百万围观、HuggingFace多模态登顶,华人团队FlashLabs开源语音模型Chroma 1.0
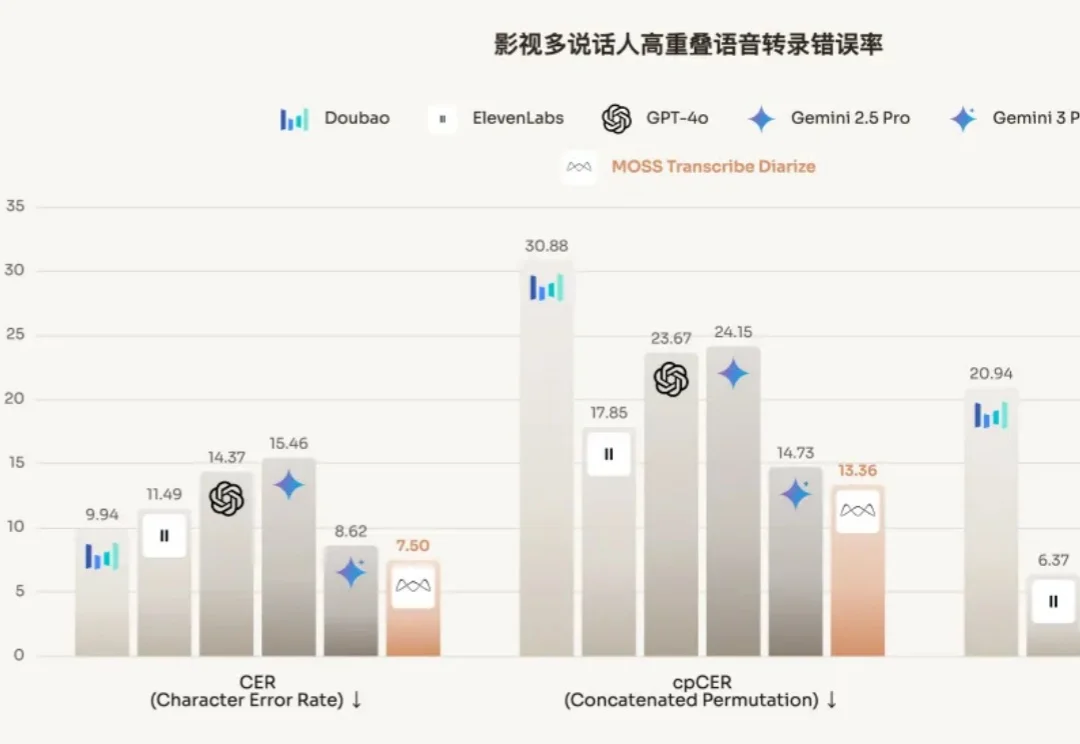
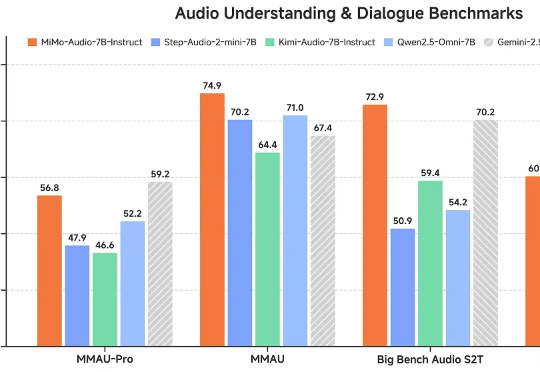
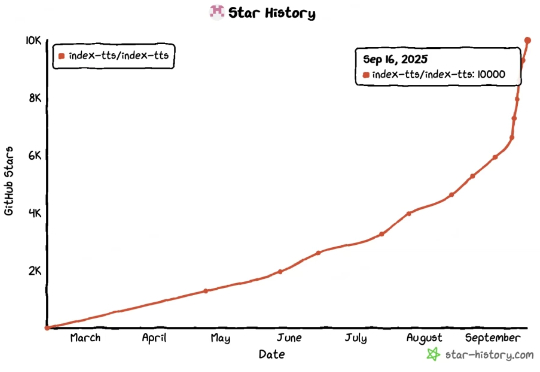
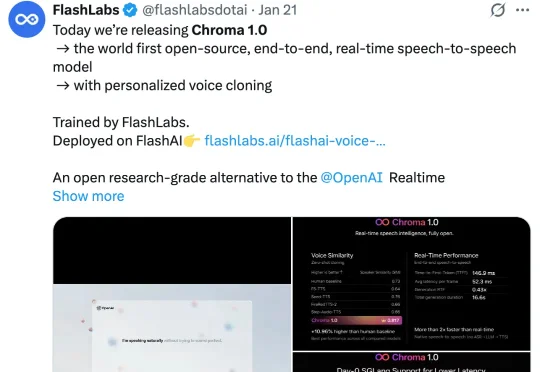
百万围观、HuggingFace多模态登顶,华人团队FlashLabs开源语音模型Chroma 1.0近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。
来自主题: AI资讯
9535 点击 2026-01-23 16:25