核心能力押注在一个看起来十分常见的能力上——翻译。

Devin 证明,独立 Vibe Coding 平台依然有机会。

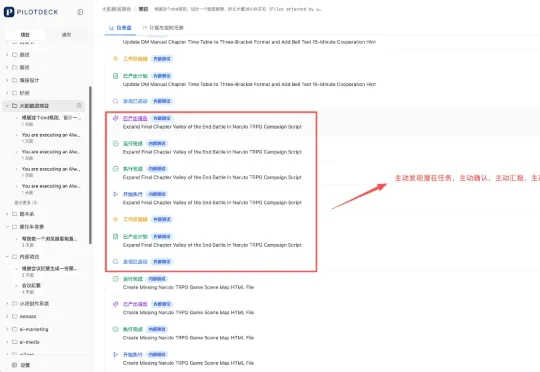
刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!

