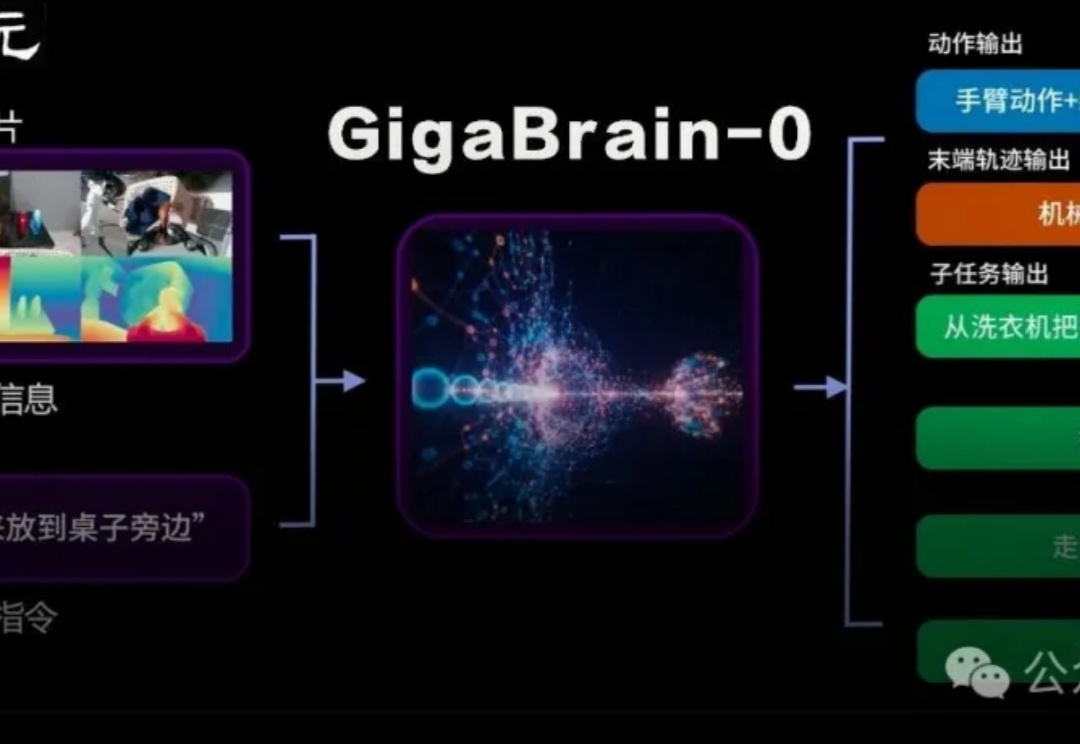
刚刚,最佳VLA模型GigaBrain-0开源:世界模型驱动10倍数据,真机碾压SOTA
刚刚,最佳VLA模型GigaBrain-0开源:世界模型驱动10倍数据,真机碾压SOTA国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。
来自主题: AI技术研报
6392 点击 2025-10-29 18:14
 搜索
搜索
国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。
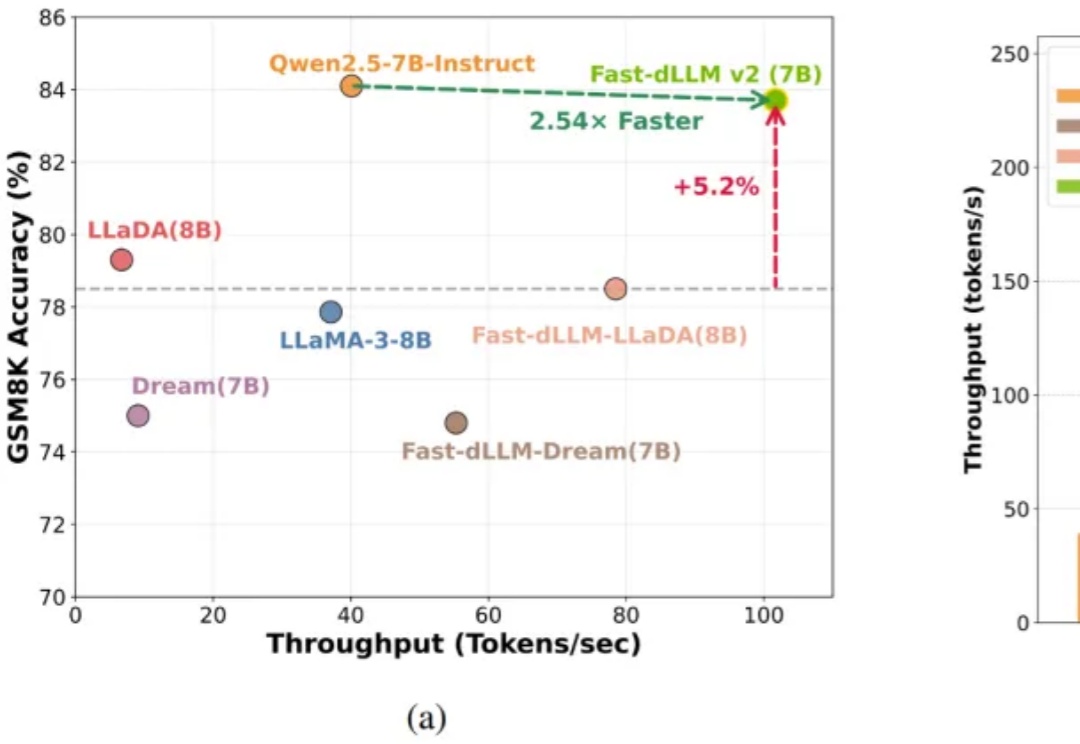
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
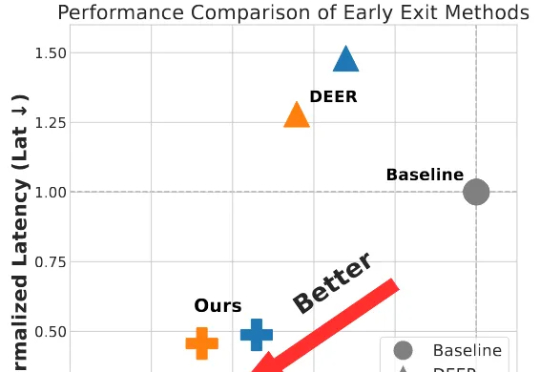
为破解大模型长思维链的效率难题,并且为了更好的端到端加速落地,我们将思考早停与投机采样无缝融合,提出了 SpecExit 方法,利用轻量级草稿模型预测 “退出信号”,在避免额外探测开销的同时将思维链长度缩短 66%,vLLM 上推理端到端加速 2.5 倍。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。
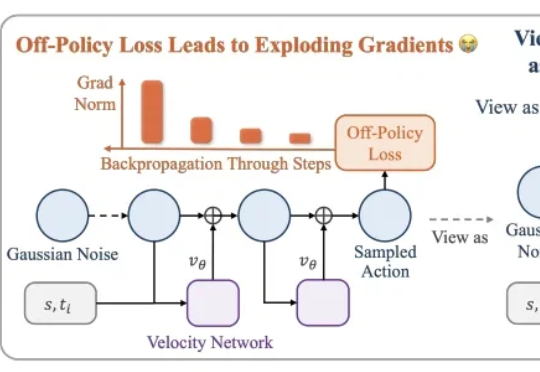
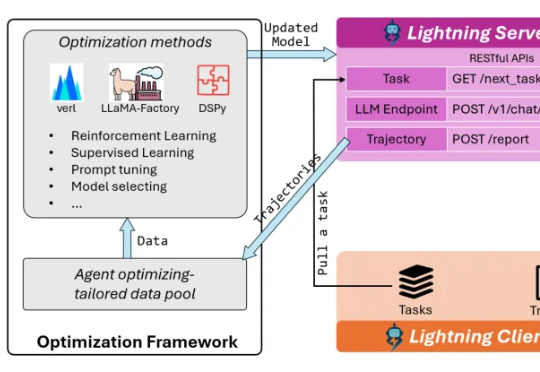
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。
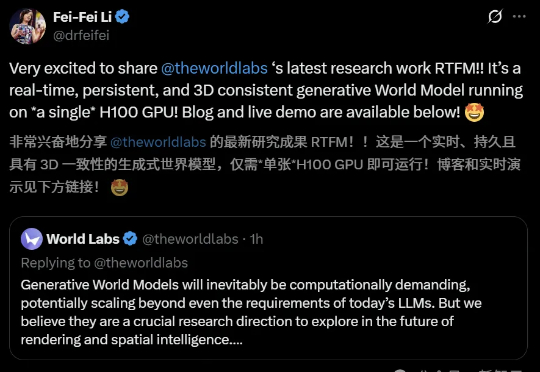
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。
AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。
写代码的规则,正在被悄悄改写!不再是「人+AI一起盯屏幕」,而是一次性放出十几个任务,让代理们各自跑。真正的门槛,也不再是你能写多少行代码,而是你能不能写清楚需求、明确地拆分任务、快速浏览结果。
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。