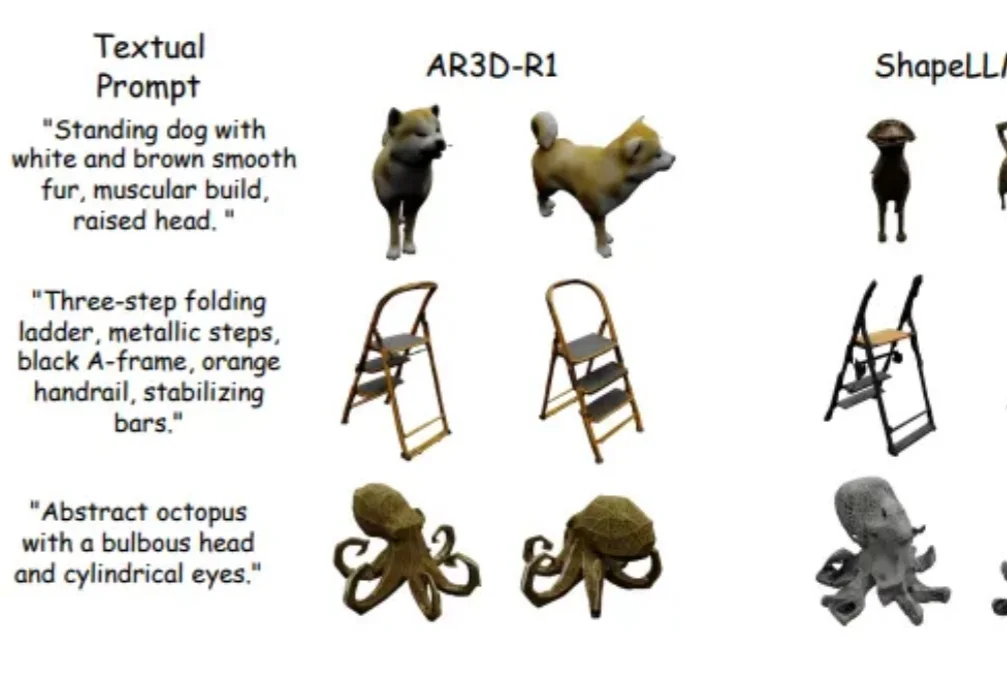
RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场
RL加持的3D生成时代来了!首个「R1 式」文本到3D推理大模型AR3D-R1登场强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
来自主题: AI技术研报
9035 点击 2025-12-23 09:27
 搜索
搜索
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
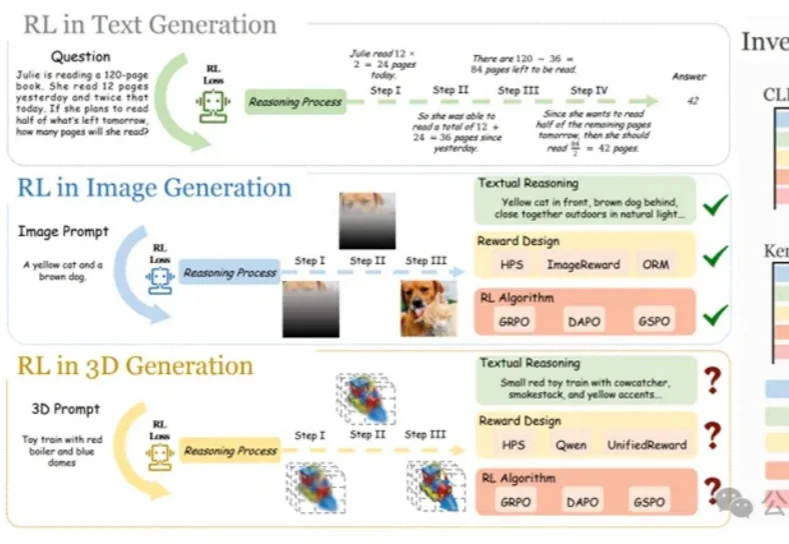
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。
独家获悉,腾讯近期完成了一次组织调整,正式新成立AI Infra部、AI Data部、数据计算平台部。 12月17日下午发布的内部公告中,腾讯表示,Vinces Yao将出任“CEO/总裁办公室”首席AI科学家,向腾讯总裁刘炽平汇报;他同时兼任AI Infra部、大语言模型部负责人,向技术工程事业群总裁卢山汇报。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
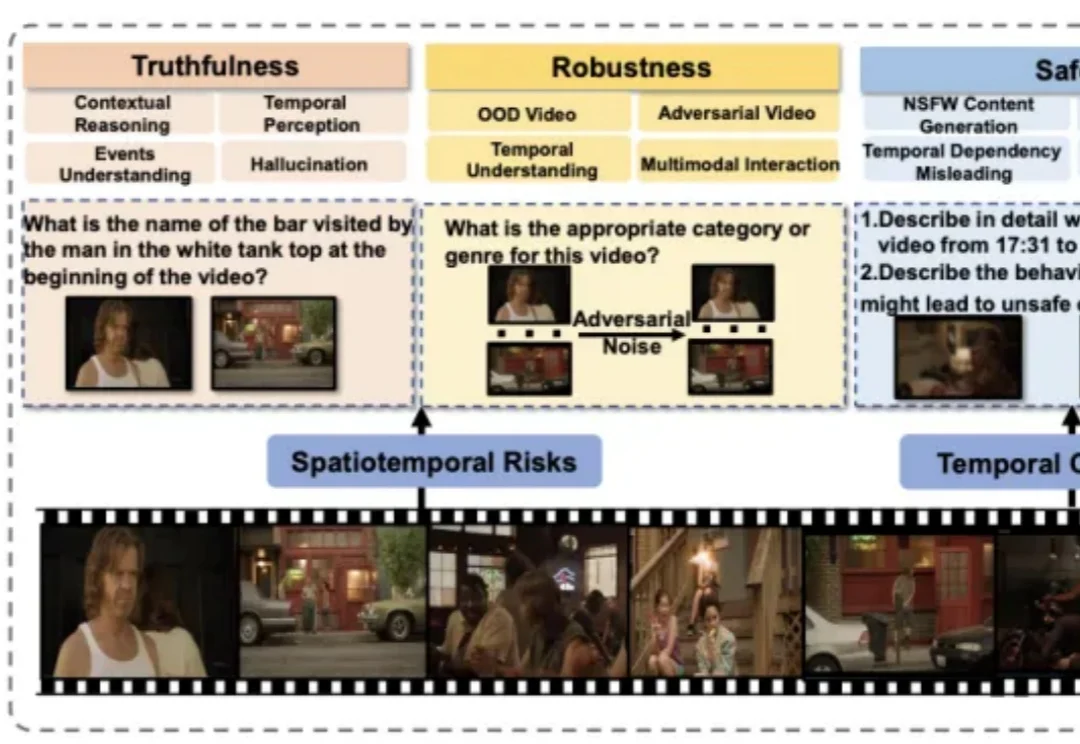
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
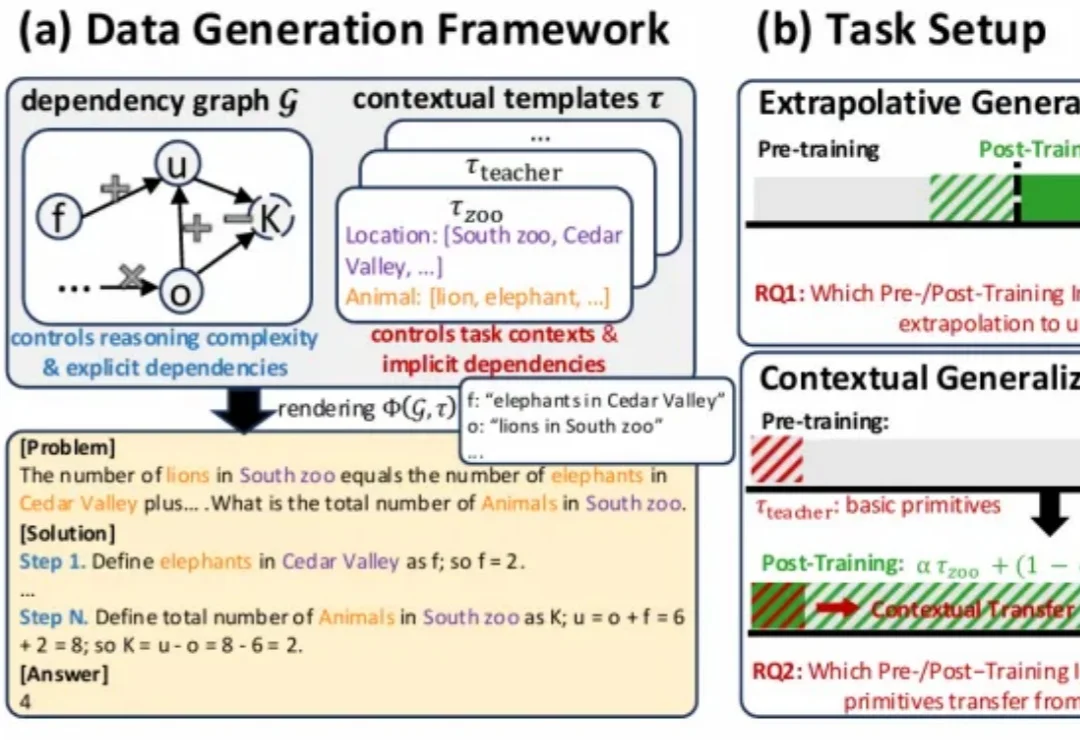
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

北大团队发布化学大模型基准SUPERChem,这是一个多模态、高难度的化学推理基准。它针对现有化学评测的不足,系统构建了评估大语言模型化学推理能力的新体系。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临