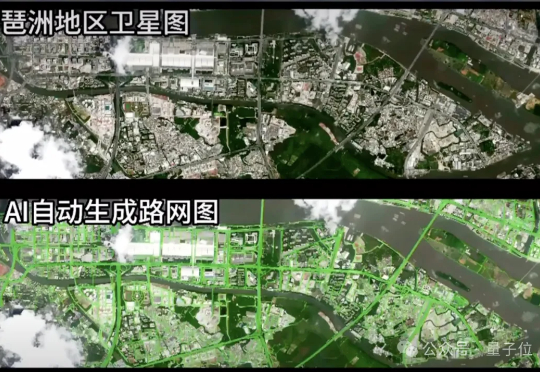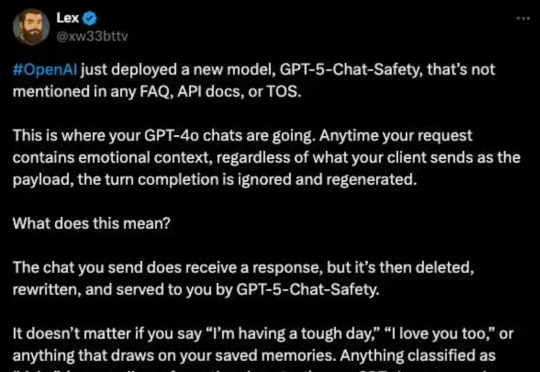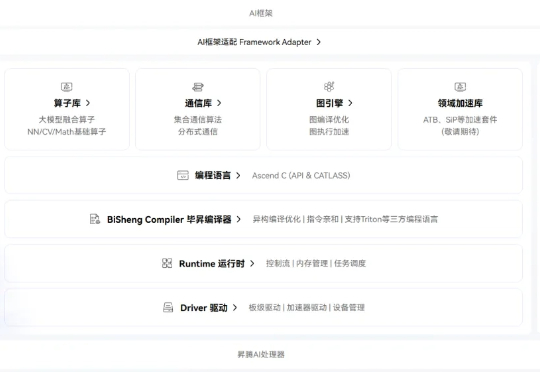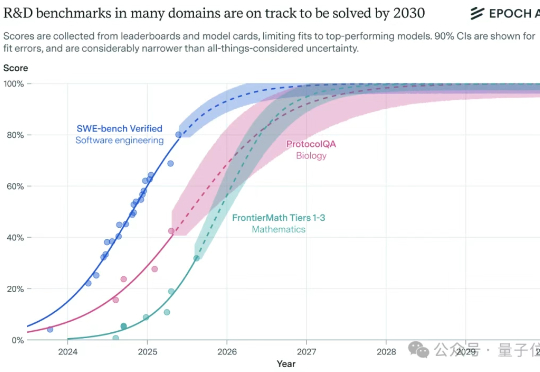
OpenAI入股AMD,股价暴涨35%!奥特曼左手黄仁勋,右手苏姿丰,通吃全球算力
OpenAI入股AMD,股价暴涨35%!奥特曼左手黄仁勋,右手苏姿丰,通吃全球算力OpenAI宣布与AMD达成战略合作,将共同部署高达6GW的AMD Instinct MI450 GPU集群,首批1GW预计于2026年下半年启用。作为协议的一部分,OpenAI可认购最多1.6亿股AMD普通股,持股比例或达10%。消息公布后,AMD盘前股价飙升35%!
来自主题: AI资讯
10289 点击 2025-10-06 22:02