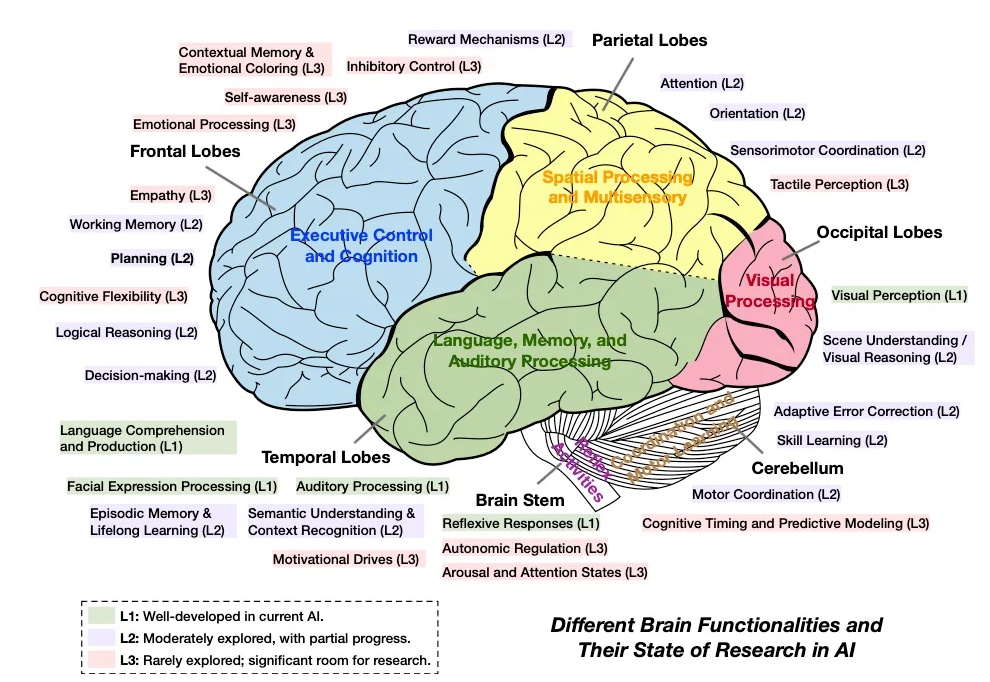
264页智能体综述来了!MetaGPT等20家顶尖机构、47位学者参与
264页智能体综述来了!MetaGPT等20家顶尖机构、47位学者参与近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。
来自主题: AI技术研报
8839 点击 2025-04-21 09:28
 搜索
搜索
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。

谷歌 Gemma 3 上线刚刚过去一个月,现在又出新版本了。

Perplexity AI 公司正与三星电子商讨在其设备上集成虚拟助手事宜,并已与联想集团旗下摩托罗拉达成此类合作协议。

4 月 14 日,谷歌首席科学家 Jeff Dean 在苏黎世联邦理工学院举办的信息学研讨会上发表了一场演讲,主题为「AI 的重要趋势:我们是如何走到今天的,我们现在能做什么,以及我们如何塑造 AI 的未来?」
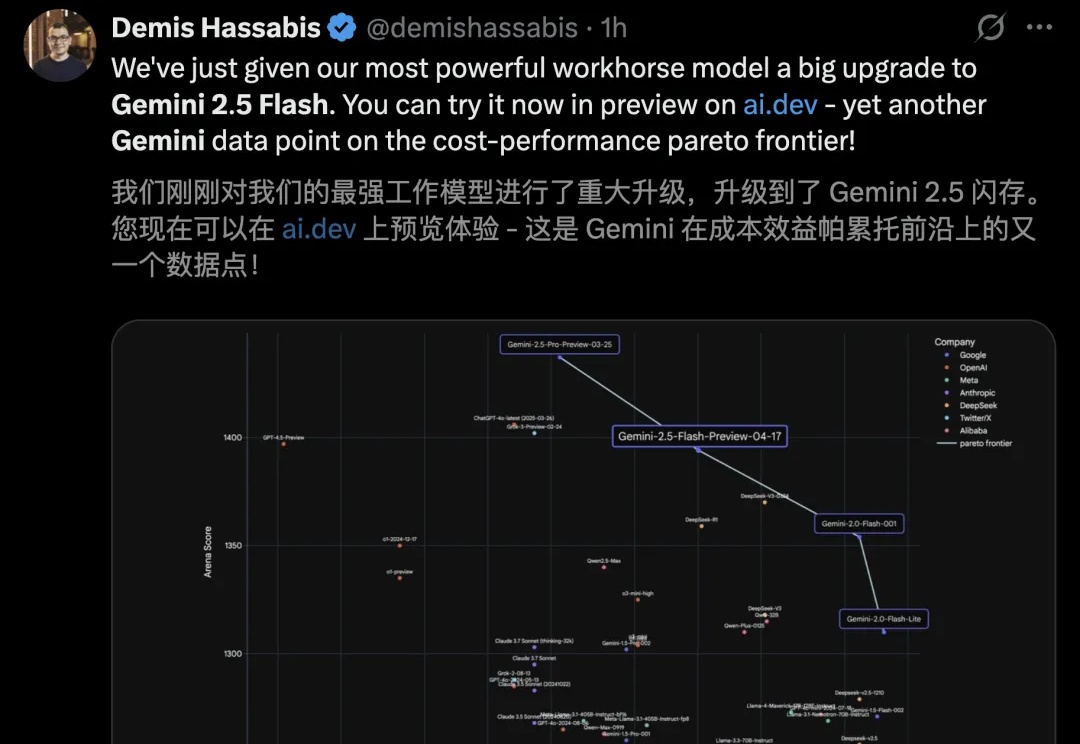
谷歌发布首款混合推理模型Gemini 2.5 Flash,引入了革命性「思考预算」,可灵活控制推理深度,性能一举击败Claude 3.7,比肩o4-mini。而且,关闭思考模式成本直降600%。
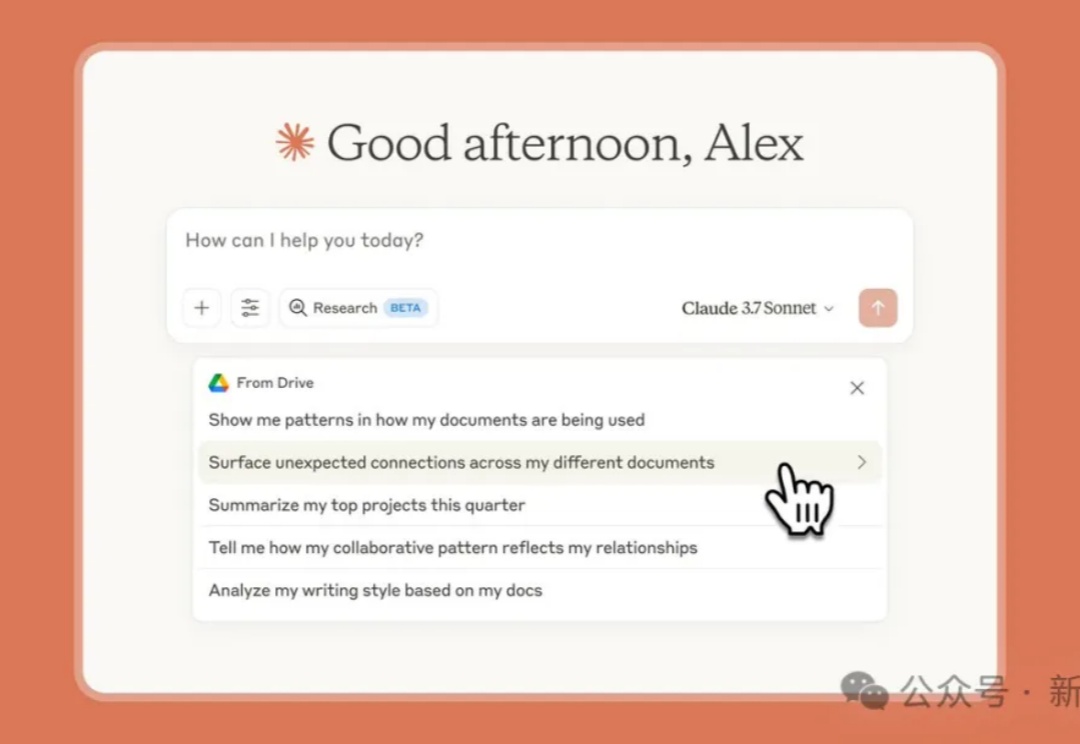
Anthropic推出Claude两大重磅功能:Research与Google Workspace集成!Research功能让Claude快速检索网络与内部文件,精准回答复杂问题;而与Google Workspace的深度整合,则让用户能无缝调用Gmail、日历和文档信息,轻松完成从行程规划到报告撰写的任务。

人类生成的数据推动了人工智能的惊人进步,但接下来会怎样呢?

想象一个世界:AI 智能体不再仅仅为你工作,更能彼此协作,形成强大的合力。谷歌的智能体到智能体(A2A)协议,正致力于将孤立的 AI 执行者转变为高效的协作团队。但它与 Anthropic 的模型上下文协议(MCP)相比,孰优孰劣?本文将为您深入剖析。
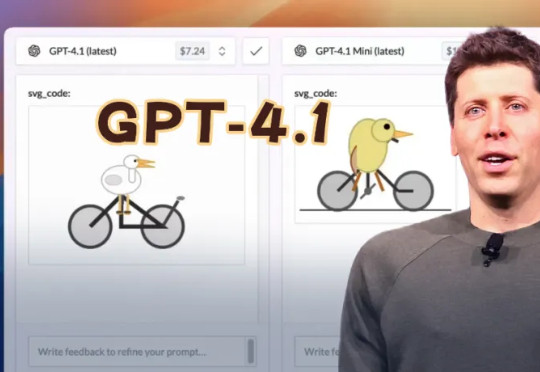
两个月后就号称要淘汰GPT-4.5的GPT-4.1,实力究竟如何?在众多实测中,它的表现的确可圈可点,但却依然打不过Gemini 2.5 Pro和Claude 3.7 Sonnet。那么问题来了,OpenAI为何要发布一个远远落后于谷歌的模型?
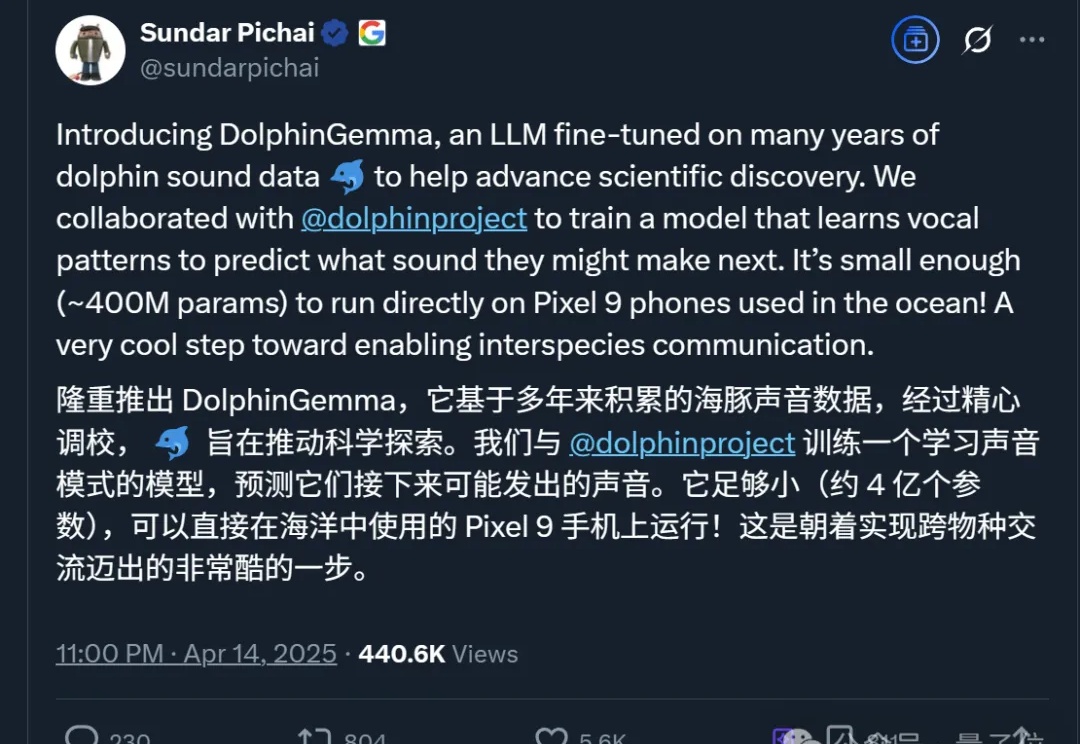
神奇!人类和海豚真的能实现跨物种交流了?!