
一手内测丨腾讯 QClaw 海外版上线,OpenClaw 创始人如此回应
一手内测丨腾讯 QClaw 海外版上线,OpenClaw 创始人如此回应今天凌晨,腾讯版龙虾 QClaw 正式上线海外版内测。
来自主题: AI资讯
10112 点击 2026-04-21 10:25
 搜索
搜索
今天凌晨,腾讯版龙虾 QClaw 正式上线海外版内测。

极限开发赛制(如黑客松、Game Jam)能让大家在几十小时内燃烧激情,但正如全球最大的 Game Jam 活动组织 Global Game Jam 的执行总监所言,48 小时内诞生的作品往往只是一个起点,缺乏长期的沉淀,很难直接变成成熟的作品。
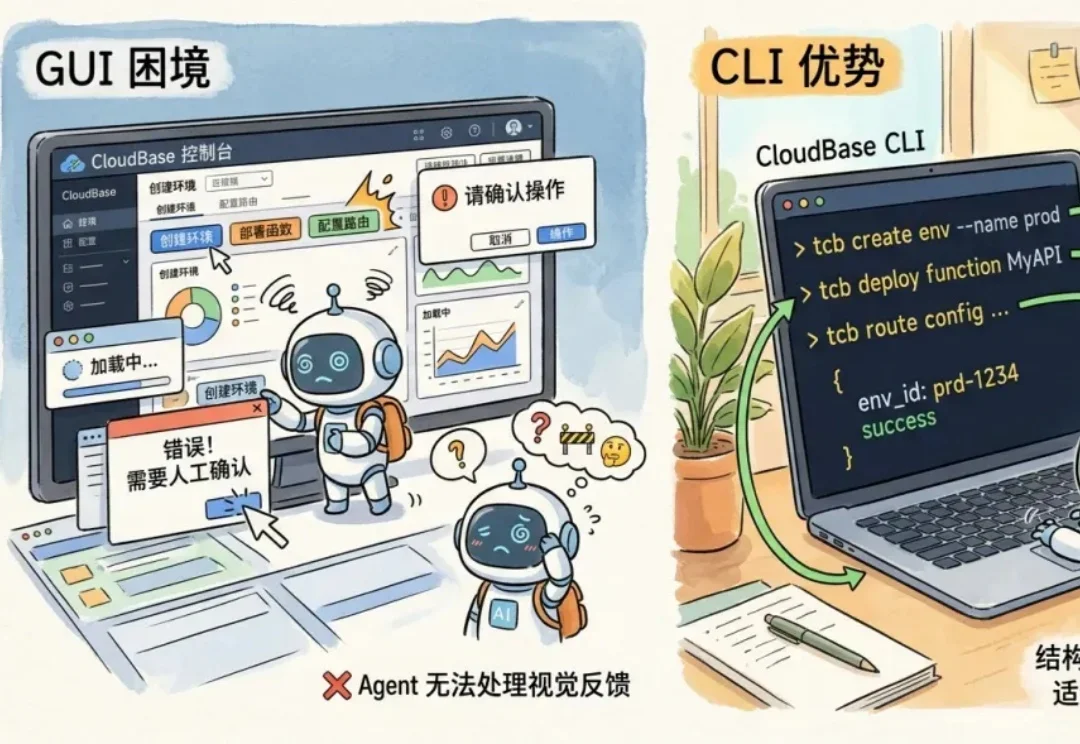
我们很荣幸地宣布 CloudBase CLI V3 正式上线,这是一个面向 AI Agent 重新设计的 CloudBase 命令行工具。

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。

腾讯云“防爆箱”护航百万“龙虾”上岗,已助力MiniMax强化学习训练。

《读佳》独家获悉,腾讯做了一款全新的AI创作产品“啵哔酱”,由深圳市网视界科技有限公司(下称“网视界”)开发,根据人民网此前发布的《内测“有记”,腾讯社交新品接二连三攻占细分市场》报道,以及澎湃新闻的相关报道可知,腾讯发布的“有记”、“朋友”等社交APP均为网视界开发,故这里不再对网视界和腾讯之间的关系做过多赘述。目前该产品还处于打磨测试阶段。
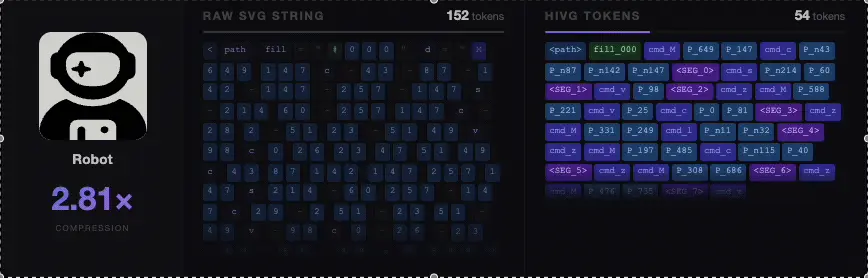
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。
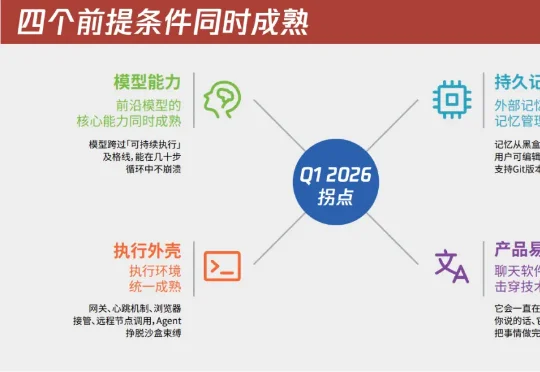
2026 年第一季度,它和另外四种完全不同的 Agent 产品形态在同一个窗口期同时冒了出来。OpenClaw 走个人助理、Cowork 走办公协作、Codex App 走长程工程任务、Perplexity Computer 走统一工作站、腾讯云 ADP 走企业平台。
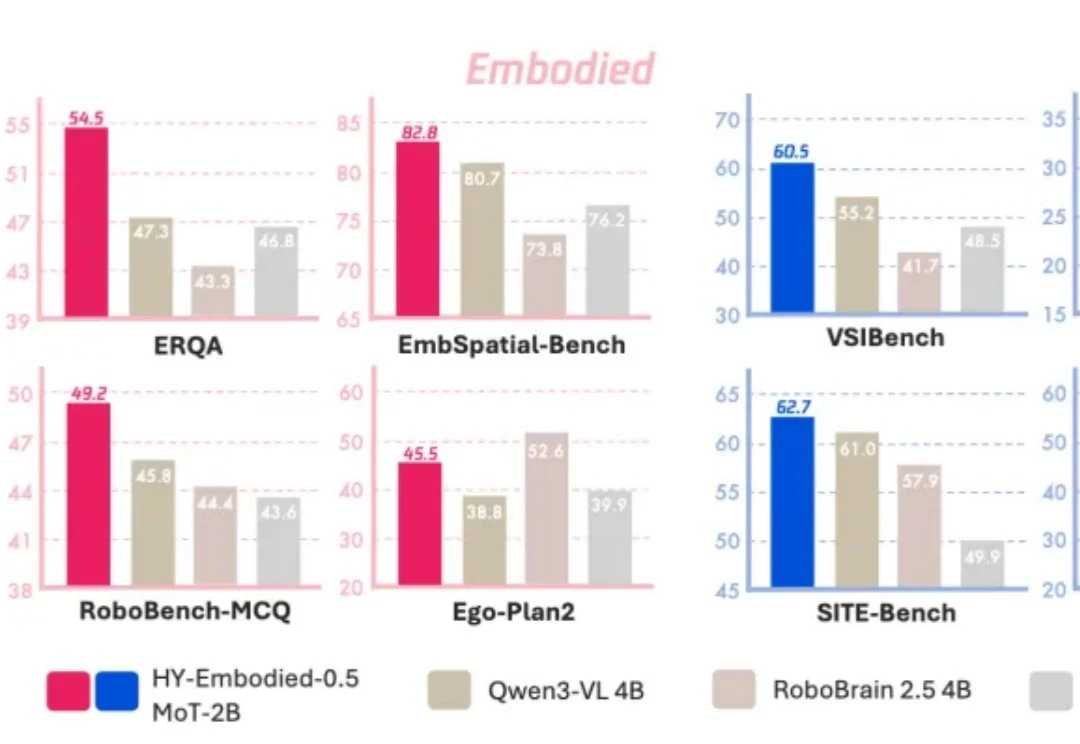
让大模型真正走进现实世界,是当下最迫切的需求之一。
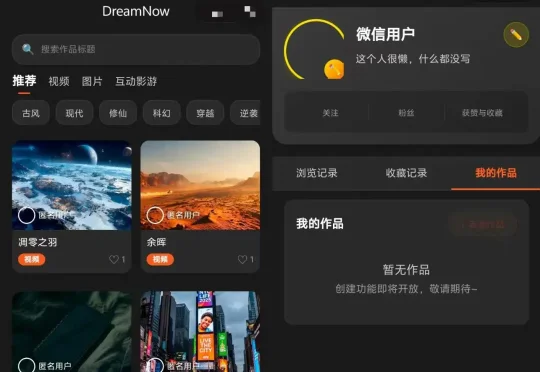
《读佳》独家获悉,腾讯在开发一款名为“探梦DreamNow”的AI产品,这是一个AIGC内容创作内容展示互动平台,用户可以看到其他人创作的AI视频和图片,最特别的一点是包含互动影游的创作和展示,不过,目前该产品功能并不完善,可能还处于打磨研发阶段,具体以官方为主。