
DeepMind创始人最新专访:AGI或5年内实现,规模是工业革命10倍,上一波思想已被“榨干”
DeepMind创始人最新专访:AGI或5年内实现,规模是工业革命10倍,上一波思想已被“榨干”五年内实现AGI,算力是最大瓶颈。
来自主题: AI资讯
9473 点击 2026-04-10 08:36
 搜索
搜索
五年内实现AGI,算力是最大瓶颈。

黄仁勋用「五层蛋糕」讲清了AI全栈生态的分层逻辑,易鑫则把它翻译成汽车金融的落地打法:从算力、模型到Agent落地,解决的全是汽车金融最难的活。
刚刚,Anthropic年收入首超OpenAI!同时就在今天,一份与谷歌、博通最新合作,将在2027年上线3.5 GW全新TPU集群。这批史诗级的算力,预计从2027年开始陆续上线。

没有仿真,没有预设参数,也没有剪辑空间。

当近期的注意力都被中美吸引的时候,身在欧洲的它又把我拉了回去…

全世界都在等ASI降临,OpenAI却在年初悄悄上线广告位。9亿用户撑不起数百亿美元的算力账单,智力正在贬值,神仙也得下凡赚钱!

代码没有消失,但它不再是少数人特权。在「创造平权」的AI时代,真正稀缺的不再是编程能力,而是你是否有一个值得让机器为你燃烧几百美元算力的好想法。

为超节点规模化落地解决异构协同难、跨域调度效率低等核心痛点。
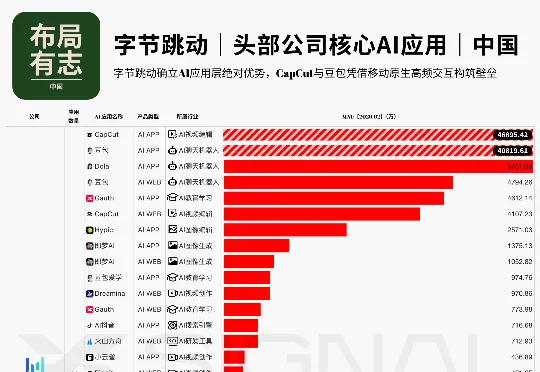
大模型的狂热已然退潮。当我们将目光从参数榜单转向真实的活跃数据,四家头部大厂的底层商业图谱已极度收敛。AI的竞争,早已变成一场基于算力成本与高频场景的残酷算账。

三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!