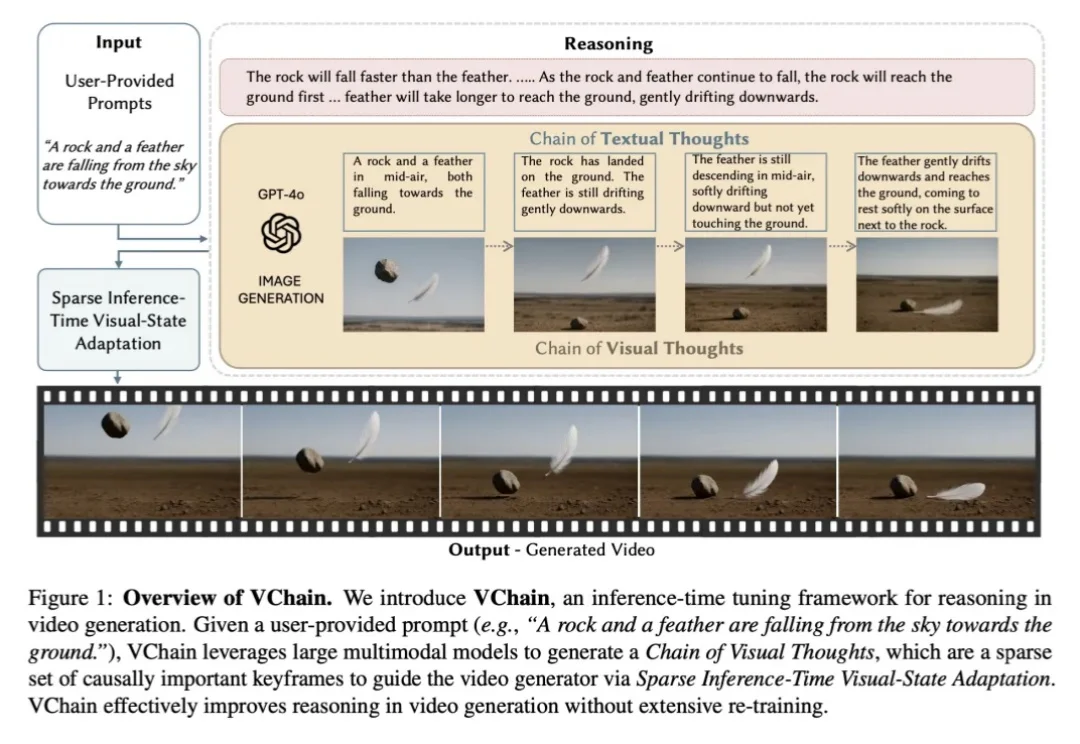
久不发声的美团AI,一开口就开源商用数字人——还把三个闭源大佬给超了
久不发声的美团AI,一开口就开源商用数字人——还把三个闭源大佬给超了就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。
来自主题: AI资讯
9713 点击 2026-05-22 21:38