
推理正确率下降65.5%!斯坦福、MIT等用「不等式」拷问AI逻辑极限
推理正确率下降65.5%!斯坦福、MIT等用「不等式」拷问AI逻辑极限大语言模型在数学证明中常出现推理漏洞,如跳步或依赖特殊值。斯坦福等高校团队提出IneqMath基准,将不等式证明拆解为可验证的子任务。结果显示,模型的推理正确率远低于答案正确率,暴露出其在数学推理上的缺陷。
来自主题: AI技术研报
10050 点击 2025-06-23 14:41
 搜索
搜索
大语言模型在数学证明中常出现推理漏洞,如跳步或依赖特殊值。斯坦福等高校团队提出IneqMath基准,将不等式证明拆解为可验证的子任务。结果显示,模型的推理正确率远低于答案正确率,暴露出其在数学推理上的缺陷。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。
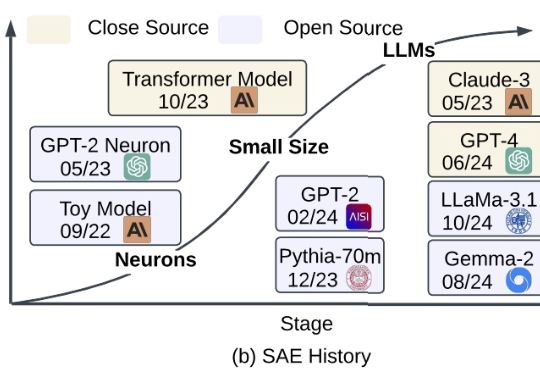
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。
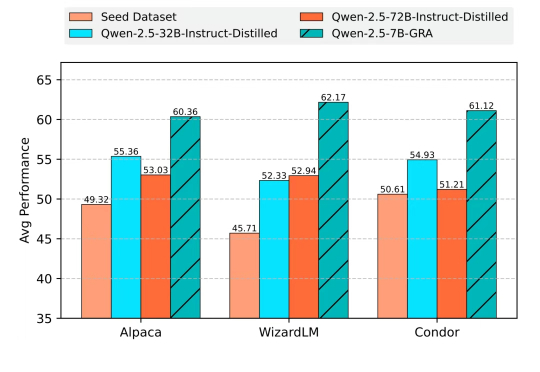
无需蒸馏任何大规模语言模型,小模型也能自给自足、联合提升?
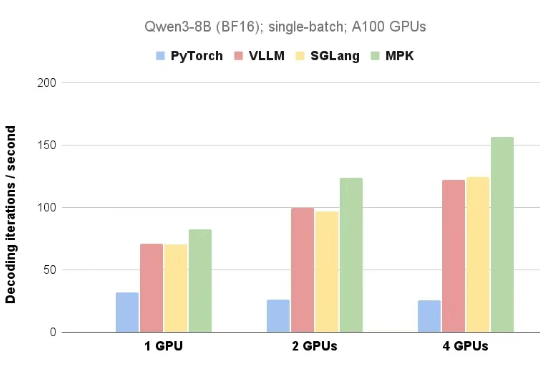
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。

随着语言模型在强化学习和 agentic 领域的进步,agent 正在从通用领域快速渗透到垂直领域,科学和生物医药这类高价值领域尤其受到关注。
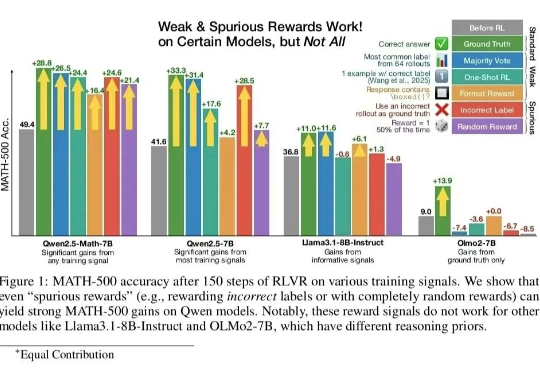
在人工智能领域,大型语言模型(LLM)的推理能力正以前所未有的速度发展。
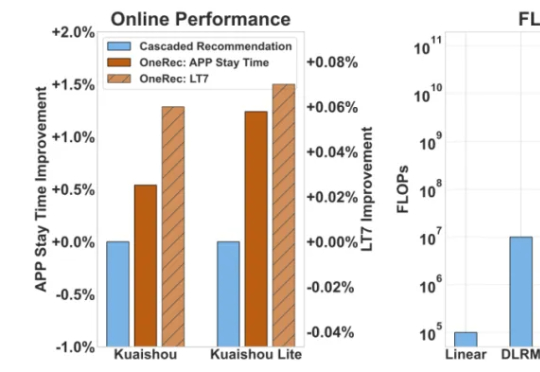
人人都绕不开的推荐系统,如今正被注入新的 AI 动能。 随着 AI 领域掀起一场由大型语言模型(LLM)引领的生成式革命,它们凭借着强大的端到端学习能力、海量数据理解能力以及前所未有的内容生成潜力,开始重塑各领域的传统技术栈。
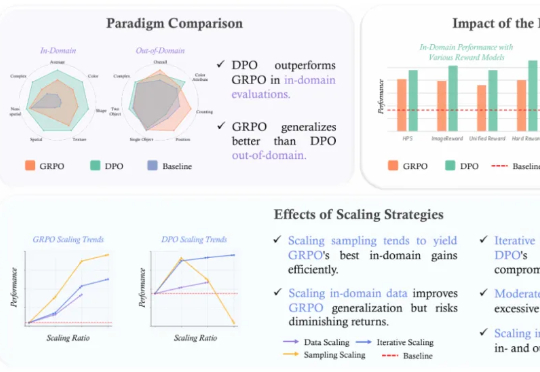
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。