
新架构RNN反超Transformer:每个隐藏状态都是一个模型,一作:从根本上改变语言模型
新架构RNN反超Transformer:每个隐藏状态都是一个模型,一作:从根本上改变语言模型新架构,再次向Transformer发起挑战!
来自主题: AI技术研报
7356 点击 2024-07-09 15:11
 搜索
搜索
新架构,再次向Transformer发起挑战!

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力
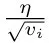
在训练大型语言模型(LLM)时,Adam(W) 基本上已经成为了人们默认使用的优化器。

瑞士苏黎世联邦理工学院的研究者发现,为ChatGPT等聊天机器人提供支持的大型语言模型可以从看似无害的对话中,准确推断出数量惊人的用户个人信息,包括他们的种族、位置、职业等。

近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。

大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。

只有10亿参数的xLAM-1B在特定任务中击败了LLM霸主:OpenAI的GPT-3.5 Turbo和Anthropic的Claude-3 Haiku。上个月刚发布的苹果智能模型只有30亿参数,就连奥特曼都表示,我们正处于大模型时代的末期。那么,小语言模型(SLM)会是AI的未来吗?

开源大语言模型(LLM)百花齐放,为了让它们适应各种下游任务,微调(fine-tuning)是最广泛采用的基本方法。基于自动微分技术(auto-differentiation)的一阶优化器(SGD、Adam 等)虽然在模型微调中占据主流,然而在模型越来越大的今天,却带来越来越大的显存压力。

检索增强式生成(RAG)是一种使用检索提升语言模型的技术。
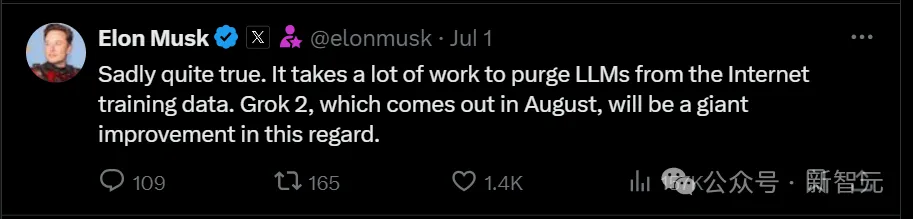
马斯克连回两条推文为xAI造势,宣布8月发布Grok 2,年底将推出在10万张H100上训练的Grok 3,芯片加持创新数据训练,打造对标GPT的新一代大语言模型。