
代码定位太慢?蚂蚁ACL2026新作:FuseSearch-4B让模型自己学会「该搜多少」
代码定位太慢?蚂蚁ACL2026新作:FuseSearch-4B让模型自己学会「该搜多少」新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴
来自主题: AI技术研报
6259 点击 2026-06-15 14:20
 搜索
搜索
新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。

一颗土豆,表皮上爬满发光电路,焦黄的皮和银色走线贴在一起,像是英伟达和肯德基联名了。 标题端端正正:Potato Chip Tech Summit——一颗土豆如何颠覆半导体行业。 这是我们给 AI 出
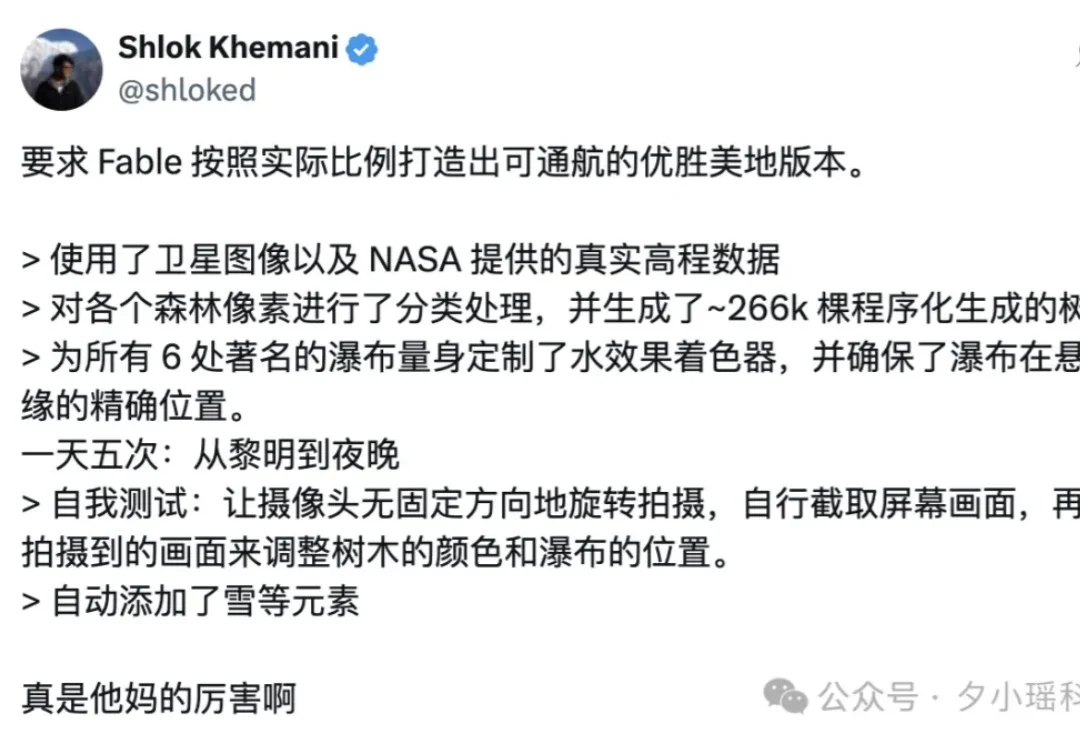
AI编程的天花板,又被Claude Fable 5 抬高了。
除此之外,context-mode 将大模型的记忆力从30分钟提升至 3 小时。
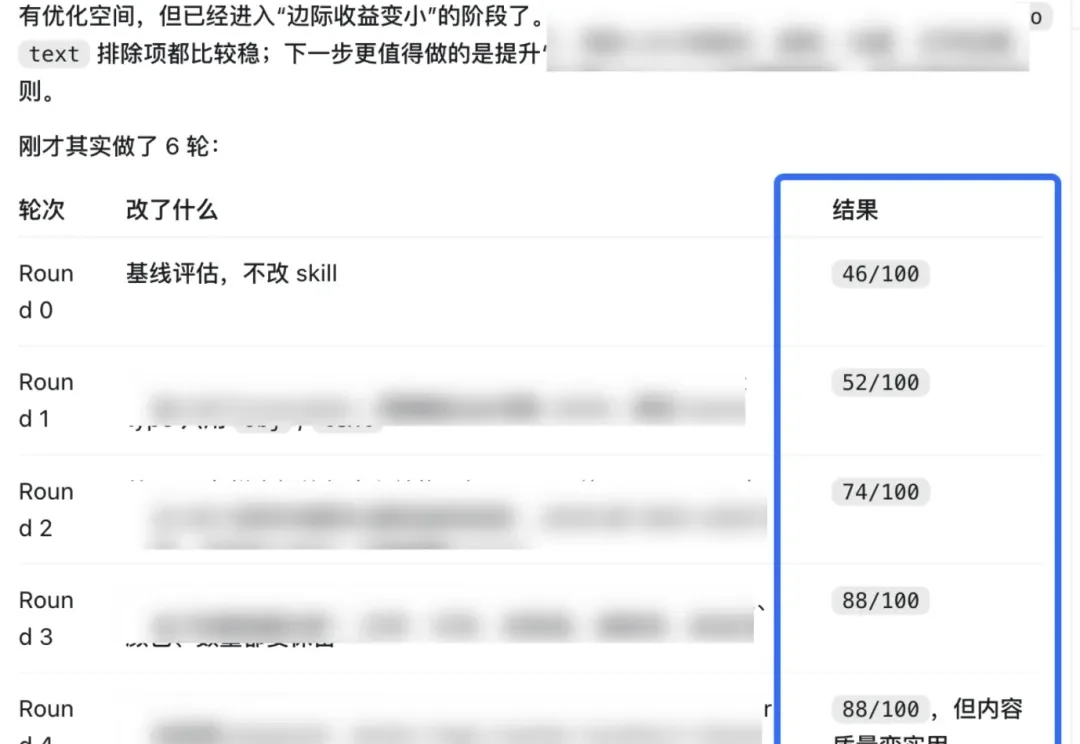
前几天我们讨论过一个观点:自从2026年Q2起,未来人类所谓的“编程工作”其实比拼的是「谁能一次性把“什么叫完成”定义清楚」

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?

《读佳》从读者处获悉:我们此前独家曝光的蚂蚁集团新产品Qmuse已经上线,并开始内测,目前支付宝账号是唯一登录方式。该产品由蚂蚁数智信息技术(上海)有限公司(下称“蚂蚁数智”)所有及运营。

我们刚办完的网吧黑客松,哪都好,只有一点不好:网吧禁止未成年人入内。

如果你接触过“氛围编程”(Vibe coding)、开发过 AI 应用,或许会对 Supabase 的名字感到熟悉。它是全球无数独立开发者最信赖的默认后端之一,也在最近一年里,成了资本热捧的开源巨头。