EasyCache:无需训练的视频扩散模型推理加速——极简高效的视频生成提速方案
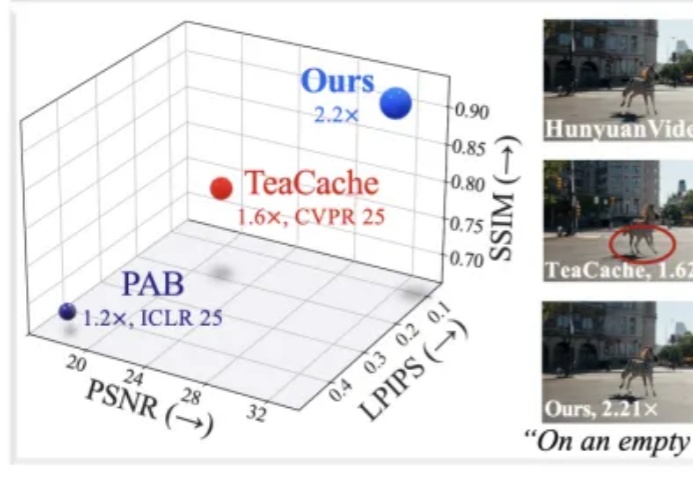
EasyCache:无需训练的视频扩散模型推理加速——极简高效的视频生成提速方案近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
来自主题: AI技术研报
8694 点击 2025-07-14 10:42