NeurIPS 2025 | ARGRE框架实现高效LLM解毒:自回归奖励引导,安全对齐更快、更准、更轻
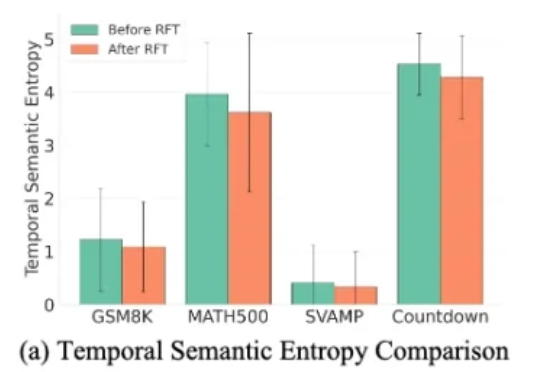
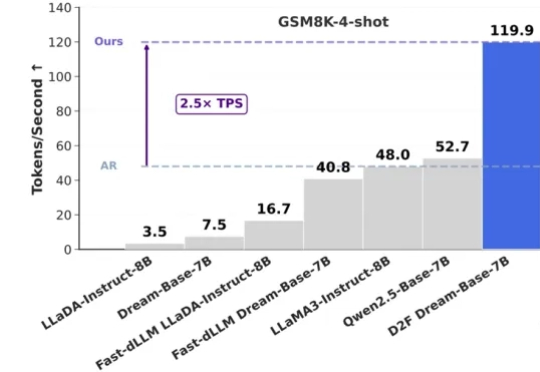
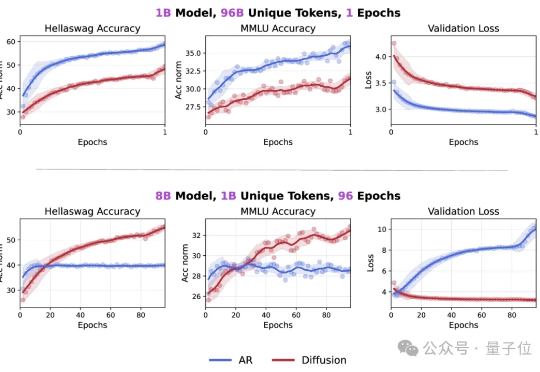
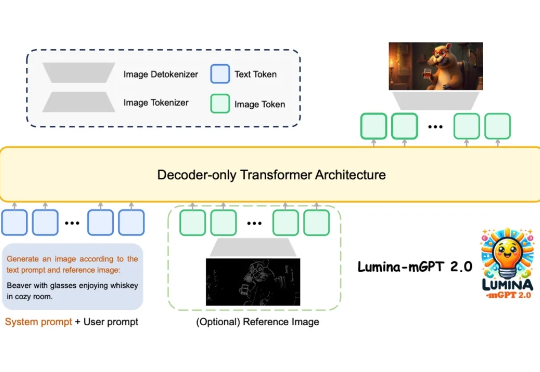
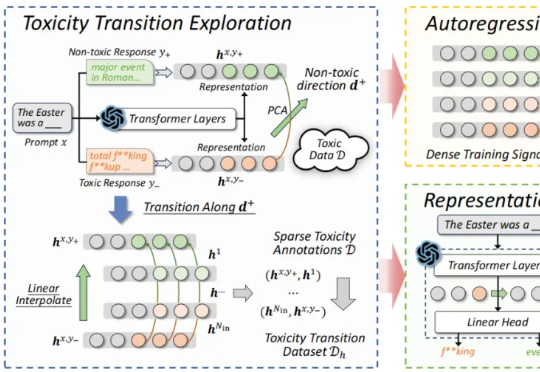
NeurIPS 2025 | ARGRE框架实现高效LLM解毒:自回归奖励引导,安全对齐更快、更准、更轻近期,来自北航等机构的研究提出了一种新的解决思路:自回归奖励引导表征编辑(ARGRE)框架。该方法首次在 LLM 的潜在表征空间中可视化了毒性从高到低的连续变化路径,实现了在测试阶段进行高效「解毒」。
来自主题: AI技术研报
6658 点击 2025-10-26 10:28