从高考到实战,豆包大模型交卷了
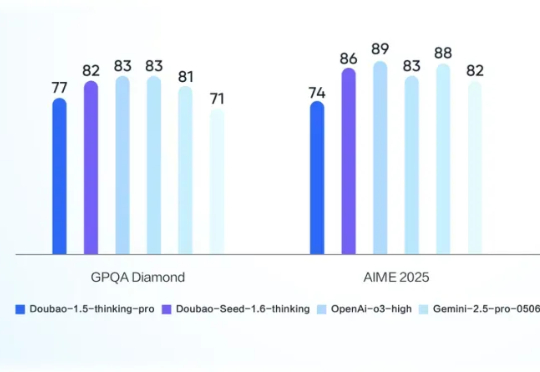
从高考到实战,豆包大模型交卷了高考余热尚在,依然还是有不少博主和媒体在测试各家 AI 模型解答最新高考题的能力。而现在,一个正被火热评测的主流模型迎来了重磅升级!
来自主题: AI资讯
13646 点击 2025-06-12 15:10
 搜索
搜索
高考余热尚在,依然还是有不少博主和媒体在测试各家 AI 模型解答最新高考题的能力。而现在,一个正被火热评测的主流模型迎来了重磅升级!

3 月 18 日上午,字节跳动豆包大模型部门(Seed)召开全员会,由负责模型应用相关工作的朱文佳,与新近加入的负责 AI 基础研究探索工作的吴永辉共同主持。两人谈到了未来的目标,明确 Seed 部门的最重要目标是探索智能上限;同时强调进一步加强组织文化,提高技术开放程度,并考虑推进开源。
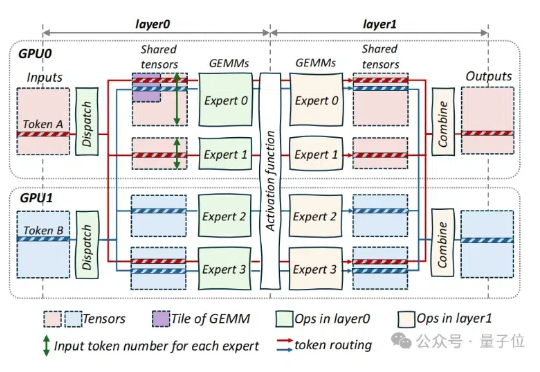
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。
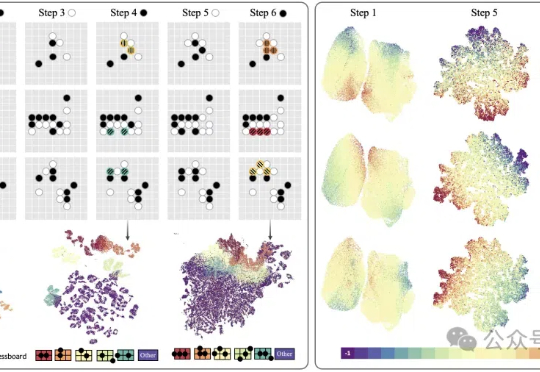
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。

实际上 Operator 只是最近一段时间,全球大模型公司智能体集中发布浪潮的一部分。早于 Operator 发布前两天,字节跳动豆包大模型团队就已经公布了同类型智能体:UI-TARS。
昨天豆包大模型 1.5 全家桶正式发布了嘛,官方刚发布 15 分钟,就被咱们 Family 群里的家人给发现了,并且发出灵魂拷问——谁能测测?

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。

在社交平台分享“显眼包”的帖子中,频繁出现“出吗”、“高价收”类似的评论。“显眼包”是字节此前给客户送出去的玩具,区别传统玩具,这是一款内嵌了豆包大模型、扣子专业版、语音识别、语音合成等技术的AI玩具。

人在字节火山发布会现场。 眼睁睁看着他们发了一大堆的模型升级,眼花缭乱,有一种要一股脑把字节系的AI底牌往桌上亮的感觉。 有语音的,有音乐的,有大语言模型的,有文生图的,有3D生成。

12月12日,北京大学-字节跳动“豆包大模型系统软件联合实验室”签约仪式暨“面向大模型的智能化软件技术与生态”学术研讨会在北京大学英杰交流中心隆重举行。