
OpenAI诈骗?GPT-4.1正式上线ChatGPT,网友实测却大呼失望
OpenAI诈骗?GPT-4.1正式上线ChatGPT,网友实测却大呼失望GPT-4.1,在ChatGPT中可用了!现在,它不仅在API中开放,Plus、Pro和Team用户都可以使用。网友们兴奋地展开实测后,纷纷吐槽:OpenAI这是诈骗吧,说好的一百万超长上下文呢?
来自主题: AI资讯
12029 点击 2025-05-15 12:08
 搜索
搜索
GPT-4.1,在ChatGPT中可用了!现在,它不仅在API中开放,Plus、Pro和Team用户都可以使用。网友们兴奋地展开实测后,纷纷吐槽:OpenAI这是诈骗吧,说好的一百万超长上下文呢?

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
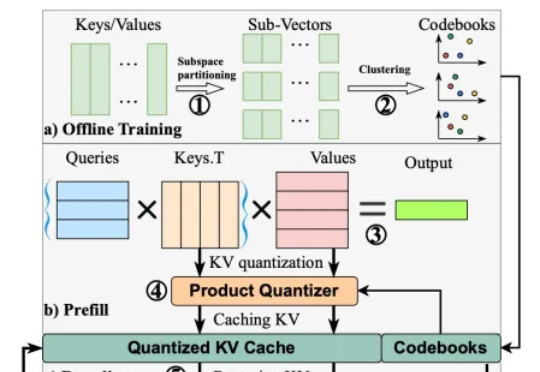
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。
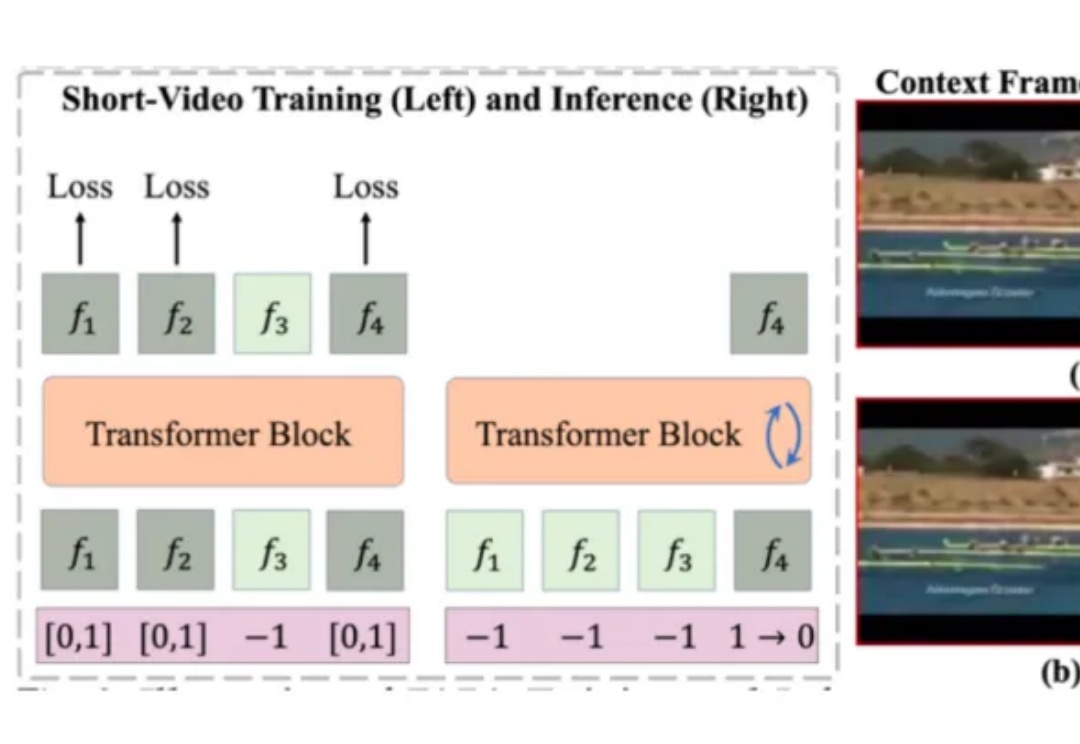
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。

一句话看懂:o3以深度推理与工具调用能力领跑复杂任务,GPT-4.1超长上下文与精准指令执行适合API开发,而o4-mini则堪称日常任务的「性价比之王」。

OpenAI重磅发布的GPT-4.1系列模型,带来了编程、指令跟随和长上下文处理能力的全面飞跃!由中科大校友Jiahui Yu领衔的团队打造。与此同时,备受争议的GPT-4.5将在三个月后停用,GPT-4.1 nano则以最小、最快、最便宜的姿态强势登场。

今天在各大信息渠道看到 Llama4 发布的消息,一上来就放出三个模型,具体能力这里就不在赘述,相信大家已经多少看到不少介绍了。
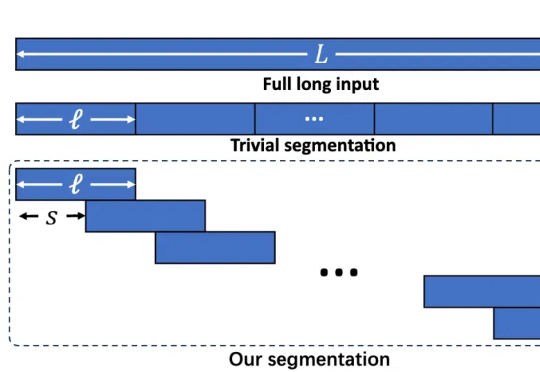
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。

LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?