深度|成立一年再获数千万融资,坚持结果交付,坚持端对端多智能体
深度|成立一年再获数千万融资,坚持结果交付,坚持端对端多智能体近期,AI营销公司橙果视界(PhotoG母公司)宣布完成数千万元新一轮融资,由云天使基金领投,力合创投和金沙江联合资本跟投。本轮融资将用于进一步扩大行业数据规模,推进垂直行业后训练模型迭代,进一步加快全链路营销智能体在多行业的业务落地,持续探索能感知、决策、创造并执行的商业大脑。
来自主题: AI资讯
9802 点击 2025-09-01 15:06
 搜索
搜索
近期,AI营销公司橙果视界(PhotoG母公司)宣布完成数千万元新一轮融资,由云天使基金领投,力合创投和金沙江联合资本跟投。本轮融资将用于进一步扩大行业数据规模,推进垂直行业后训练模型迭代,进一步加快全链路营销智能体在多行业的业务落地,持续探索能感知、决策、创造并执行的商业大脑。
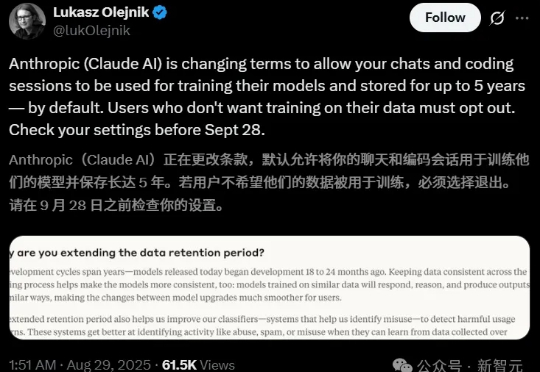
近日,Anthropic更新了它的消费者条款,没想竟把网友惹怒了,有的还把以往的「旧账」都翻了出来。这次网友的反应为啥这么激烈?大家可能还记得在Claude上线之初,Anthropic就坚决表示不会拿用户数据来训练模型。这次变化不仅自己打脸,还把以往一些「背刺」用户的往事都抖搂出来了。
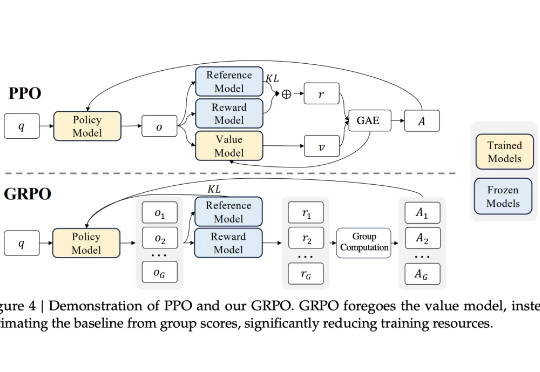
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
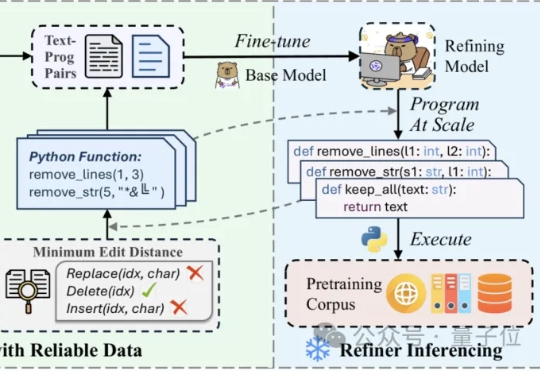
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。
在大模型狂飙的时代,AI 创业被裹挟进一种“技术正统性”的焦虑:要不要训练模型?有没有算力资源?底层自研是不是护城河?但 Yiran,一位本科学钢琴、靠一段自动发邮件脚本开启创业旅程的 00 后女性创业者,选择了另一种路径——她不训练模型,不押技术论文,而是把 AI 做成一个真正能“成事”的销售助理。

预训练模型能否作为探索新架构设计的“底座” ? 最新答案是:yes!

近年来,众多原告——包括书籍、报纸、计算机代码和照片的出版商——起诉人工智能公司使用受版权保护的材料来训练模型。所有这些诉讼中的一个关键问题是,人工智能模型如何轻易地从原告的受版权保护的内容中逐字摘录。

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。

本文由匹兹堡大学智能系统实验室(Intelligent Systems Laboratory)的研究团队完成。第一作者为匹兹堡大学的一年级博士生薛琪耀。

一夜之间,老黄天塌了(doge)。