
句子级溯源+生成式归因,C²-Cite重塑大模型可信度
句子级溯源+生成式归因,C²-Cite重塑大模型可信度在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。
来自主题: AI技术研报
6661 点击 2025-12-03 10:44
 搜索
搜索
在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

随着大语言模型与开发工具链的深度融合,命令行终端正被重塑为开发者的AI协作界面。本文以 Google gemini-cli 为范本,通过源码解构,系统性分析其 Agent 内核、ReAct 工作流、工具调用与上下文管理等核心模块的实现原理。为希望构建终端 Agent 的开发者,提供工程实现的系统化参考。
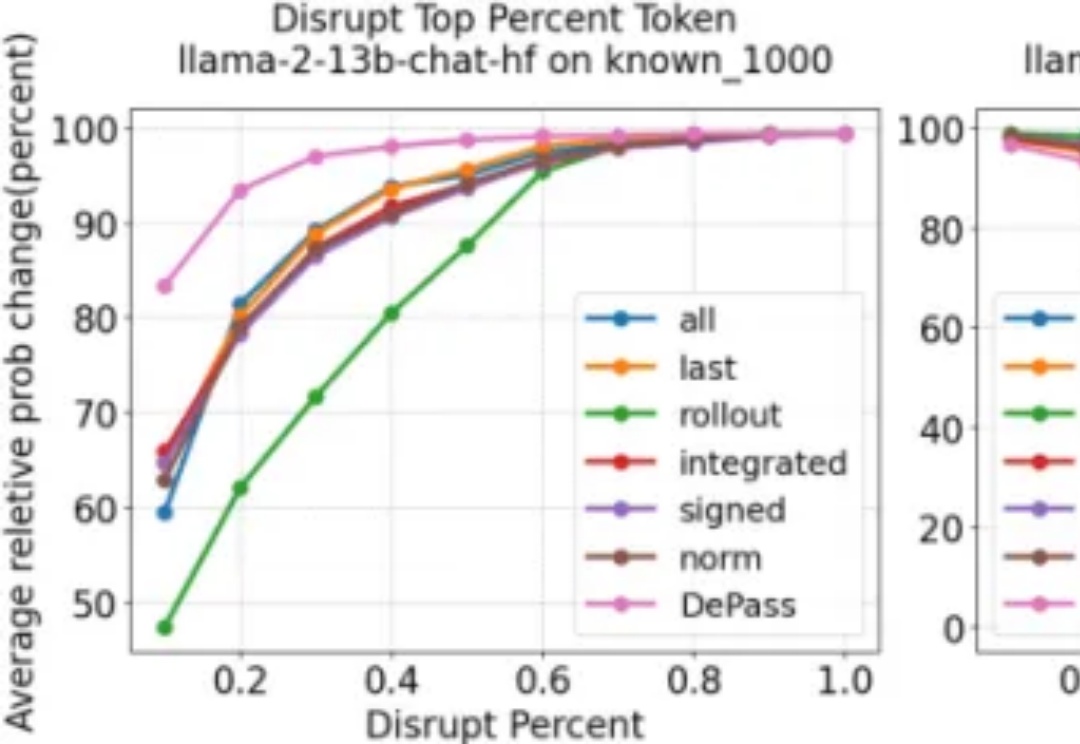
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。
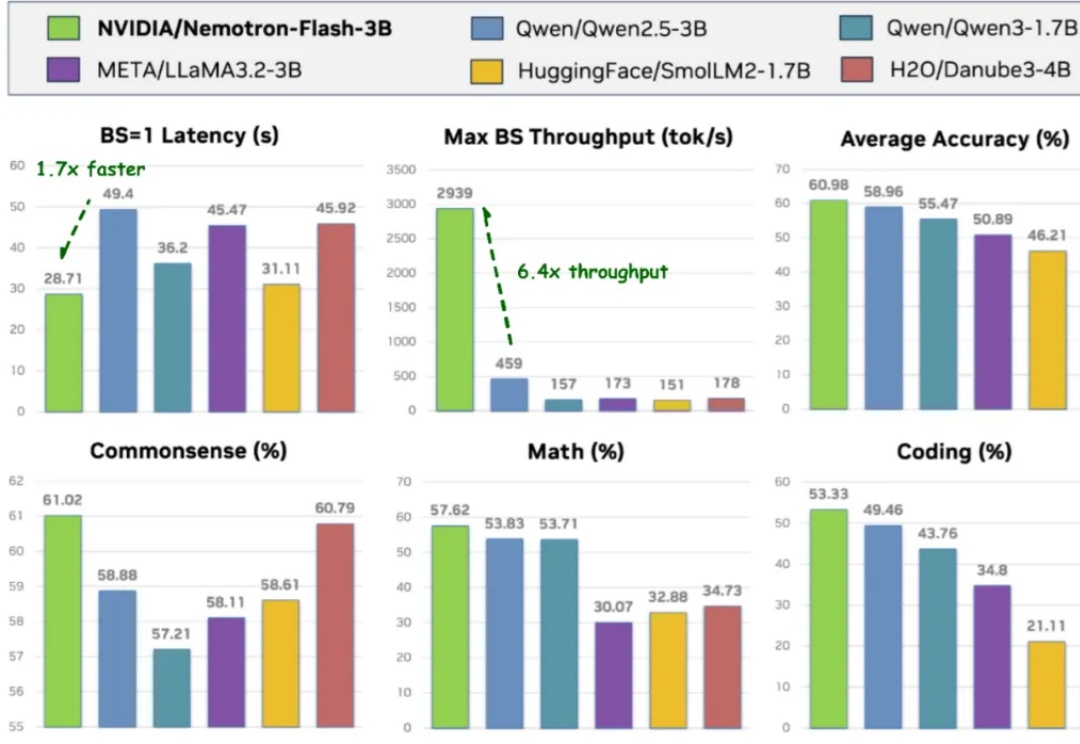
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。

近日,OpenAI被曝正面临越发增长的推理费用,作为有史以来最能烧钱的初创公司,其运行大语言模型的成本可能无法通过收入来支撑。

而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。