仅0.2B就比GPT-4.1强?加州大学新指标:组合推理基准首次超越人类
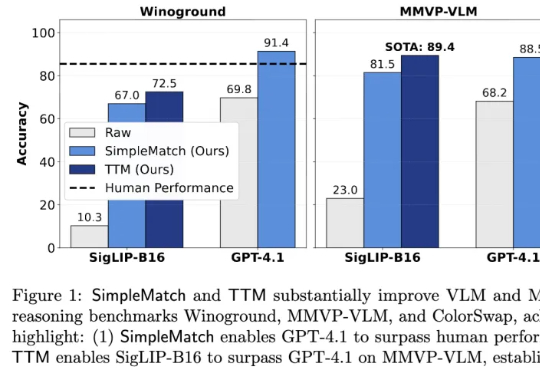
仅0.2B就比GPT-4.1强?加州大学新指标:组合推理基准首次超越人类加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。
来自主题: AI技术研报
8093 点击 2025-11-09 15:33