
独家丨Kimi 完成 5 亿美元新融资,杨植麟:账上有超百亿元人民币
独家丨Kimi 完成 5 亿美元新融资,杨植麟:账上有超百亿元人民币独家获悉,月之暗面(Kimi)近期完成 5 亿美元 C 轮融资,IDG 领投 1.5 亿美元,阿里、腾讯、王慧文等老股东超额认购,投后估值 43 亿美元。据了解,王慧文已经累计投资月之暗面 7000 万美元。
来自主题: AI资讯
9124 点击 2025-12-31 17:11
 搜索
搜索
独家获悉,月之暗面(Kimi)近期完成 5 亿美元 C 轮融资,IDG 领投 1.5 亿美元,阿里、腾讯、王慧文等老股东超额认购,投后估值 43 亿美元。据了解,王慧文已经累计投资月之暗面 7000 万美元。

借势Agent浪潮,实时数据企业走上港股舞台。
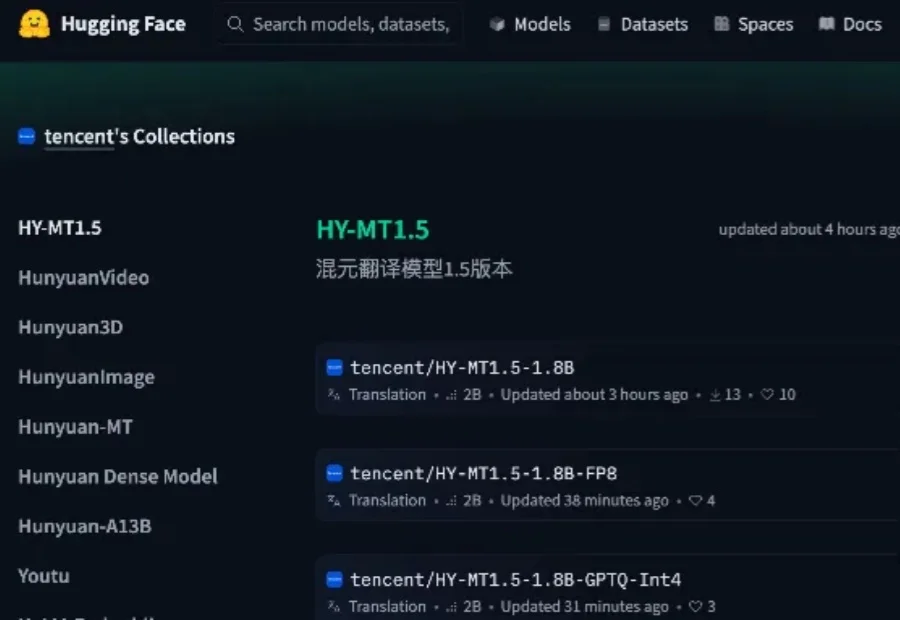
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。

组织调整后的模型答卷,将对腾讯至关重要。《智能涌现》从多名独立信源处获悉,近日,出于个人发展原因,原腾讯 AI Lab副主任俞栋将从腾讯离职。截至发稿前,腾讯官方暂未回复。
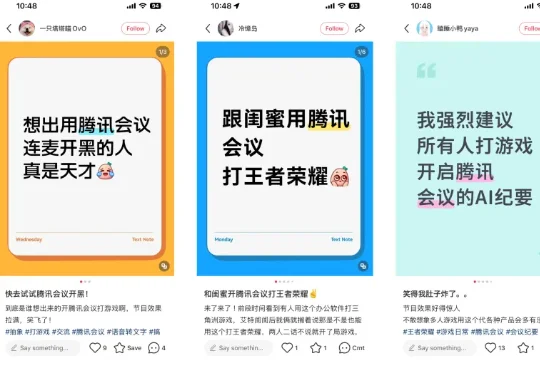
用腾讯会议打王者,谁看到不会说一句「离谱」。 以前在群里看到在线会议那串链接,条件反射就是工作和学习。我脑子里都是上课、开会、面试还有永无止境的「收到请扣 1」。 但最近我发现,这软件的风评正在发生一

在国内,懂技术 —— 尤其是 AI 技术的年轻人,真的不缺崭露头角的机会。

毋庸置疑!2025年title属于「Agent元年」。

在多智能体系统的想象中,我们常常看到这样一幅图景: 多个 AI 智能体分工协作、彼此配合,像一个高效团队一样攻克复杂任务,展现出超越单体智能的 “集体智慧”。
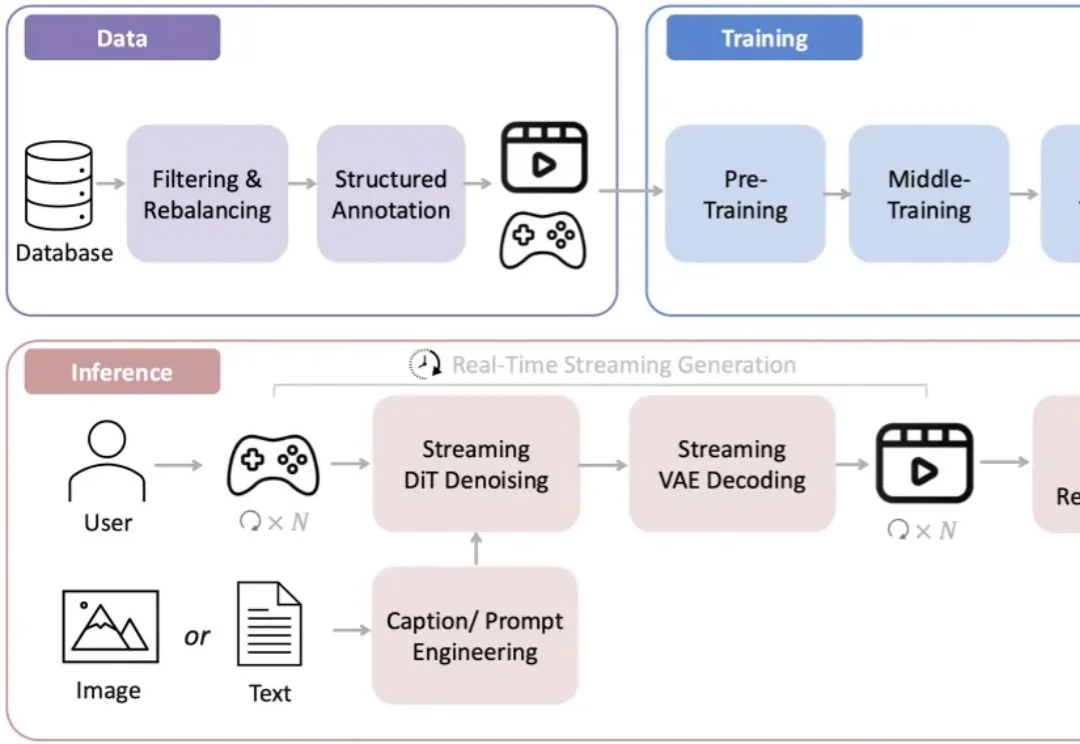
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。

2025年年初,一场常规的业务沟通会,在腾讯新闻负责人何毅进的引导下画风突变。他把这场全员会开成一场“AI焦虑吐槽大会”。