
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
来自主题: AI技术研报
10401 点击 2025-07-11 10:09
 搜索
搜索
MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
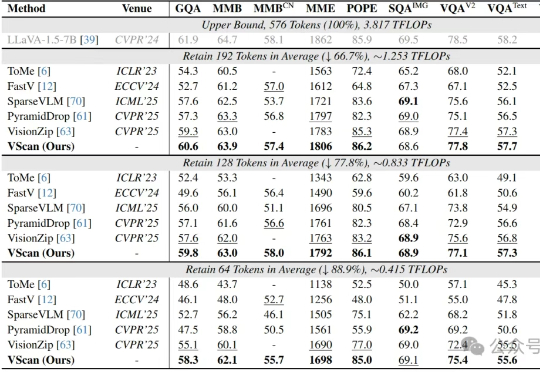
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
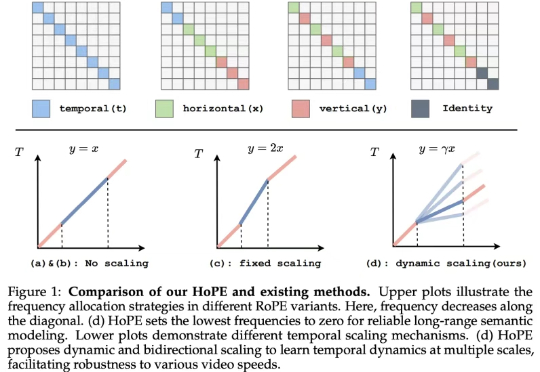
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
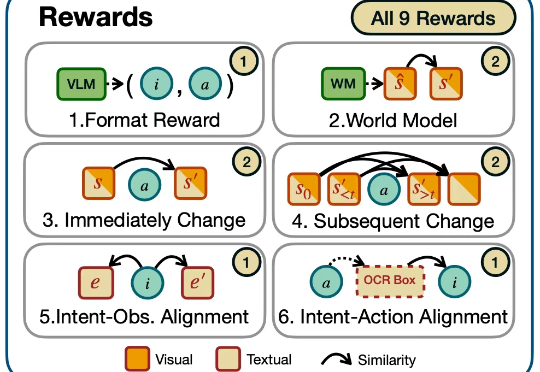
迈向通用人工智能(AGI)的核心目标之一就是打造能在开放世界中自主探索并持续交互的智能体。随着大语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,智能体已展现出令人瞩目的跨领域任务泛化能力。

当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。
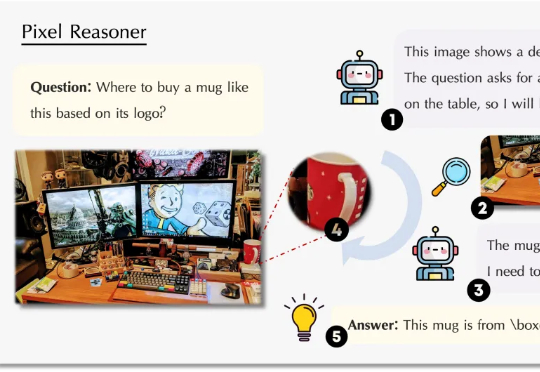
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
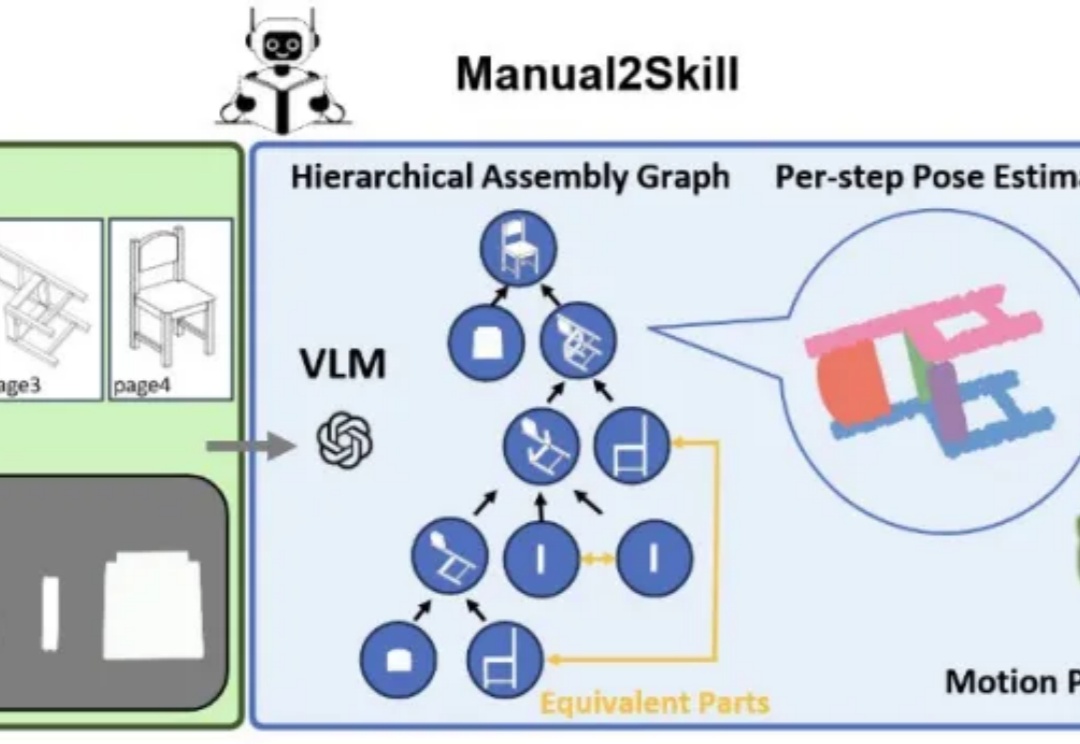
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
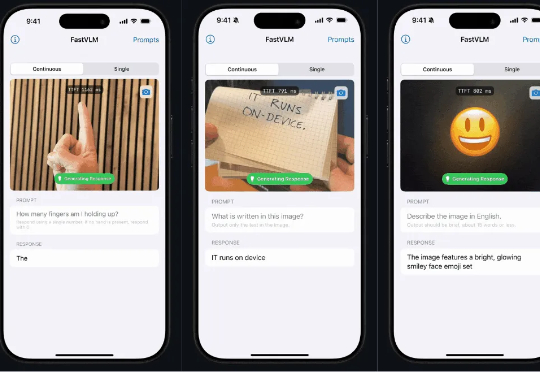
FastVLM—— 让苹果手机拥有极速视觉理解能力