
推理模型规划任务成功率从5%到95%,DeepMind遗传算法新研究火了
推理模型规划任务成功率从5%到95%,DeepMind遗传算法新研究火了瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。
来自主题: AI技术研报
9951 点击 2025-01-24 15:05
 搜索
搜索
瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。
设想一场高度智能的模拟游戏,游戏的角色不再是普通的NPC,而是由大语言模型驱动的智能体。在这其中,悄然生出一个趣事——在人类的设计下,这些新NPC的言行不经意间变得过于啰嗦。

李继刚在消失半年后,带着汉语新解重新归来,一出手大家就惊呼李继刚的prompt已经到了next level。但不懂编程的小白又懵逼了!怎么提示词也开始编程了?大语言模型的优势不是通过说话就能达成需求吗?怎么又开始需要编程了?技术在倒退吗?
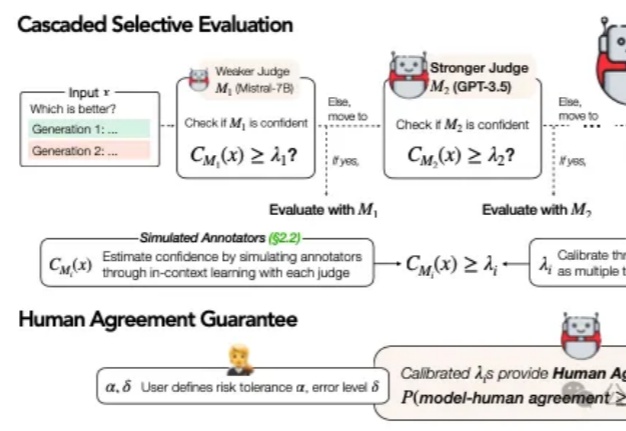
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。

模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。
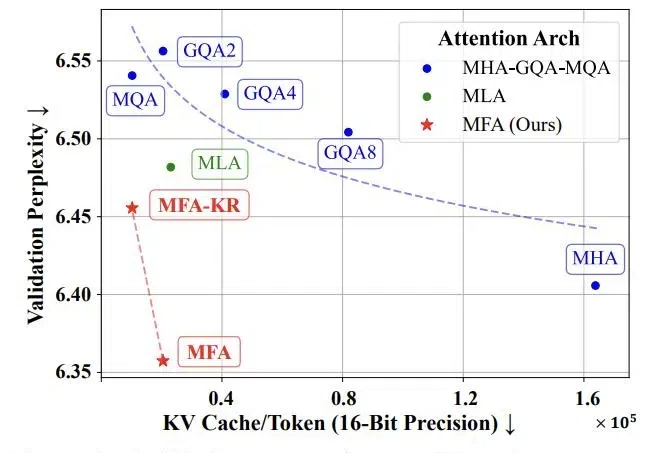
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。

在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。

开源模型上下文窗口卷到超长,达400万token! 刚刚,“大模型六小强”之一MiniMax开源最新模型—— MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。

在软件开发过程中,测试用例的生成一直是一个既重要又耗时的环节。近年来,大型语言模型(LLM)在这一领域展现出了巨大的潜力。然而,实践表明,即使是同一个提示词(Prompt),在不同的LLM上也会产生截然不同的效果。