

清华&通院推出"绝对零"训练法,零外部数据大模型自我博弈解锁推理能力
清华&通院推出"绝对零"训练法,零外部数据大模型自我博弈解锁推理能力不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
来自主题: AI技术研报
7532 点击 2025-05-12 15:18
不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。
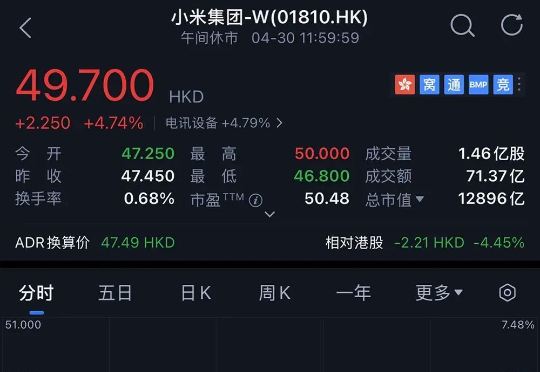
今天上午,小米发布了其首个开源推理大模型-Xiaomi MiMo。通过 25 T 预训练 + MTP 加速 + 规则化 RL + Seamless Rollout,让 7 B 参数的 MiMo-7B 在数理推理和代码生成上赶超 30 B-32 B 大模型,并完整 MIT 开源全系列与工程链,给端-云一体 AI 落地提供了“以小博大”的新范例。

大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。
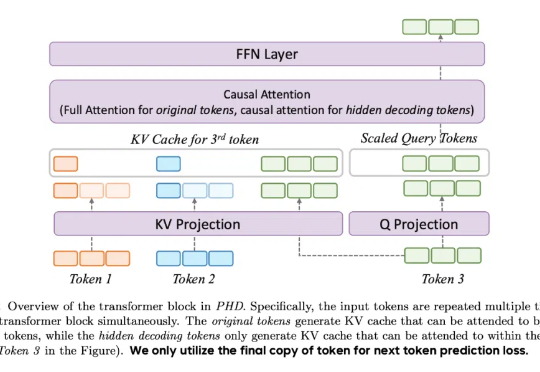
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
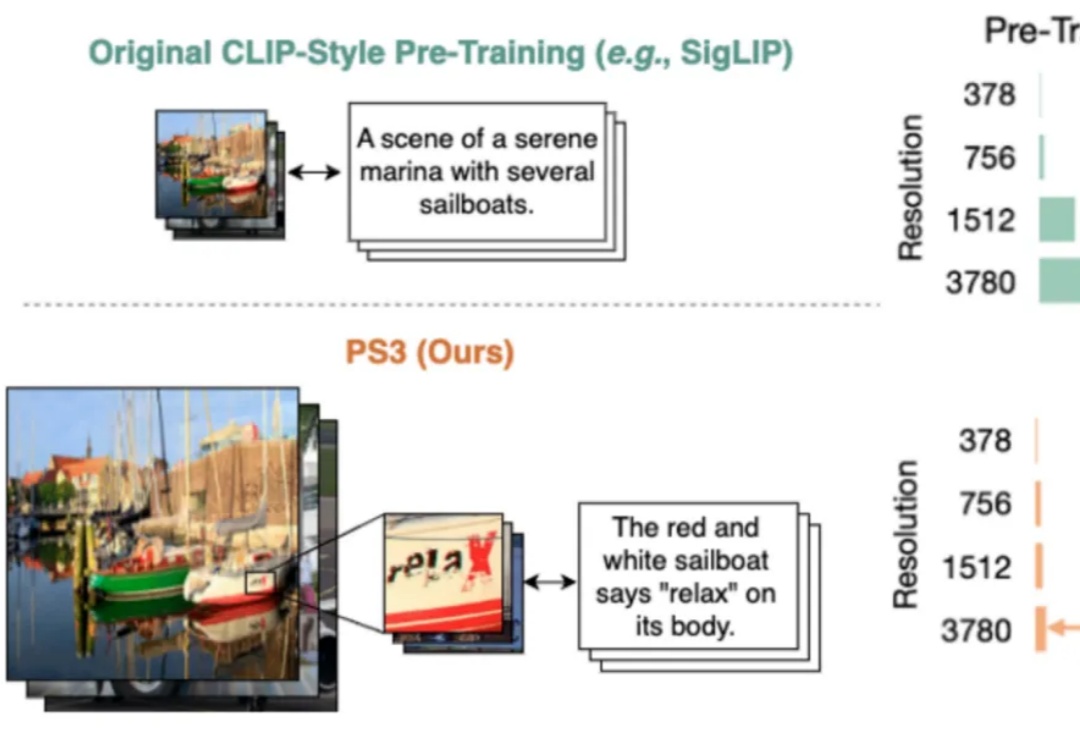
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
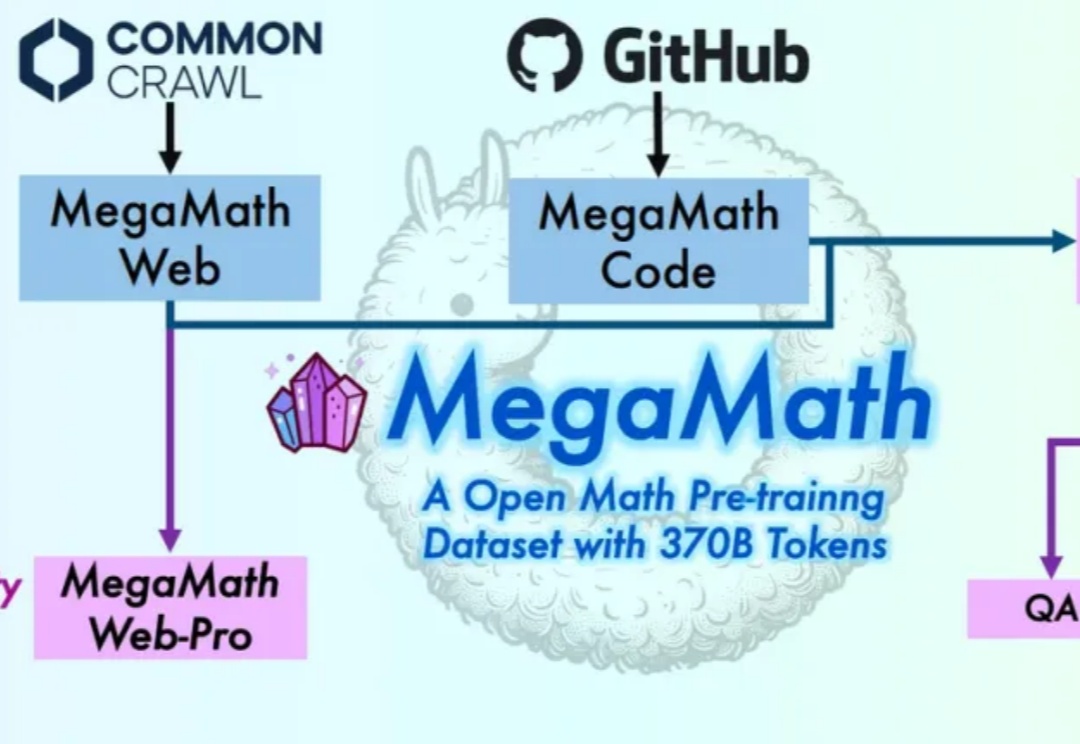
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?