华为CloudMatrix384超节点很强,但它的「灵魂」在云上
华为CloudMatrix384超节点很强,但它的「灵魂」在云上AI 领域最近盛行一个观点:AI 下半场已经开始,评估将比训练重要。而在硬件层级上,我们也正在开始进入一个新世代。
来自主题: AI资讯
11149 点击 2025-07-03 11:39
 搜索
搜索
AI 领域最近盛行一个观点:AI 下半场已经开始,评估将比训练重要。而在硬件层级上,我们也正在开始进入一个新世代。

今年的政府工作报告提出,持续推进“人工智能+”行动,将数字技术与制造优势、市场优势更好结合起来,支持大规模广泛应用。这是“人工智能+”第二次被写入政府工作报告,与去年侧重于技术研发和产业集群建设不同,今年的提法更侧重于技术的落地应用,将人工智能的应用重点指向了制造业。

就在刚刚,华为首次亮相了一套“虚”的技术—— 数字化风洞,一个在正式训推复杂AI模型之前,可以在电脑中“彩排”的虚拟环境平台

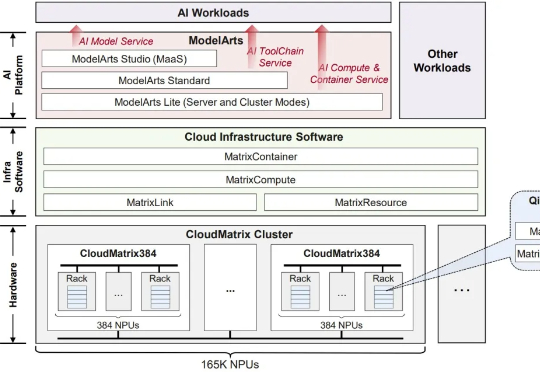
大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。
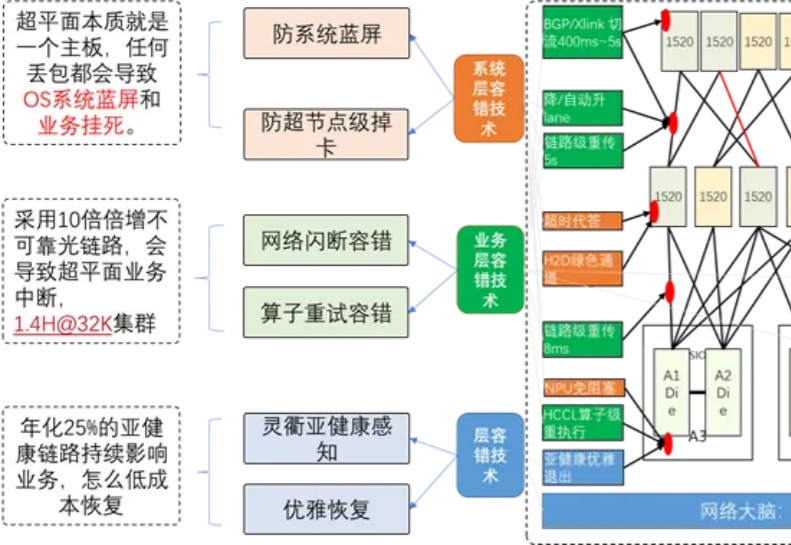
你是否注意到,现在的 AI 越来越 "聪明" 了?能写小说、做翻译、甚至帮医生看 CT 片,这些能力背后离不开一个默默工作的 "超级大脑工厂"——AI 算力集群。
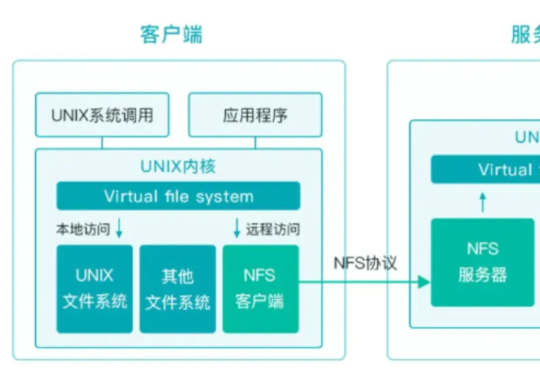
经过对多种开源存储系统的评估对比,我们选择了 JuiceFS 。我们的架构采用 Redis 进行高性能元数据管理,同时构建了自有 MinIO 集群作为底层对象存储,这一架构完美解决了模型训练场景中的数据读写瓶颈、元数据访问延迟以及计算资源之间的存储互通问题。

现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。
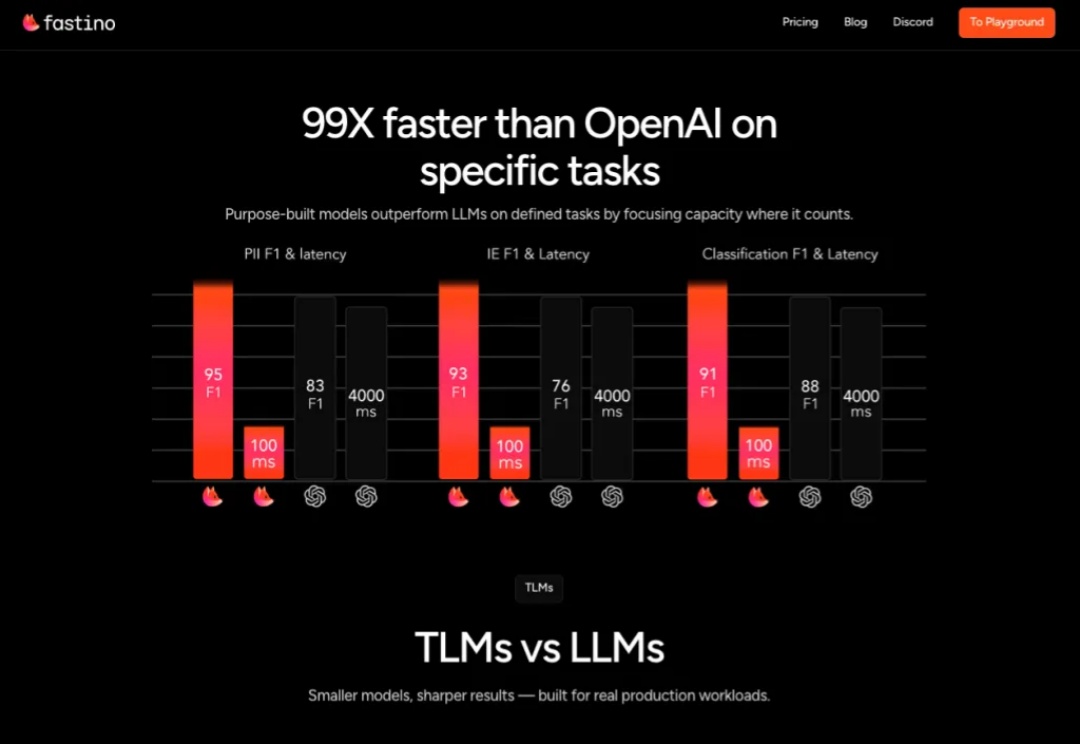
科技巨头常吹嘘需要庞大昂贵GPU 集群的万亿参数 AI 模型,但 Fastino 正采取截然不同的策略

昨日,北京市知识产权局党组成员、副局长潘新胜在参加百度活动时表示,北京正在全力推进建设具有全球影响力的人工智能创新策源地和产业高地,打造世界级人工智能产业集群。
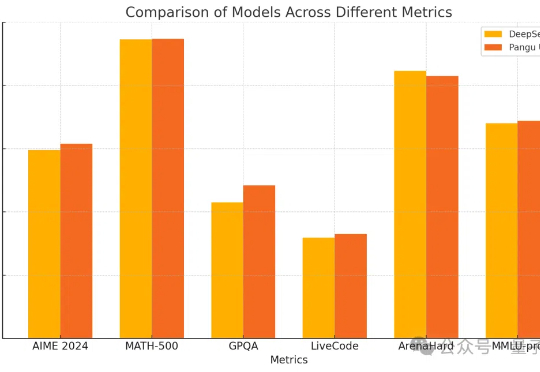
密集模型的推理能力也能和DeepSeek-R1掰手腕了?