速递|Buildots完成4500万美元D轮融资,用AI模型+计算机视觉破解建筑业“信息脱节”难题
速递|Buildots完成4500万美元D轮融资,用AI模型+计算机视觉破解建筑业“信息脱节”难题在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。
来自主题: AI资讯
9215 点击 2025-05-30 20:11
 搜索
搜索
在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。

从单张低分辨率(LR)图像恢复出高分辨率(HR)图像 —— 即 “超分辨率”(SR)—— 已成为计算机视觉领域的重要挑战。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
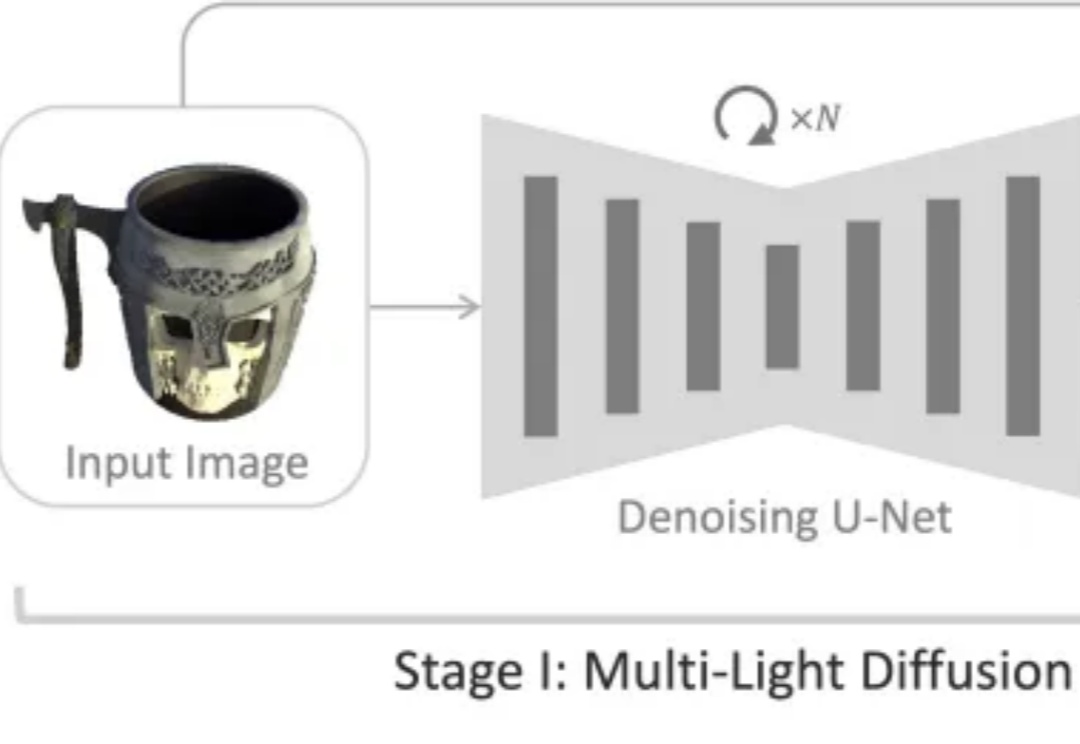
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。
论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。

一夜之间,CV被大模型“解决”了(狗头)。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。
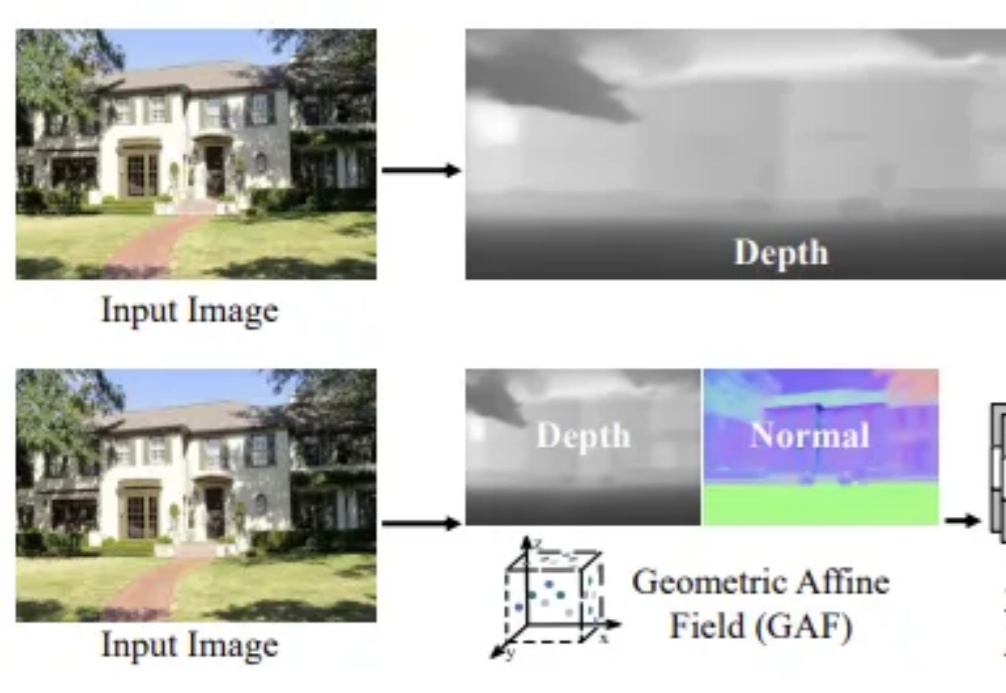
单视角三维场景重建一直是计算机视觉领域中的核心挑战之一,尤其在捕捉高保真室外场景细节时,如何确保结构一致性和几何精度显得尤为困难。
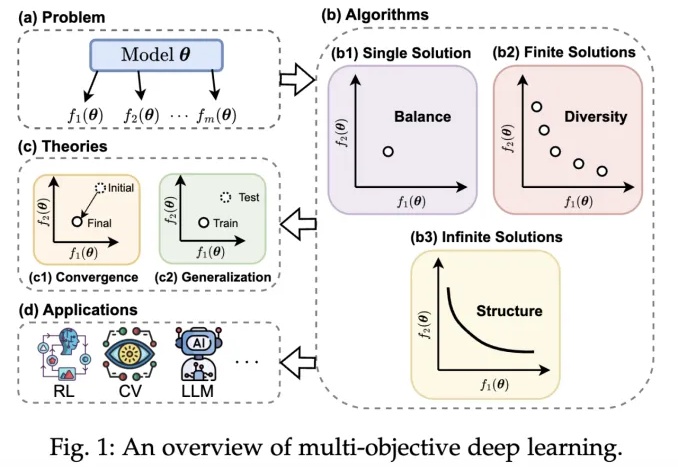
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
硅星人独家获悉,AI视频生成领域独角兽企业爱诗科技完成 A5 轮融资,本轮由靖亚资本独家投资,至此爱诗科技 A 轮融资整体规模已超4亿人民币。爱诗科技成立于2023年4月,公司创始人兼CEO王长虎在计算机视觉和AI领域有20年从业经验,他曾任微软亚洲研究院主管研究员,之后担任字节跳动视觉技术负责人期间,参与了抖音和TikTok等产品从0到1的过程。