
Ferret-UI 2:苹果最新跨平台通用GUI理解多模态大模型
Ferret-UI 2:苹果最新跨平台通用GUI理解多模态大模型Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。
来自主题: AI技术研报
8948 点击 2024-11-01 12:27
 搜索
搜索
Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

大模型固然性能强大,但限制也颇多。如果想在端侧塞进 405B 这种级别的大模型,那真是小庙供不起大菩萨。近段时间,小模型正在逐渐赢得人们更多关注。这一趋势不仅出现在语言模型领域,也出现在了机器人领域。
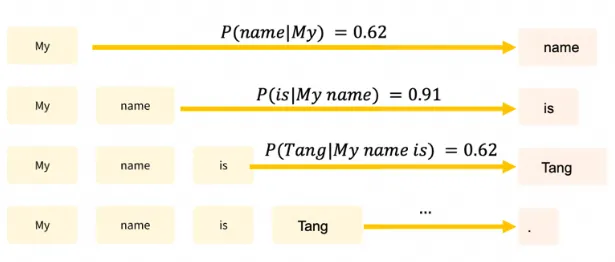
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。

在当前大语言模型(LLM)蓬勃发展的环境下,Prompt工程师们面临着一个两难困境:要么使用像LangChain这样功能强大但学习曲线陡峭的框架,要么选择自动化程度更高DSPy但牺牲了对提示词精确控制的工具。IBM研究院和UC Davis大学最近推出的PDL(Prompt Declaration Language,提示词声明语言)或许打破了这个困境,让AI开发者能真正拿回Prompt的控制权。

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
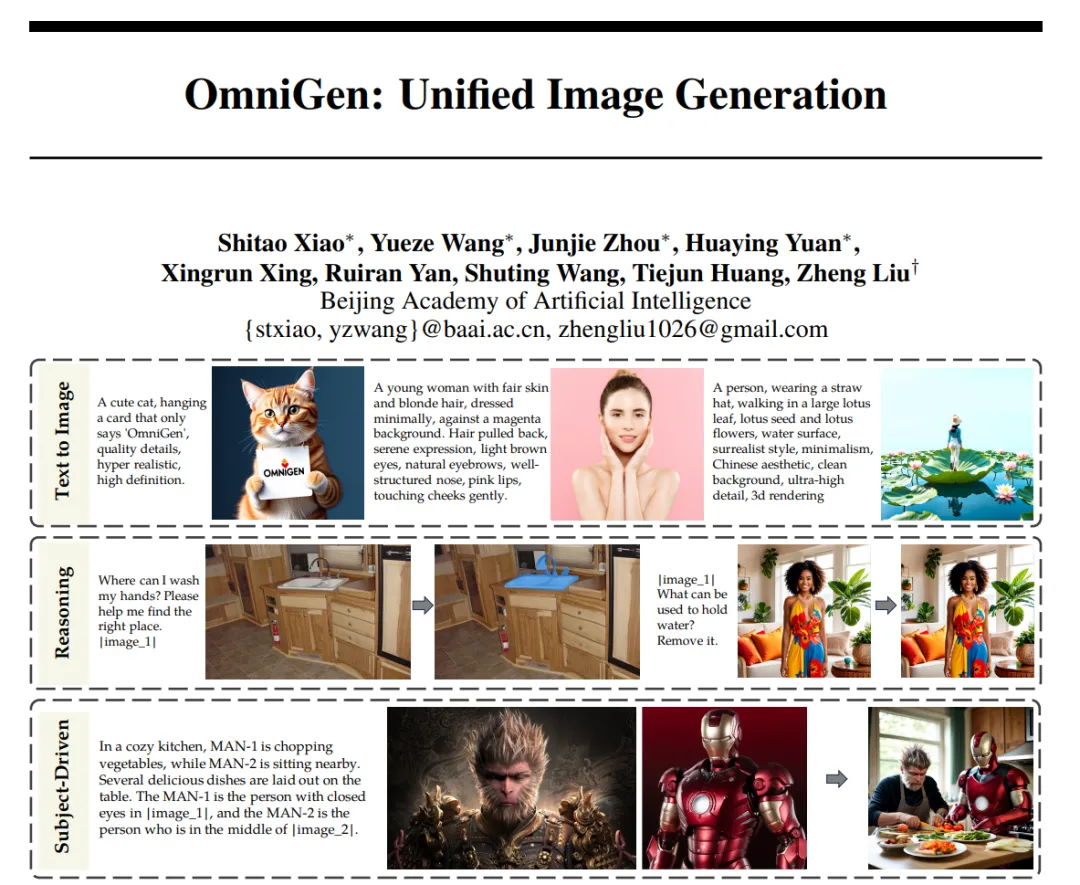
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。
AI裁判通过反馈生成更公正报告,接近共识。
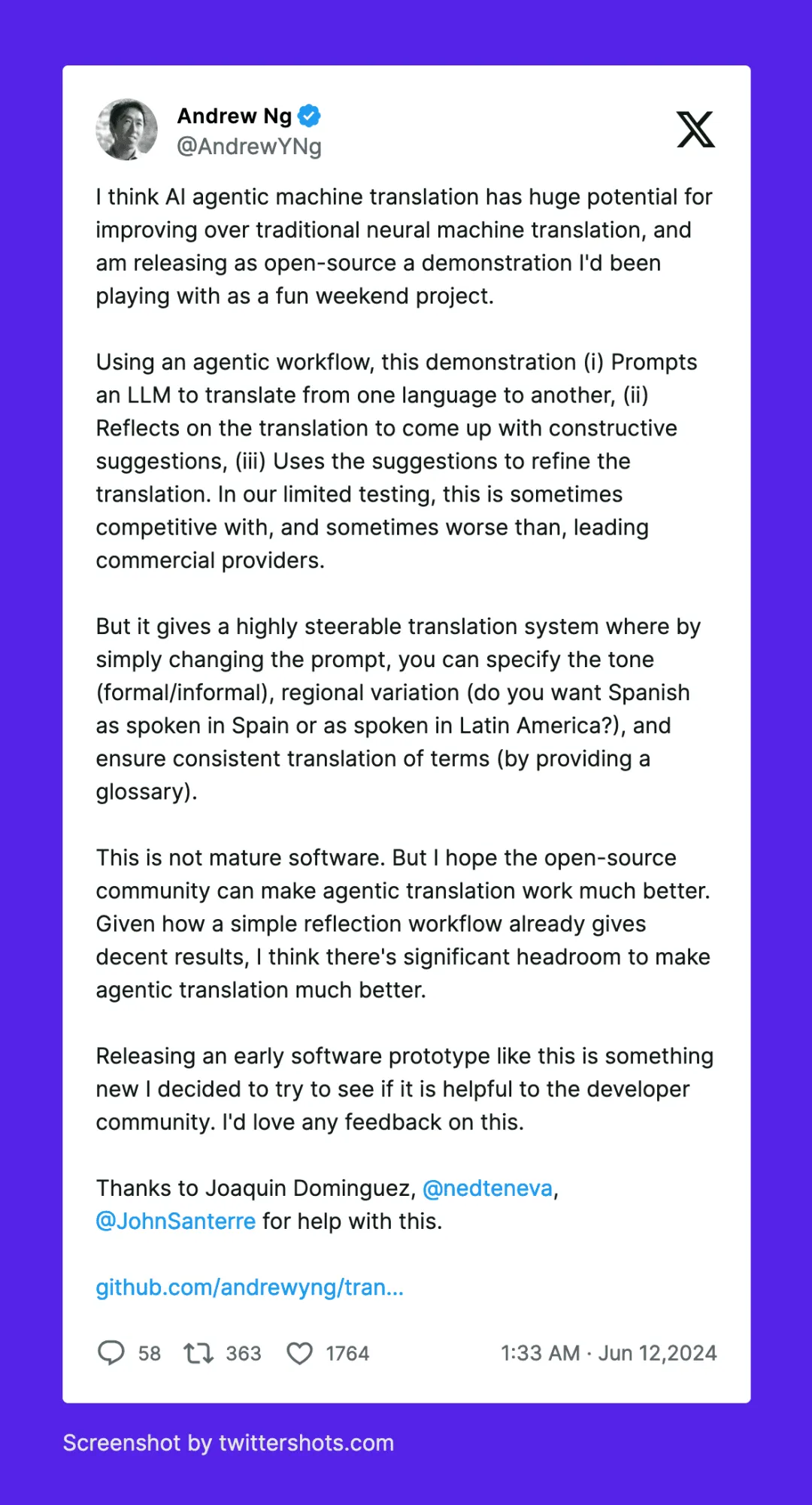
吴恩达老师提出了一种反思翻译的大语言模型 (LLM) AI 翻译工作流程