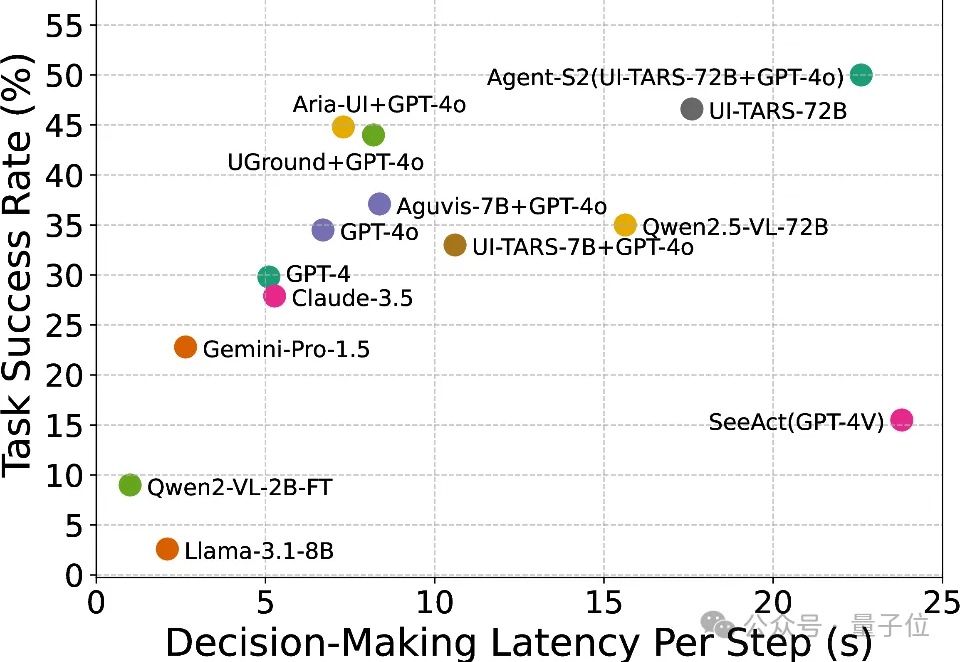
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。
来自主题: AI技术研报
4556 点击 2025-04-03 15:19
 搜索
搜索
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。
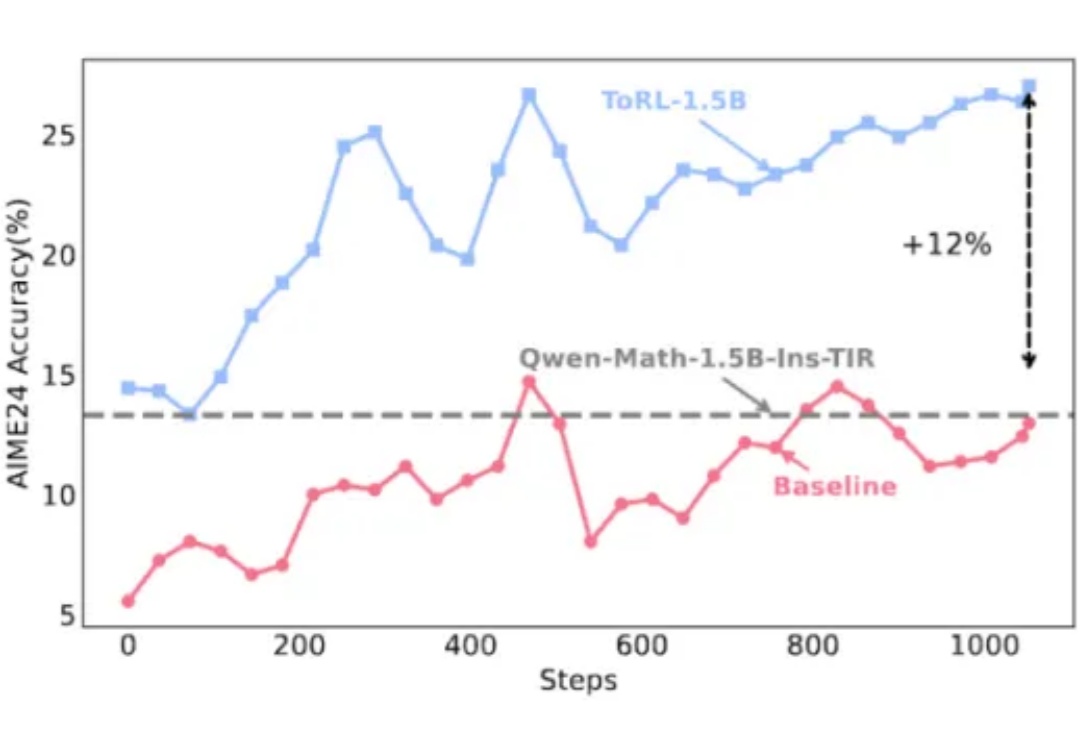
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。

一夜之间,OpenAI更新三大动向,开源、融资、用户暴增。第一,将开源一个具备推理能力的大语言模型,包含参数权重那种。上一次这样开源还是6年前推出GPT-2。
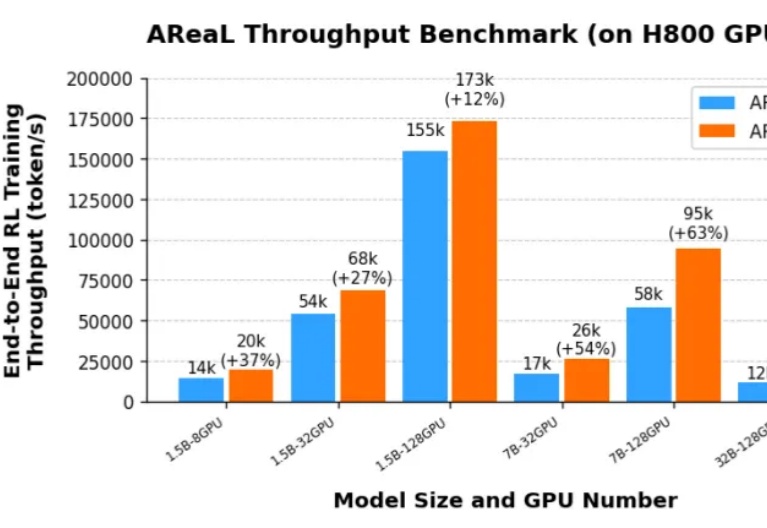
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:

你是否曾对着一个繁复的AI框架,无奈地想:"真有必要搞得这么复杂吗?"在与臃肿框架斗争一年后,Zachary Huang博士决定大刀阔斧地革新,剔除所有花里胡哨的部分。于是Pocket Flow诞生了——一个仅有100行代码的超轻量级大语言模型框架!

关于AI智能体,GDC上腾讯游戏魔方工作室分享了《F.A.C.U.L:首个懂人类语言的 FPS AI 队友》的演讲(这个技术去年就有曝光),项目融合语音输入、大语言模型、实时文本转语音等生成式AI技术,让玩家能与AI队友沉浸式协同作战。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。