
Void IDE,Cursor 的开源替代品,发布测试版
Void IDE,Cursor 的开源替代品,发布测试版最近,一款新的开源 AI 驱动的代码编辑器 Void IDE发布了测试版,它将自己定位为一个注重隐私且免费的替代品,与流行的闭源 AI 编辑器如 Cursor 和 GitHub Copilot 竞争。
来自主题: AI资讯
8048 点击 2025-06-30 16:07
 搜索
搜索
最近,一款新的开源 AI 驱动的代码编辑器 Void IDE发布了测试版,它将自己定位为一个注重隐私且免费的替代品,与流行的闭源 AI 编辑器如 Cursor 和 GitHub Copilot 竞争。
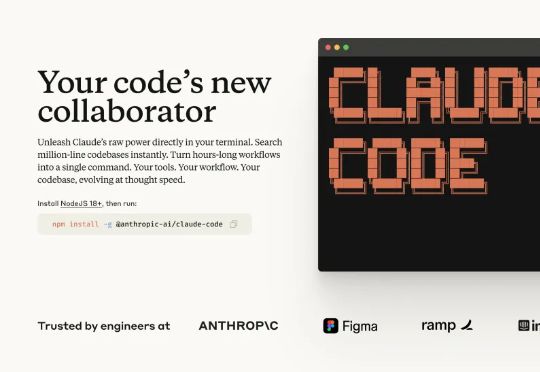
在经过深度思考后,我有了一个大胆的猜想:我们一直在用错误的框架理解它,大家都把它当作"更好的编程工具",但我越用越觉得,这根本不是一个编程工具,而是一个披着终端外衣的通用 AI agent。正好周末看了Anthropic 产品负责人 Michael Gerstenhaber 的最新一期访谈,

这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
2025年,10000个AI coding工具正在井喷。这是一个注定作为“AI Coding元年”载入技术史册的年份。 一批创新工具正以前所未有的方式重塑编程范式。
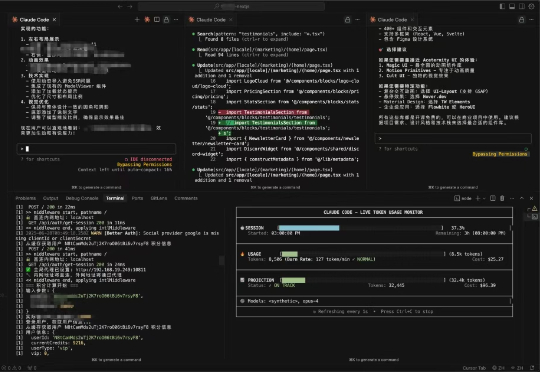
使用Claude Code有一段时间了,越用越香。我现在的主力编程工具组合是Cursor + Claude Code。 同时,我也推荐AugmentCode + Claude Code的组合形式
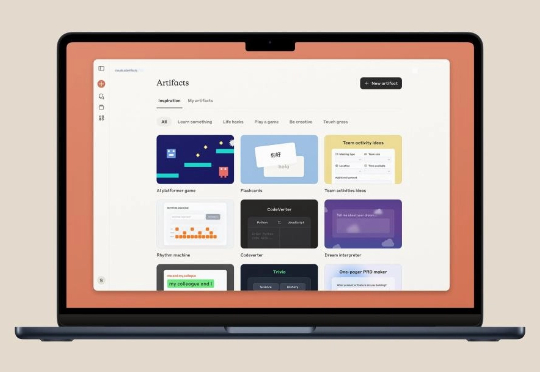
Anthropic 让每一位 Claude 用户都成为无代码 App 开发人员。美国当地时间 6 月 26 日,Anthropic 刚刚升级了一项重要工具 Artifacts,让构建交互式 AI 工具变得更加轻松。这项功能对于普通用户来说意义非凡,因为无需任何编程技能。

带着最新最强的模型,走向最热门的赛道,这用来形容 Google 昨天推出的 Gemini CLI 最合适不过了。
前天分享了一篇介绍Gemini CLI的文章《谷歌杀疯了!免费2.5 Pro+开源Gemini CLI,就是要卷死所有AI编程工具..》 没想到还有点小火...这篇文章,我带大家来解决一下这个登录不上的问题。另外,Gemini CLI的Github上提的问题太多了。。。目前已经有516个Issues

让AI编程助手成为更可靠的开发伙伴

91岁退休多年的John Blackman从未碰过代码,却在孙子指点下用AI工具,仅用两天搭出多租户管理系统。